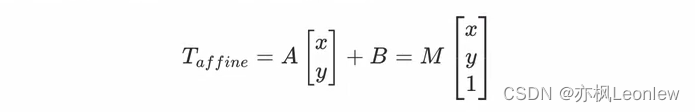编者按:2020年,微软亚洲研究院开源了金融 AI 通用技术平台 Qlib。Qlib 以金融 AI 研究者和金融行业 IT 从业者为用户,针对金融场景研发了一个适应人工智能算法的高性能基础设施和数据、模型管理平台。一经开源,Qlib 便掀起了一阵热潮,相关开源项目在 GitHub 上已收获了11.4k颗星。作为一个通用技术平台,Qlib 不仅大大降低了行业从业者使用 AI 算法的技术门槛,还为金融 AI 研究者提供了一个相对完整的研究框架,让他们可以基于专业知识探索更广泛的金融 AI 场景。
微软亚洲研究院对 Qlib 的研究并未止步于此,经过两年多的深入探索,Qlib 迎来了重大更新,在原有的 AI 量化金融框架基础上,又引入了基于强化学习和元学习的新范式以及订单执行优化和市场动态性建模的新场景,帮助相关从业者使用更先进和多样的人工智能技术来应对更复杂的金融挑战。
金融业务的目标复杂性和顺序决策流程的特殊本质,让构建有效的金融决策模型成为一项十分困难的任务。一方面,金融市场的交易规则及其相互作用十分复杂,给金融策略的模拟和评估带来了巨大挑战。并且,策略模型优化往往涉及收益最大化和风险最小化,是一个多目标优化问题,这进一步增加了获得监督信号的难度。
另一方面,金融市场一系列决策之间相互依赖,这些决策共同决定了最终的策略表现,这使得一系列机器学习算法的独立同分步(Independent and Identically Distributed,IID)假设无效,导致传统的监督学习、半监督学习、无监督学习方法很难适用于这些金融场景的决策。
而基于强化学习(Reinforcement Learning, RL)的学习范式不需依赖标注样本,可通过智能体与环境的交互来收集相应的样本(如状态、动作、奖励)进行试错学习,从而不断改善自身策略来获取最大的累积奖励。这种通过不断试错和探索环境来进行学习,以寻找更好策略的学习范式更有利于满足上述金融决策的需求。
“在应用强化学习时,应用环境需要具有一定的沙盒属性。因为强化学习是通过反复试错的机制进行学习的,如果结果正确它就会得到强化。在现实世界中,游戏和金融领域的回测都是典型的沙盒场景。所以,我们希望能够利用强化学习来帮助解决金融决策的问题。”微软亚洲研究院高级研究员任侃说。
基于这一认知,Qlib 团队的研究员们针对交易决策和投资组合管理策略展开了研究,并在全新升级的 Qlib 中增加了基于强化学习的单智能体订单执行优化和多智能体批量订单联合优化的示例算法及其相应的平台支撑功能。

OPD先知策略提取:更好的订单优化策略
订单执行优化是算法交易中的一个基本问题,目的是通过一系列交易决策完成预设的元交易订单(meta-order),如平仓、建仓及仓位调整。从本质上讲,订单执行的目标是双重的,不仅要求完成整个订单,而且追求更经济的执行策略,实现收益最大化或资本损失最小化。针对订单执行的顺序决策特点,强化学习方法可以发挥优势捕捉市场的微观结构,从而更好地执行订单。
但简单、直接地使用强化学习会遇到一个问题——原始的订单及市场数据中存在大量噪声和不完美的信息。噪声数据可能导致强化学习的样本效率低下,使学习订单执行策略的有效性降低。更重要的是,在采取行动时,可以利用的信息只有历史市场信息,缺少明显的线索来对市场价格或交易活动的未来趋势做准确预测。
为此,Qlib 团队提出了一个通用的订单执行策略优化框架,引入了全新的策略提取方法 OPD(Oracle Policy Distillation,先知策略提取),来弥合噪声和不完美市场信息与最优订单执行策略之间的差距。该方法是一种“教师-学生”(teacher-student)的学习范式,“教师”在获得完美信息的情况下,会先被训练成一个可以找出最佳交易策略的“先知”,然后“学生”通过模仿“教师”的最佳行为模式来进行学习。而当模型训练阶段结束进入到实际使用阶段时,OPD 会在没有“教师”或未来信息的情况下,使用“学生”策略进行订单执行的规划。而且,与传统强化学习方法只为单一股票训练单一模型的思路不同,Qlib 团队提出的这一强化学习算法可以利用所有股票的数据做联合训练,从而极大缓解学习过程中的过拟合问题。

图1:OPD 先知策略提取示意图
实验结果显示, OPD 的性能显著优于其它方法,证明了 OPD 的有效性,也证实了传统基于金融市场假设的方法在真实场景中并不适用。此外,其它基于训练的数据驱动的方法因为未能很好地捕捉到市场的微观结构,所以也无法相应地调整策略,导致策略性能相较 OPD 方法较弱。

