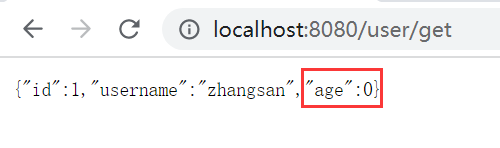
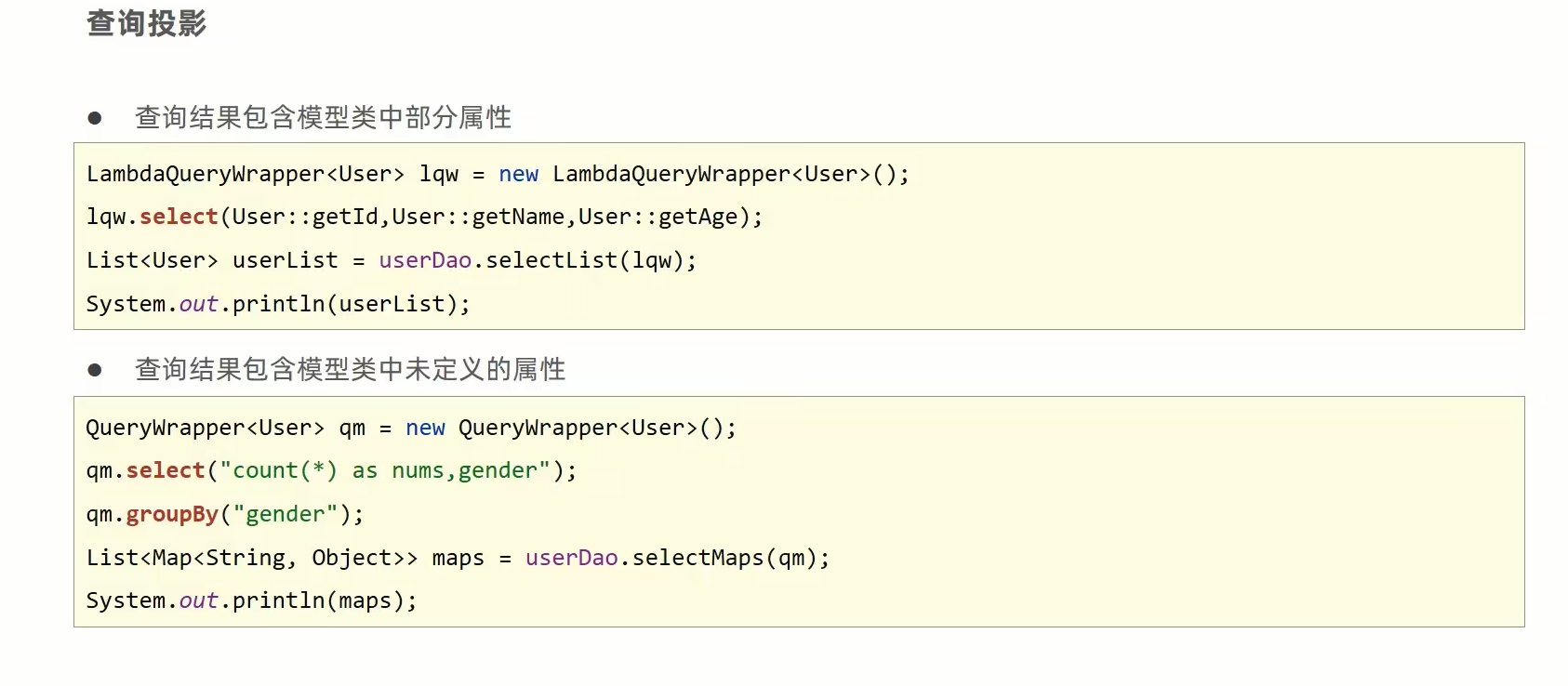
数字电路设计——加法器
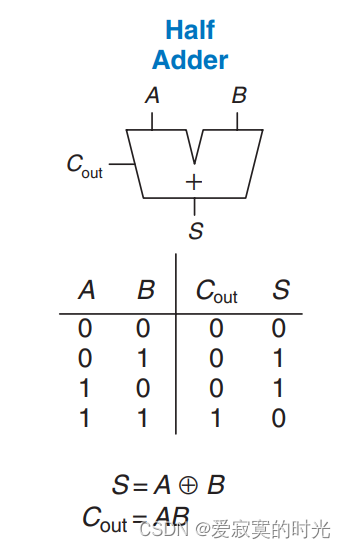
半加器
半加器只有两个一位宽的输入 a a a 和 b b b ,输出 a + b a+b a+b 所产生的本位和 s u m sum sum 和进位 c o u t cout cout。组合逻辑为:
S = A ⊕ B , C o u t = A B S = A \oplus B,Cout = AB S=A⊕B,Cout=AB
真值表和原理图符合为:
SystemVerilog实现代码:
module hadder (
input logic a,
input logic b,
output logic sum,
output logic cout
);
assign sum = a ^ b;
assign cout = a & b;
endmodule
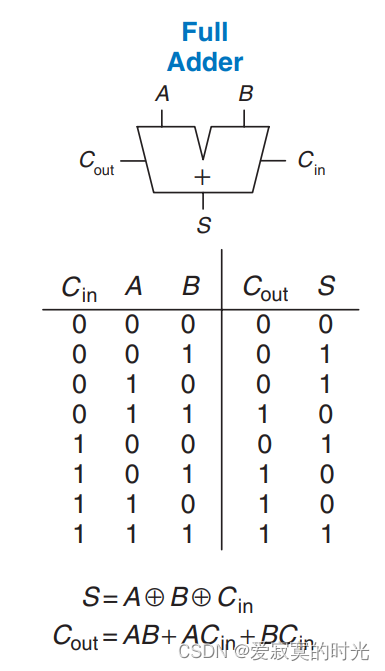
全加器
加法器一般指全加器,半加器只能实现一位加法,而全加器才能真正实现多位加法,相较于半加器,全加器考虑了上一位的进位,因此全加器有三个输入分别是 a , b , c i n a,b,cin a,b,cin ,输出 a + b + c i n a+b+cin a+b+cin 所产生的本位和 s u m sum sum 和进位 c o u t cout cout。组合逻辑为:
S = A ⊕ B ⊕ C i n , C o u t = A B + A C i n + B C i n S = A \oplus B \oplus Cin, Cout = AB + ACin + BCin S=A⊕B⊕Cin,Cout=AB+ACin+BCin
真值表和原理图符号为:
SystemVerilog实现代码:
module fadder (
input logic a,
input logic b,
input logic cin,
output logic sum,
output logic cout
);
assign sum = a ^ b ^ cin;
assign cout = a & b | a & cin | b & cin;
endmodule
