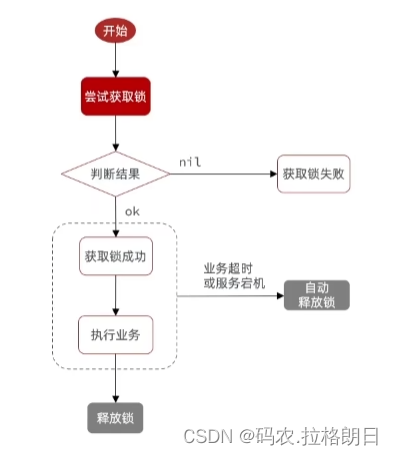
1. 分布式锁基本原理
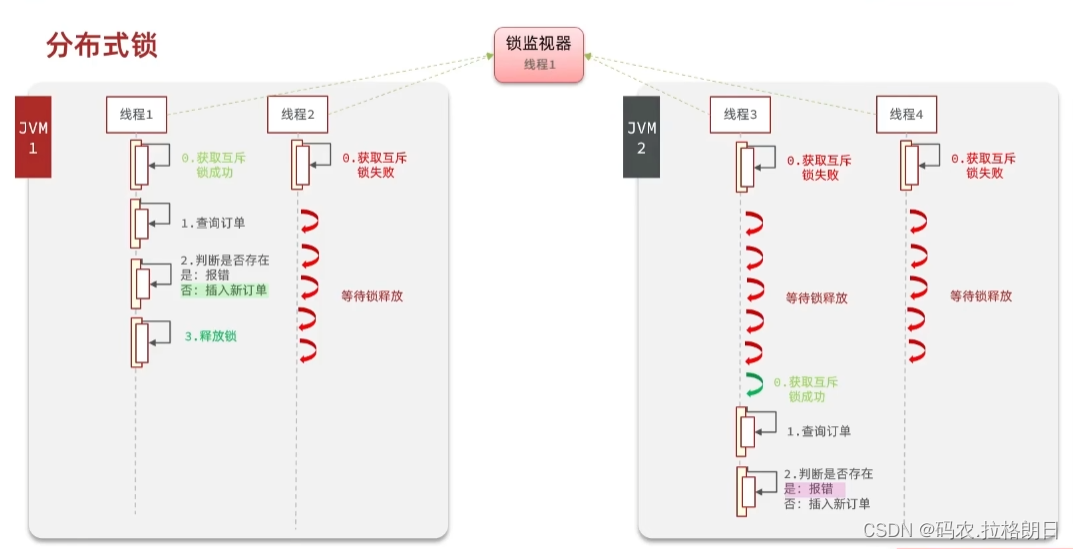

基于数据库的分布式锁:这种方式使用数据库的特性来实现分布式锁。具体流程如下:
- 获取锁:当一个节点需要获得锁时,它尝试在数据库中插入一个特定的唯一键值(如唯一约束的主键),如果插入成功,则表示获得了锁。
- 释放锁:当节点完成任务后,通过删除该唯一键值来释放锁。
这种实现方式基于数据库的事务特性,可以保证原子性和可靠性。但需要注意避免死锁和锁超时等问题,并设置合适的锁过期时间以防止节点异常导致的死锁。
基于缓存的分布式锁:这种方式使用分布式缓存来实现分布式锁。具体流程如下:
- 获取锁:当一个节点需要获得锁时,它尝试在缓存中设置一个特定的键值对,如果设置成功,则表示获得了锁。为了保证原子性,可以使用缓存的原子操作(如SETNX命令)。
- 释放锁:当节点完成任务后,通过删除该键值对来释放锁。
这种实现方式基于缓存的特性,如原子操作和过期时间设置,可以较好地支持分布式环境。但同样需要关注缓存失效或节点故障等情况,以避免由于锁的异常释放而导致的并发问题。
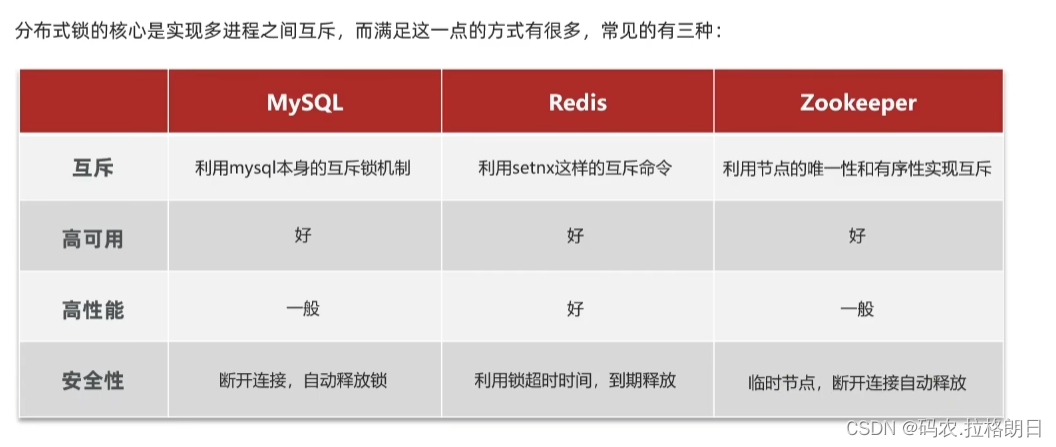
2. 基于Redis实现分布式锁思路

其中添加锁和设置锁过期时间应该具有原子性,避免两个操作之间服务器出现了宕机等问题;
示例代码:
key为lock、value为thread、EX 10 设置过期时间为10秒、NX是互斥等同于setnx
SET lock thread EX 10 NX