字符串处理只能在Series上进行,不可以在DataFrame上操作,只能对字符串进行处理,不能对整数、日期进行处理
1. 元素统计
1.1 str.count()
1.1.1 函数功能
统计Series中每个元素中包含pat的次数
1.1.2 函数语法
Series.str.count(pat, flags=0)
1.1.3 函数参数
| 参数 | 含义 |
|---|---|
| pat | 表达式 |
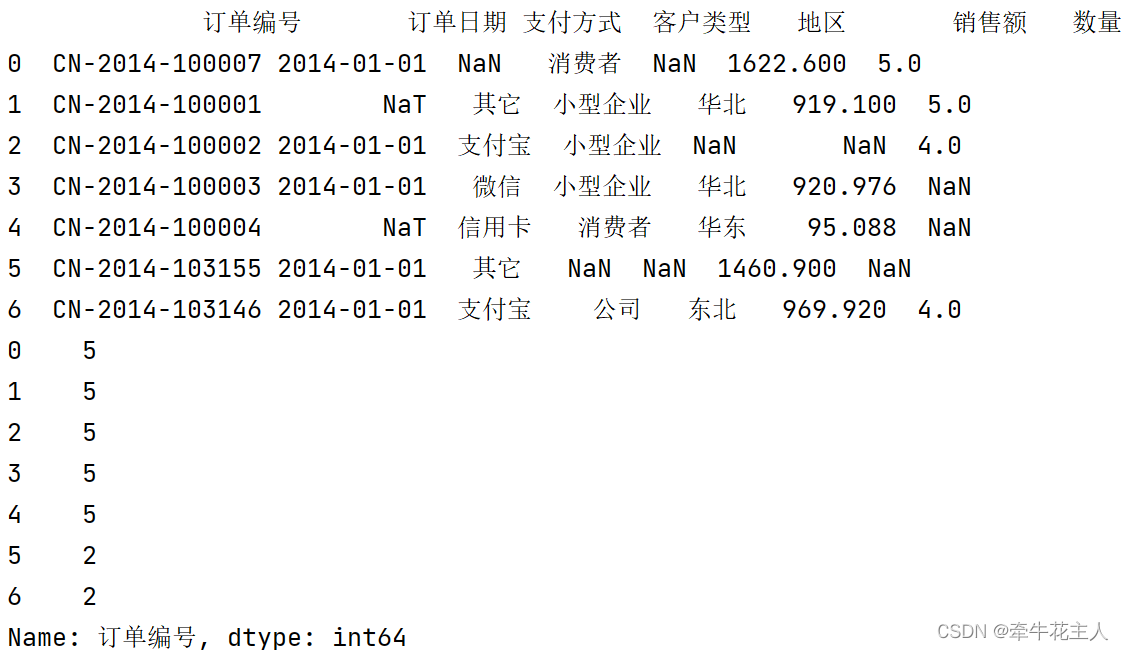
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order)
print(order['订单编号'].str.count(pat='0'))
1.2 str.len()
1.2.1 函数功能
统计Series中每个元素的长度
1.2.2 函数语法
Series.str.len()
print(order['支付方式'].str.len())