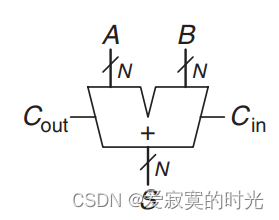
进位传播加法器
单个全加器只能实现单个位的加法,若想实习多位加法,就必须考虑到位于位直接的进位问题,我们称这类模拟竖式依次进位的加法器为进位传播加法器(carry propagate adder),简称CPA。
其原理图表示为:
进位链加法器
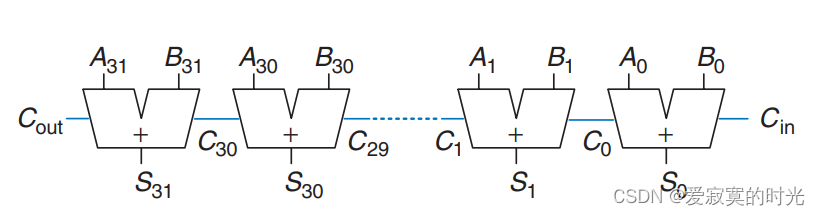
单个全加器只能实现单个位的加法,当将多个全加器进行进位链式连接的时候,就可以实现多位加法,我们称为进位链加法器(Ripple-Carry Adder),具体的,一个32位宽的进位链加法器可表示为:
SystemVerilog实现代码:
module rcadder(
input logic[31:0] a,
input logic[31:0] b,
input logic cin,
output logic[31:0] sum,
output logic cout
);
genvar i;
logic[32:0] c;
generate
assign c[0] = cin;
for(i = 0;i < 32;i=i+1) begin
fadder adder_inst(
.a (a[i]),
.b (b[i]),
.cin (c[i]),
.sum (sum[i]),
.cout (c[i + 1])
);
end
endgenerate
assign cout = c[32];
endmodule
显然,进位加法器的传播延迟 t r i p p l e t_{ripple} tripple 为:
t r i p p l e = N t F A t_{ripple} = Nt_{FA} tripple=NtFA
其中 N N N 为加法位宽,而 t F A t_{FA} tFA 是单个全加器的传播延迟。
超前进位加法器
进位链加法器的缺点在于进位传播的太慢,以至于进位链成为组合逻辑的关键路径,拖慢了系统时钟速率,通过巧妙的构造,可以加速这个过程,称为超前进位加法器(Carry-Lookahead Adder),简称CLA。
CLA使用生成(generate)G和传播(propagate)P两个信号来描述一个加法器如何控制进位的输入和输出。
具体的,考虑第 i i i 位全加器,我们称其生成进位而与上一位的进位无关,当且仅当 A i A_i Ai 和 B i B_i Bi 都是1,换句话说当 A i A_i Ai 和 B i B_i Bi 都是1的时候,该位一定进位而与上一位是否进位无关。
