一、数组
- 求数组大小
nums.size()//防止报错- 数组中的按大小排序
sort(nums.begin(), nums.end());- 获取最大值/最小值
int nums[8] = {1,2,3,8,0,33,11,9};
int max_num = *max_element(nums, nums + 8);
int min_num = *min_element(nums, nums + 8);- 将数组a中的数值置为0
int a[m];
fill(a,a+m,0);二、函数
- 注意当返回两个以上值
return {i,j};
或
return {};- 返回数组时:
//从数组中获得初值
int b[7]={1,2,3,4,5,6,7};
vector<int> a(b,b+7);
return a;三、vector
- 初始化
//一维
//定义具有10个整型元素的向量(尖括号为元素类型名,它可以是任何合法的数据类型),不具有初值,其值不确定
vector<int> a(10);
//定义具有10个整型元素的向量,且给出的每个元素初值为1
vector<int> a(10,1);
//用向量b给向量a赋值,a的值完全等价于b的值
vector<int> a(b);
//将向量b中从0-2(共三个)的元素赋值给a,a的类型为int型
vector<int> a(b.begin(),b.begin+3);
//从数组中获得初值
int b[7]={1,2,3,4,5,6,7};
vector<int> a(b,b+7);
//二维
vector<vector<int> >a(r);//首先给array开辟了r个空间
for(int i = 0;i < r;i++){
a[i].resize(c);//给array中每个元素开辟了c个空间
}
ret.push_back(vector <int> ());//给二维数组ret增加一个一维空间
ret.back().push_back(node->val);//给二维数组ret最后一个空间增添元素,并将值设置为node->val2.常用内置函数
#include<vector>
//一维
vector<int> a,b;
//b为向量,将b的0-2个元素赋值给向量a
a.assign(b.begin(),b.begin()+3);
//a含有4个值为2的元素
a.assign(4,2);
//返回a的最后一个元素
a.back();
//返回a的第一个元素
a.front();
//返回a的第i元素,当且仅当a存在
a[i];
//清空a中的元素
a.clear();
//判断a是否为空,空则返回true,非空则返回false
a.empty();
//删除a向量的最后一个元素
a.pop_back();
//删除a中第一个(从第0个算起)到第二个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+3(不包括它)结束
a.erase(a.begin()+1,a.begin()+3);
//在a的最后一个向量后插入一个元素,其值为5
a.push_back(5);
//在a的第一个元素(从第0个算起)位置插入数值5,
a.insert(a.begin()+1,5);
//在a的第一个元素(从第0个算起)位置插入3个数,其值都为5
a.insert(a.begin()+1,3,5);
//b为数组,在a的第一个元素(从第0个元素算起)的位置插入b的第三个元素到第5个元素(不包括b+6)
a.insert(a.begin()+1,b+3,b+6);
//返回a中元素的个数
a.size();
//返回a在内存中总共可以容纳的元素个数
a.capacity();
//将a的现有元素个数调整至10个,多则删,少则补,其值随机
a.resize(10);
//将a的现有元素个数调整至10个,多则删,少则补,其值为2
a.resize(10,2);
//将a的容量扩充至100,
a.reserve(100);
//b为向量,将a中的元素和b中的元素整体交换
a.swap(b);
//b为向量,向量的比较操作还有 != >= > <= <
a==b;
//二维
int k = mat.size() * mat[0].size();
//mat.size()为mat中元素的个数,mat[0].size()为mat中每个元素的大小3.常用算法
#include<algorithm>
vector<int> nums = {1,2,3,8,0,33,11,9};
int max_num = *max_element(nums.begin(), nums.end());//获取最大值
int min_num = *min_element(nums.begin(), nums.end());//获取最小值
sort(a.begin(),a.end());//对a中的从a.begin()(包括它)到a.end()(不包括它)的元素进行从小到大排列
reverse(a.begin(),a.end());//对a中的从a.begin()(包括它)到a.end()(不包括它)的元素倒置,但不排列,如a中元素为1,3,2,4,倒置后为4,2,3,1
copy(a.begin(),a.end(),b.begin()+1);//把a中的从a.begin()(包括它)到a.end()(不包括它)的元素复制到b中,从b.begin()+1的位置(包括它)开始复制,覆盖掉原有元素
find(a.begin(),a.end(),10);//在a中的从a.begin()(包括它)到a.end()(不包括它)的元素中查找10,若存在返回其在向量中的位置
fill(matrix[i].begin(),matrix[i].end(),0);//将二维数组matrix第i行的所有数值置为04.常用向向量添加元素的方式