2. 字符串内容判断
2.1 str.contains()
2.1.1 函数功能
检测Series或Index的每个元素中是否包含指定内容,返回结果为布尔值构成的Series或Index
2.1.2 函数语法
Series.str.contains(pat, case=True, flags=0, na=None, regex=True)
2.1.3 函数参数
| 参数 | 含义 |
|---|---|
| pat | 要查找的内容 |
| case | 布尔值,是否区分大小写,默认True:区分 |
| flags | 整数,默认值为0 |
| na | 标量,可选参数,对缺失值进行填充 |
| regex | 布尔值,默认值为True:以正则表达式看待pat中的内容,否则以普通字符串看待 |
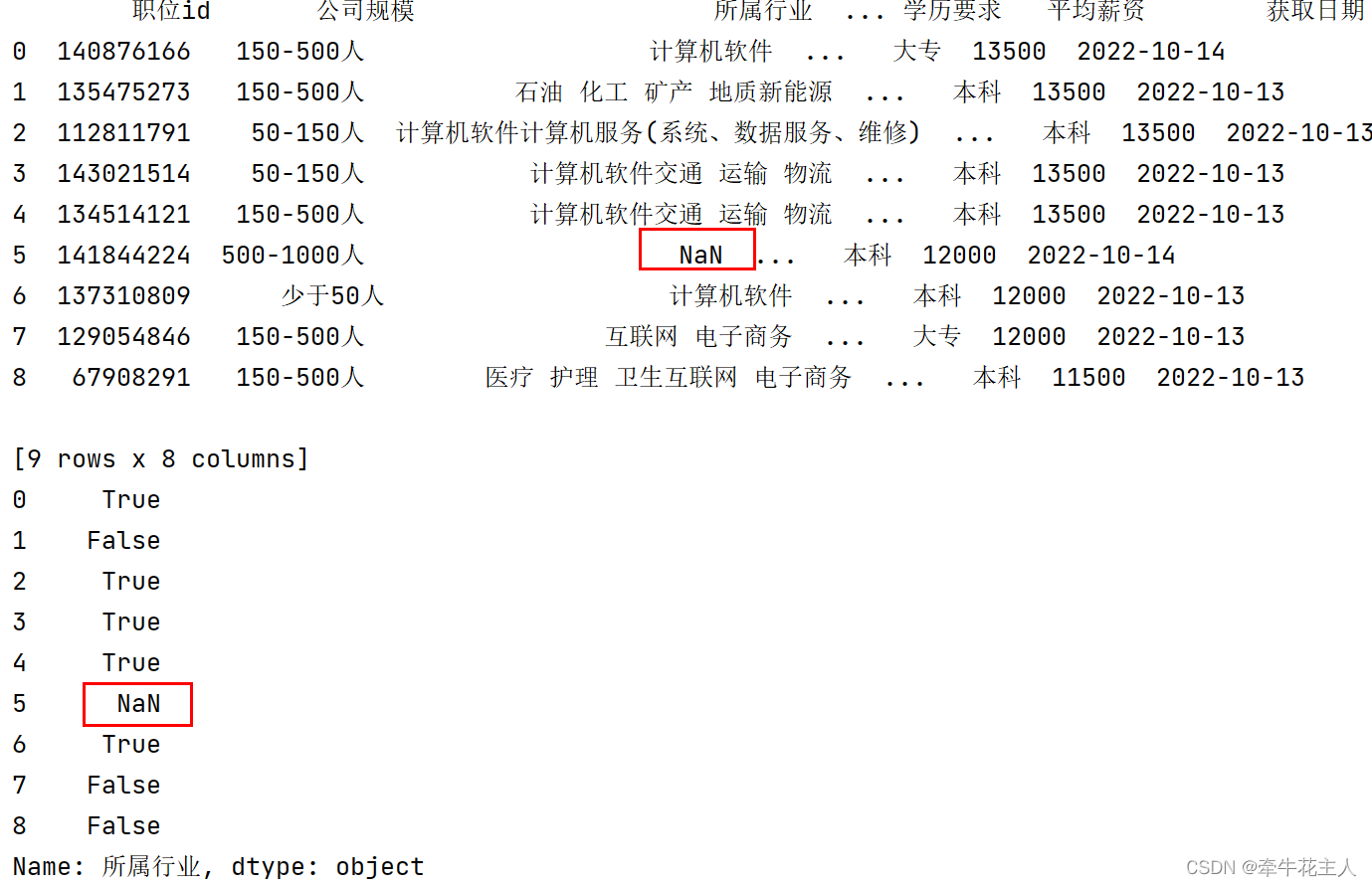
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order)
print(order['所属行业'].str.contains('计算机'))
对缺失值以“unknown"填充
print(order['所属行业'].str.contains('计算机',na='unknown'))