考虑第 i i i 位全加器,我们称其传播进位,则当上一位进位的时候,该位一定进位,此时 A i A_i Ai 和 B i B_i Bi 有一个至少是1。
两个信号的逻辑表达式为:
G i = A i B i , P i = A i + B i G_i = A_i B_i,P_i = A_i + B_i Gi=AiBi,Pi=Ai+Bi
现在我们再考虑当前进位 C i C_i Ci 和上一位进位的关系 C i − 1 C_{i-1} Ci−1 根据G和P的定义,显然有:
C i = G i + P i C i − 1 C_i = G_i + P_iC_{i-1} Ci=Gi+PiCi−1
现在来考虑一个进位链加法器,我们将 G i : j G_{i:j} Gi:j 表示为第j个到第i个加法器所组成CPA的G信号,而将 P i : j P_{i:j} Pi:j 表示为第j个到第i个加法器所组成CPA的P信号。
具体的,考虑 G 3 : 0 G_{3:0} G3:0 的表示,若 G 3 : 0 G_{3:0} G3:0 成立,当且仅当 G 3 G_3 G3 成立,或是 P 3 G 2 : 0 P_3G_{2:0} P3G2:0 成立。那么:
G 3 : 0 = G 3 + P 3 G 2 : 0 G_{3:0} = G_3 + P_3G_{2:0} G3:0=G3+P3G2:0
我们发现这是一个递归定义的式子,将递归展开后得到:
G 3 : 0 = G 3 + P 3 ( G 2 + P 2 ( G 1 + P 1 G 0 ) ) G_{3:0} = G_3 + P_3(G_2 + P_2(G_1 + P_1G_0)) G3:0=G3+P3(G2+P2(G1+P1G0))
考虑 P 3 : 0 P_{3:0} P3:0 的表示,其结构类似于串联的开关:
P 3 : 0 = P 3 P 2 P 1 P 0 P_{3:0} = P_3P_2P_1P_0 P3:0=P3P2P1P0
而且下面的式子显然成立:
C i = G i : j + P i : j C j − 1 C_i = G_{i:j} + P_{i:j}C_{j-1} Ci=Gi:j+Pi:jCj−1
有了上面的基础,我们就可以描述超前进位加法器的结构:
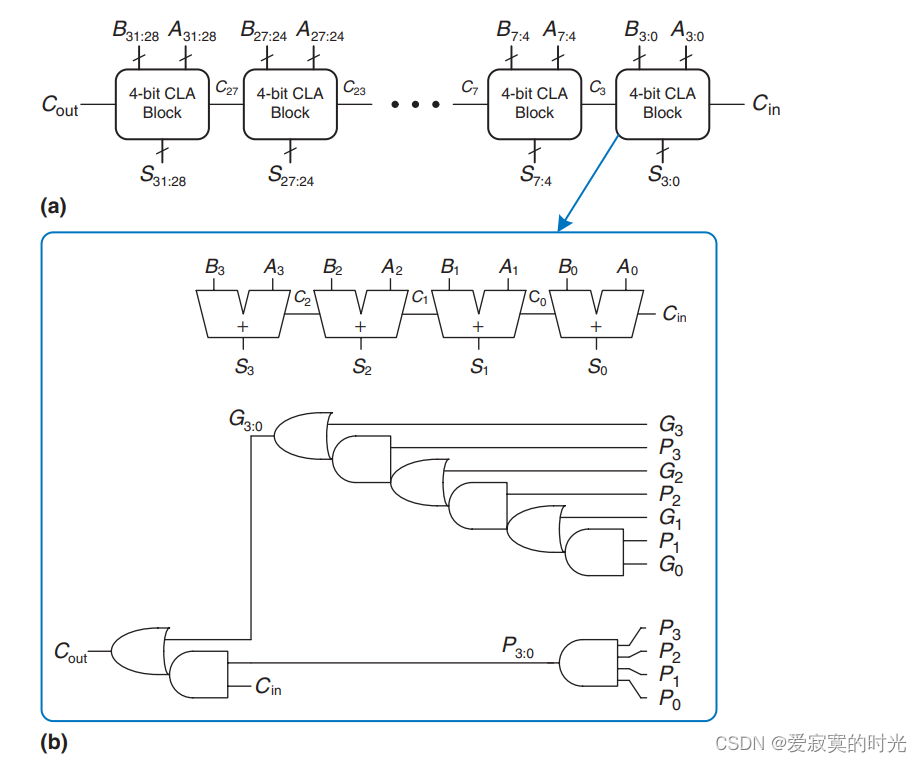
