本文介绍基于Python语言,读取Excel表格文件数据,并基于其中某一列数据的值,将这一数据处于指定范围的那一行加以复制,并将所得结果保存为新的Excel表格文件的方法。
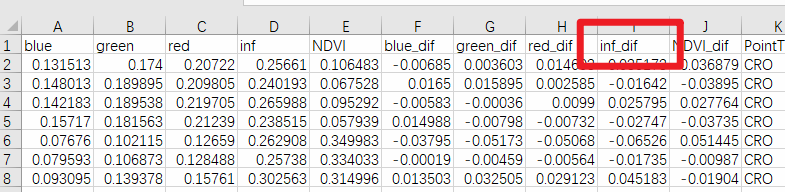
首先,我们来明确一下本文的具体需求。现有一个Excel表格文件,在本文中我们就以.csv格式的文件为例;其中,如下图所示,这一文件中有一列(也就是inf_dif这一列)数据比较关键,我们希望对这一列数据加以处理——对于每一行,如果这一行的这一列数据的值在指定的范围内,那么就将这一行复制一下(相当于新生成一个和当前行一摸一样数据的新行)。
知道了需求,我们就可以开始代码的书写。其中,本文用到的具体代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 6 22:04:48 2023
@author: fkxxgis
"""
import pandas as pd
df = pd.read_csv(r"E:\Train_Model.csv")
result_df = pd.DataFrame()
for index, row in df.iterrows():
value = row["inf_dif"]
if value <= -0.1 or value >= 0.1:
for i in range(10):
result_df = result_df.append(row, ignore_index=True)
result_df = result_df.append(row, ignore_index=True)
result_df.to_csv(r"E:\Train_Model_Oversampling_NIR_10.csv", index=False)
其中,上述代码的具体介绍如下。
首先,我们需要导入所需的库;接下来,我们使用pd.read_csv()函数,读取我们需要加以处理的文件,并随后将其中的数据存储在名为df的DataFrame格式变量中。接下来,我们再创建一个空的DataFrame,名为result_df,用于存储处理后的数据。
随后,我们使用df.iterrows()遍历原始数据的每一行,其中index表示行索引,row则是这一行具体的数据。接下来,获取每一行中inf_dif列的值,存储在变量value中。
此时,我们即可基于我们的实际需求,对变量value的数值加以判断;在我这里,如果value的值小于等于-0.1或大于等于0.1,则就开始对这一行加以复制;因为我这里需要复制的次数比较多,因此就使用range(10)循环,将当前行数据复制10次;复制的具体方法是,使用result_df.append()函数,将复制的行添加到result_df中。
最后,还需要注意使用result_df.append()函数,将原始行数据添加到result_df中(这样相当于对于我们需要的行,其自身再加上我们刚刚复制的那10次,一共有11行了)。
在最后一个步骤,我们使用result_df.to_csv()函数,将处理之后的结果数据保存为一个新的Excel表格文件文件,并设置index=False,表示不保存行索引。
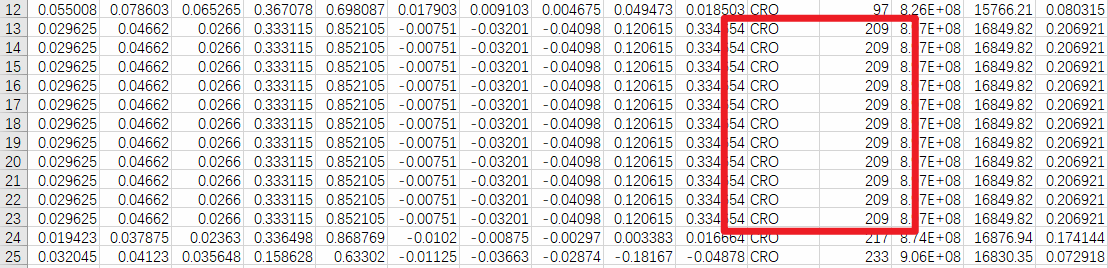
运行上述代码,我们即可得到结果文件。如下图所示,可以看到结果文件中,符合我们要求的行,已经复制了10次,也就是一共出现了11次。
至此,大功告成。
欢迎关注:疯狂学习GIS