//直接添加
vector<int> a;
for(int i=0;i<10;++i){a.push_back(i);}
//从数组中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
for(int i=0;i<=4;++i){b.push_back(a[i]);}
//从现有向量中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
vector<int> c(a,a+4);
for(vector<int>::iterator it=c.begin();it<c.end();++it)
{
b.push_back(*it);
}
//从文件中读取元素向向量中添加
ifstream in("data.txt");
vector<int> a;
for(int i;in>>i){a.push_back(i);}
//常见错误赋值方式
vector<int> a;
for(int i=0;i<10;++i){a[i]=i;}//下标只能用来获取已经存在的元素5.从向量中读取元素
//通过下标方式获取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(int i=0;i<=b.size()-1;++i){cout<<b[i]<<endl;}
//通过迭代器方式读取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(vector<int>::iterator it=b.begin();it!=b.end();it++){cout<<*it<<" ";}四、字符
1.遍历从字母'a'到字母'z'
for(char i = 'a';i <= 'z';i++){
}2.string
//初始化
string s1;
string s2 = s1;//string s2(s1);
string s3 = "value";//string s3("value");
string s4(4, "c");//string s4 = "cccc";
//insert
string s1("value");
s1.insert(s1.begin(), 's');//执行后,s1为"svalue"
s1.insert(s1.end(), {'1','2'});//执行后,s1为"svalue12"五、unordered_map
unordered_map<char, int> umap;//创建,前者为key,后者为value
for (char ch:s) {//s为一维string数组
++umap[ch];
}
unordered_map<char, char> pairs = { //建立一个哈希表,第一个char为key,第二个char为value
{')', '('}, //哈希表映射的右括号为键,左括号为值
{']', '['},
{'}', '{'}
};
//map中查找key值x是否存在
umap.count(x) != 0六、队列
1.初始化
//queue<Type,Container> (<数据类型,容器类型>)
//初始化时必须要有数据类型,容器可省略,省略时则默认为deque类型
queue<int> q1;
queue<double> q2;
queue<char> q3;
queue<pair<char,int>> q4;
queue<char,list<char>> q1;//用list容器实现的queue
queue<int,deque<int>> q2;//用deque容器实现的queue 2.常用函数
q.push("first");//在队尾插入一个元素
q.pop();//删除队列第一个元素,没有返回值
q.size();//返回队列中元素个数
q.empty();//如果队列空则返回true
q.front();//返回队列中的第一个元素
q.back();//返回队列中最后一个元素3.注意事项
(1)若for循环条件语句用到qure.size(),且for循环内部代码有qure.pop()操作时,要把qure.size()单独拿出来赋给变量,将for循环执行之前的值存储下来,再将这一值运用到for循环的条件语句中。
//错误
for(int i = 0;i < qure.size();i++){
int re = qure.front();
qure.pop();
}
//正确
int size = qure.size();
for(int i = 0;i < size;i++){
int re = qure.front();
qure.pop();
}七、链表
//定义
struct ListNode {
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};
//初始化
ListNode* head = new ListNode(5); //使用上述定义中的构造函数来初始化
ListNode* head = new ListNode(); //使用c++默认构造函数来初始化
head -> val = 5;
//调用
int a = head -> val;
ListNode* temp = head;
ListNode* temp = head -> next;
if (head == nullptr || head->next == nullptr) {//不是空链表且有后续节点
return false;
}
//用unordered_set来区分链表每个节点
bool hasCycle(ListNode *head) {
unordered_set<ListNode*> seen;