超前进位加法器利用了并行的思想,例如将32位的加法,拆成8个4位的并行加法器,每个4位加法器中仍然使用进位链加法器,不同的是,通过构造G和P,使得并行加法器之间传播进位更快了,解决了传统进位链加法器进位传播慢的特点。具体的,G和P只和当前位有关,而和进位位无关,因此对于G和P的计算结构是并行的。
一旦所有并行加法器的 G i : j G_{i:j} Gi:j 和 P i : j P_{i:j} Pi:j 同时计算好之后, C C C 进位就可以快速的传播,只需要串行传播8次即可,相比于进位链加法器传播32次少了不少。下面是超前进位加法器的时间线:
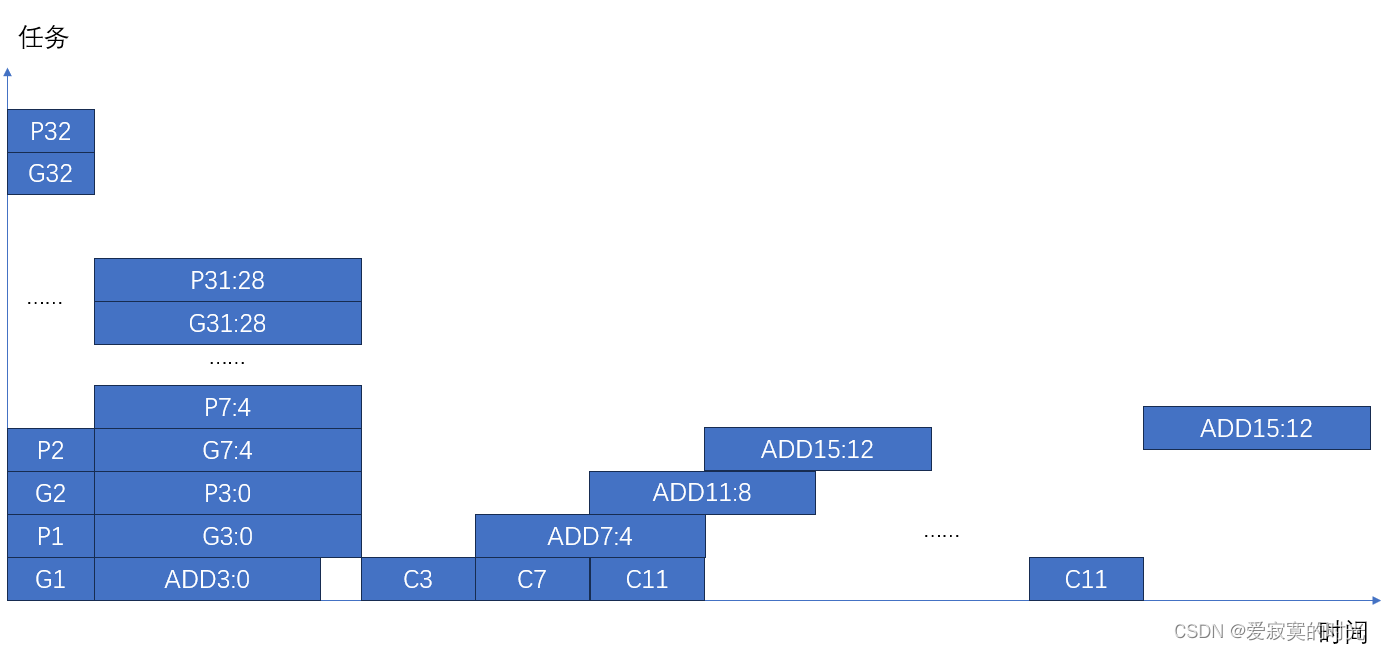
观察可以得到,超前进位加法器的传播延迟为:
t C L A = t p g + t p g b l o c k + ( N k − 1 ) t A N D / O R + k t F A t_{CLA} = t_{pg} + t_{pgblock} + (\frac{N}{k} - 1) t_{AND/OR} + kt_{FA} tCLA=tpg+tpgblock+(kN−1)tAND/OR+ktFA
其中 t p g t_{pg} tpg 是计算单个 G i G_i Gi 和 P i P_i Pi 的时间,通常是一个与门或是或门的传播时延。 t p g b l o c k t_{pgblock} tpgblock 是计算单个并行加法器的G和P的时间, N N N 是加法器的位数, k k k 的每个并行加法器的位数, t A N D / O R t_{AND/OR} tAND/OR 是从 C i C_i Ci 到 C i + k C_{i+k} Ci+k 的时延,通常为一个或门加与门的传播时延。 k t F A kt_{FA} ktFA 是一个并行加法器的加法的传播时延。
当 N > 16 N > 16 N>16 的时候,超前进位加法器的时延将远大于进位链加法器。
SystemVerilog实现代码:
module rcadder4(
input logic[3:0] a,
input logic[3:0] b,
input logic cin,
output logic[3:0] sum,
output logic cout
);
genvar i;
logic[4:0] c;
generate