2.2 str.endswith()
2.2.1 函数功能
检测Series中的每个元素或索引是否以指定内容结尾,返回值为布尔值组成的Series或者Index
2.2.2 函数语法
Series.str.endswith(pat, na=None)
2.2.3 函数参数
| 参数 | 含义 |
|---|---|
| pat | 查找内容,可以是字符串或者字符串组成的元组,不接收正则表达式 |
| na | 缺失值返回内容,默认NaN |
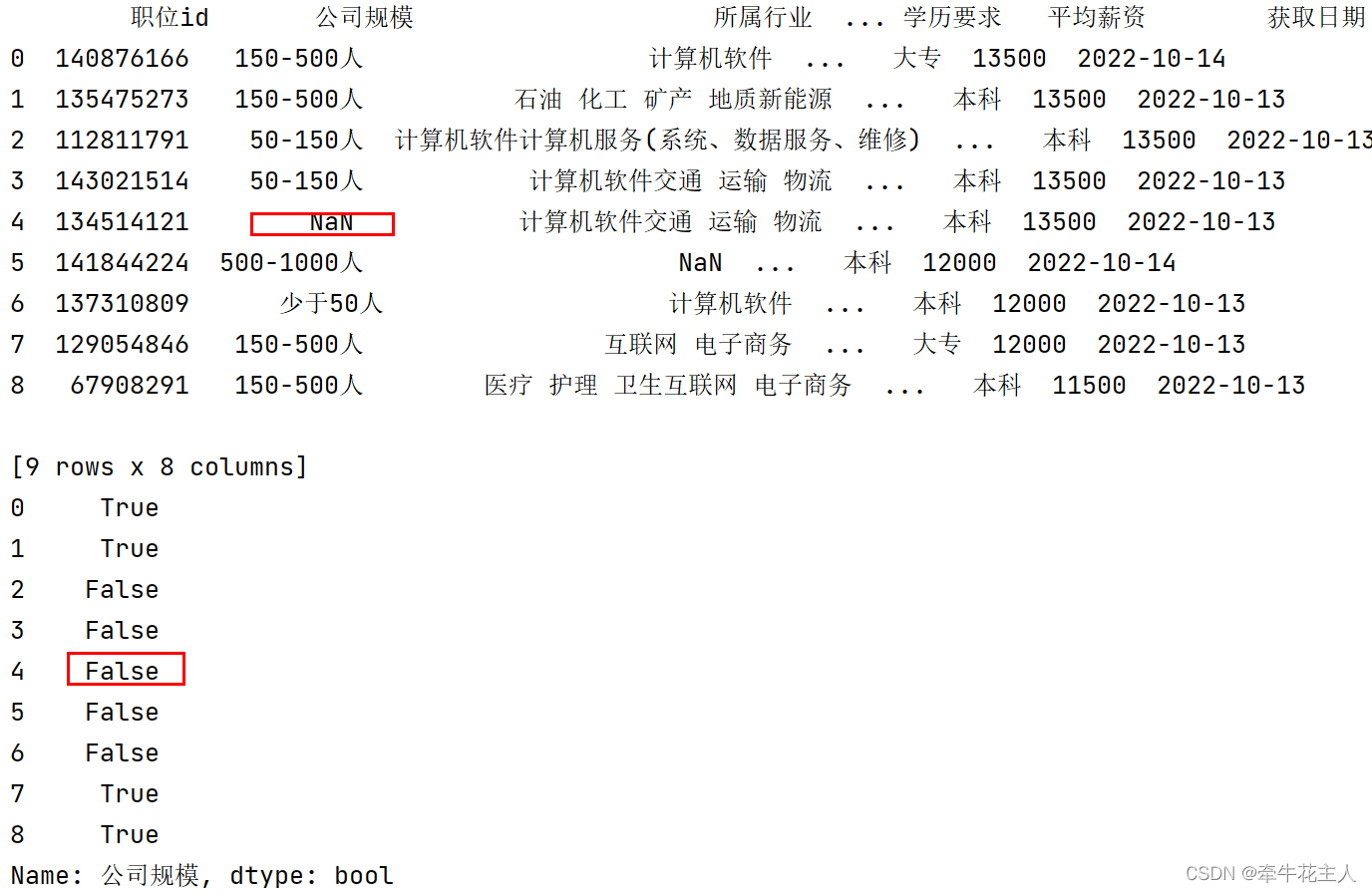
print(order['公司规模'].str.endswith('500人'))