while (head != nullptr) {
if (seen.count(head)) {
return true;
}
seen.insert(head);
head = head->next;
}
return false;
}
//两个链表节点可以直接相比较是否相等
ListNode* slow = head;
ListNode* fast = head->next;
while (slow != fast) {
}八、const
const名叫常量限定符,用来限定特定变量,以通知编译器该变量是不可修改的。习惯性的使用const,可以避免在函数中对某些不应修改的变量造成可能的改动。
1.const修饰一般常量及数组
int const a = 100;
const int a = 100; //与上面等价
int const arr [3] = {1,2,3};
const int arr [3] = {1,2,3};//与上面等价2.const修饰指针(*)
2.1常量指针(值为常量)
const用来修饰指针所指向的变量,即指针指向为常量;
当为常量指针时,不可以通过修改所指向的变量的值,但是指针可以指向别的变量。
int a = 5;
const int *p =&a;
*p = 20; //error 不可以通过修改所指向的变量的值
int b =20;
p = &b; //right 指针可以指向别的变量2.2指针常量(指针为常量)
const修饰指针本身,即指针本身是常量。
当为指针常量时,指针不能指向别的变量,但是可以通过指针修改它所指向的变量的值。
int a = 5;
int *const p = &a;
*p = 20; //right 可以修改所指向变量的值
int b = 10;
p = &b; //error 不可以指向别的变量左定值,右定向,const修饰不变量
3.修饰函数
3.1修饰函数形参
函数体内不能修改形参a的值。
3.1.1形参为指针
void StringCopy(char* strDest, const char* strSource);形参指针加上const 修饰之后,保护了这一块内存地址不被修改,如果刻意修改这一块内存,编译器会报错。
九、栈
//定义
stack<int> s;
stack<char> stk;
//常用内置函数
s.empty(); //如果栈为空则返回true, 否则返回false;
s.size(); //返回栈中元素的个数
s.top(); //返回栈顶元素, 但不删除该元素
s.pop(); //弹出栈顶元素, 但不返回其值
s.push(); //将元素压入栈顶十、树
- 前序遍历
前序遍历首先访问根结点然后遍历左子树,最后遍历右子树。在遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树。
若二叉树为空则结束返回,否则:
(1)访问根结点。
(2)前序遍历左子树。
(3)前序遍历右子树 。
需要注意的是:遍历左右子树时仍然采用前序遍历方法。
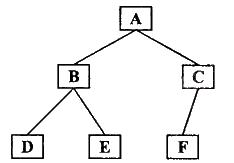
如图所示二叉树
前序遍历结果:ABDECF
//递归算法
class Solution {
public:
void preorder(TreeNode *root, vector<int> &res) {
if (root == nullptr) {
return;
}
res.push_back(root->val);
preorder(root->left, res);
preorder(root->right, res);
}
vector<int> preorderTraversal(TreeNode *root) {
vector<int> res;
preorder(root, res);
return res;
}
};2.中序遍历
首先遍历左子树,然后访问根结点,最后遍历右子树。
3.后序遍历
在二叉树中,先左后右再根,即首先遍历左子树,然后遍历右子树,最后访问根结点。
4.层序遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector <vector <int>> ret;
if (!root) {
return ret;
}
queue <TreeNode*> q;
q.push(root);
while (!q.empty()) {
int currentLevelSize = q.size();
ret.push_back(vector <int> ());
for (int i = 1; i <= currentLevelSize; ++i) {
auto node = q.front();
q.pop();
ret.back().push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
return ret;
}
};5.树的最大深度
//深度优先搜索
//如果我们知道了左子树和右子树的最大深度l和r,那么该二叉树的最大深度即为
//max(l,r)+1
//而左子树和右子树的最大深度又可以以同样的方式进行计算。
class Solution {
public:
int maxDepth(TreeNode* root) {
if (root == nullptr) return 0;
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};十一、位运算
00001100 - b
00110000 - b << 2 (左移两位)
00000011 - b >> 2 (右移两位)
//让n与2^i相与
if (n & (1 << i)) {
ret++;
}