assign c[0] = cin;
for(i = 0;i < 4;i=i+1) begin
fadder adder_inst(
.a (a[i]),
.b (b[i]),
.cin (c[i]),
.sum (sum[i]),
.cout (c[i + 1])
);
end
endgenerate
assign cout = c[4];
endmodule
module cladder(
input logic[31:0] a,
input logic[31:0] b,
input logic cin,
output logic[31:0] sum,
output logic cout
);
genvar i;
logic[31:0] g;
logic[31:0] p;
logic[8:0] c;
generate
assign c[0] = cin;
for(i = 0;i < 32;i=i+1) begin
assign g[i] = a[i] & b[i];
assign p[i] = a[i] | b[i];
end
for(i = 0;i < 8;i=i+1) begin
logic g_block;
logic p_block;
assign g_block = g[i * 4 + 3] | p[i * 4 + 3] & (g[i * 4 + 2] | p[i * 4 + 2] & (g[i * 4 + 1] | p[i * 4 + 1] & g[i * 4]));
assign p_block = p[i * 4 + 3] & p[i * 4 + 2] & p[i * 4 + 1] & p[i * 4];
assign c[i + 1] = g_block | p_block & c[i];
rcadder4 adder4_inst(
.a (a[(i + 1) * 4 - 1:i * 4]),
.b (b[(i + 1) * 4 - 1:i * 4]),
.cin (c[i]),
.sum (sum[(i + 1) * 4 - 1:i * 4]),
.cout ()
);
end
endgenerate
assign cout = c[8];
endmodule








![[神经网络]YoloV7](https://img-blog.csdnimg.cn/499b540541f64dd381b19872155ab801.png)