包含空字符串时,认为空字符串中不包含指定内容,设置na=False
order.loc[4,'公司规模']=np.nan
print(order)
print(order['公司规模'].str.endswith('500人',na=False))
2.3 startswith()
2.3.1 函数功能
检测Series中的每个元素或索引是否以指定内容开始,返回值为布尔值组成的Series或者Index
2.3.2 函数语法
Series.str.startswith(pat, na=None)
2.3.3 函数参数
| 参数 | 含义 |
|---|---|
| pat | 查找内容,可以是字符串或者字符串组成的元组,不接收正则表达式 |
| na | 缺失值返回内容,默认NaN |
2.4 str.match()
2.3.1 函数功能
检测Series中的每个元素或索引是否以指定内容开始,返回值为布尔值组成的Series或者Index
2.3.2 函数语法
Series.str.match(pat, na=None)
2.3.3 函数参数
| 参数 | 含义 |
|---|---|
| pat | 要查找的内容,格式为正则表达式 |
| case | 布尔值,是否区分大小写,默认True:区分 |
| flags | 整数,默认值为0 |
| na | 标量,可选参数,对缺失值进行填充 |
str.startwith()与str.match()都可以检测Serie或者Series的Index是否以指定内容开始,凡是str.match()支持正则表达式,适用范围更广。
3.字符串替换
3.1 str.replace()
3.1.1 函数功能
替换指定内容
3.1.2 函数语法
Series.str.replace(pat, repl, n=- 1, case=None, flags=0, regex=False)
3.1.3 函数参数
| 参数 | 含义 |
|---|---|
| pat | 要查找的内容,字符串或正则表达式 |
| repl | 要被替换掉的字符串或可迭代对象 |
| n | 整数,进行替换操作的数量,默认为-1:替换所有 |
| case | 布尔值,是否区分大小写,默认True:区分 |
| flags | 整数,默认值为0 |
| regex | 布尔值,传入的pat是否是正则表达式,默认取值为False:不是正则表达式 |
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.head())
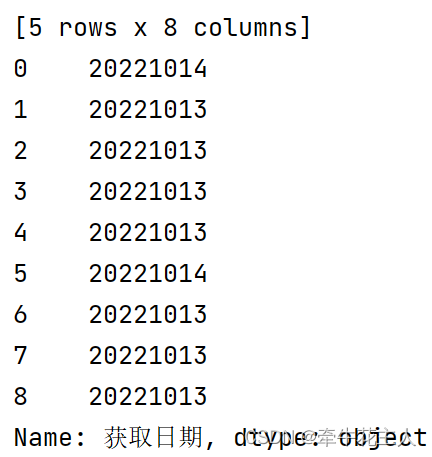
print(order['获取日期'].str.replace('-', ''))
# 将\d+视为正则表达式而不是普通字符
print(order['职位id'].astype(str).str.replace('\d+', '职位', regex='True'))


4. 字符串拼接
4.1 str.join()
4.1.1 函数功能
将Series或Index中的每个元素通过指定符号连接起来,当元素中有非字符串对象时,最终结果将为NaN
4.1.2 函数语法
Series.str.join(sep)[source]
4.1.3 函数参数
| 参数 | 含义 |
|---|---|
| sep | 连接符号 |
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.head())
print(order['学历要求'].str.join('*'))

4.2 str.cat()
4.2.1 函数功能
用指定的分隔符连接Series或者Index中的元素。当指定others,将Series或者Index与others中的元素连接;否则将Series或者Index中的元素连接为一个字符串。
4.2.2 函数语法
Series.str.cat(others=None, sep=None, na_rep=None, join='left')
4.2.3 函数参数
| 参数 | 含义 |
|---|---|
| others | 取值为Series、Index、DataFrane、np.array或者list-like |
| sep | 字符串,默认为:‘’:空字符串 |
| na_rep | 字符串或者None,默认为None,对缺失值的处理:当na_rep为None且当others没有时,连接结果将会忽略缺失值;如果na_rep为None,但是others有值,结果中将保留缺失值 |
| join | 决定Series或Index与others之间的连接方式,默认为left:左连接 |
others为None,将Series中的元素连接为一个字符串
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.head())
print(order['学历要求'].str.cat(sep='*'))

others存在,将Series与others中的值对应连接
print(order['学历要求'].str.cat(others=order['公司规模'], sep='*'))









![若依前端,菜单栏切换时刷新问题[页面菜单切换时,页面总是重新刷新,导致页面输入的查询参数重载清空]...](https://img-blog.csdnimg.cn/img_convert/69360451f9d7f30be558259027634b63.png)



![[工业互联-15]:Linux操作与实时Linux操作系统RT Linux( PREEMPT-RT、Xenomai)](https://img-blog.csdnimg.cn/img_convert/6cdfcebef3acf93ddc1ec2acb3454c8a.png)