表1:OPD 方法实验结果(数值越高性能越好)。
多智能体协作方案MARL:显著提高批量订单的执行性能
在量化金融中,对资产管理的一类主要目标是通过在市场上连续交易多种资产来最大化长期价值。所以,除了订单执行外,投资组合管理也是量化金融中一个基础的场景,其目标是在一定的时间范围内,完成投资组合管理策略指定的大量订单,从而实现本轮的投资组合持仓调整,并尽可能降低换仓的成本甚至通过订单执行提高整体收益。
在多订单执行的联合优化中存在三个问题。首先,订单数量及交易金额每天都会根据投资组合的分配而变化,这要求订单执行策略具有可扩展性和灵活性,以支持多种不同的订单情况。其次,现金余额有限,所有的买入资产操作都会消耗交易者有限的现金供应,而出现的现金缺口只能通过卖出资产操作来进行补充。另外,现金不足可能会使得投资者错过更好的交易执行机会,所以投资者要在买入及卖出之间实现平衡,避免交易决策因为现金短缺导致交易执行业绩不佳。
尽管市场上存在许多用于订单执行的工具,但这些工具很少能够同时解决上述三个问题。为了解决这些挑战,Qlib 团队推出了多智能体协作强化学习(Multi-Agent Reinforcement Learning, MARL)方法,让每个智能体执行一个单独的订单,再以分解联合行动空间(joint action space)扩展到多个不同的订单,并且所有智能体协作可以在较少的决策冲突情况下实现更高的总利润。为了加强各智能体之间的协作,研究员们还提出了一种新的多轮意图感知通信机制,以了解每个协作阶段智能体的行动意图,该机制使用了新的行动价值归因(value attribution)方法,可以直接优化和细化每一轮智能体的预期行动。

图2:多智能体强化学习算法中多轮意图感知机制示意图
实验表明,在 A 股及美股数据上共6个不同测试时间窗口里,MARL(即表2中的 IaC^C 和 IaC^T)相比于单智能体强化学习、简单的多智能体强化学习及传统金融模型方法都在各项指标上有显著提升。此外,意图感知通信机制大大降低了 TOC 度量(用于衡量多订单执行中买、卖操作不均衡带来的现金短缺情况),这表明采用通信共享意图行动的方法比以前的 MARL 方法提供了更好的协作性能。并且研究员们提出的 IaC 方法的效果,远远超出了此前一些利用通信共享智能体意图的方法,这表明在单个时间段内细化多轮的行动意图对于智能体在复杂环境中实现良好协作来说至关重要。

表2:MARL 在 A 股及美股数据上6个不同测试时间窗口里五个关键性指标的实验结果。↑ (↓) 意味着值越高(越低)越好。
强化学习在金融领域的研究离不开专用框架的支撑
研究新算法通常需要快速地进行反复迭代,而迭代效率则在很大程度上取决于研究框架的完善程度。为了更好地推进强化学习在金融领域的前沿研究,Qlib 针对金融领域的特性,提供了全面的框架支持。

图3:全新升级的 Qlib 框架示意图
Qlib 新发布的金融领域强化学习框架提供了三个关键特性,以解决强化学习在金融领域应用的常见问题。
1. 在金融领域使用强化学习时,用户往往需要对接金融强化学习环境,通过设计马尔可夫决策过程(Markov Decision Process, MDP),集成强化学习策略算法。整个过程需要大量的工程工作,同时也需要大量的金融专业知识和实战经验,非常费时费力,导致研究人员无法专心于研究问题本身。Qlib 直接提供了涵盖上述问题的完整技术栈,免去了研究人员大量繁琐的重复工作。
2. 强化学习是通过与环境交互试错来优化策略的。但模拟环境与实际市场环境之间往往存在较大差异,这种差异可能导致模拟环境的最优解与真实环境的最优解存在很大的差距,这是强化学习研究落地的难点之一。这种差距一方面来自于真实交易包含了大量繁琐的规则,而一般用于学术研究的交易框架常常会忽略这些规则;另一方面,真实交易中通常是不同层次的交易互相结合使用(如日频交易和高频交易),忽视这部分交互影响也会对模拟产生偏差。Qlib 在设计时尽可能考虑到了各种规则,并将嵌套决策框架(nested decision making)用于模拟真实交易时不同层次交易策略的互相影响,从而最大限度地减少模拟误差。
3. 强化学习需要大量计算资源,涉及与环境的交互和试错,可能需要多次迭代才能达到最优策略。特别是在金融市场的复杂规则下,这些交互可能非常耗时,需要大量内存和计算。为了加速强化学习的研究迭代,优化训练和测试流程至关重要。Qlib 提供了不同仿真程度的模拟器,用户可以在训练时在不同的阶段使用不同仿真程度的模拟器(例如,在训练早期使用低仿真度但运行效率极高的模拟器,在训练后期使用高仿真同时资源开销较大的模拟器),从而实现在获得高仿真环境下的最优策略的同时,节约计算资源并加快训练速度。在测试环节,通过 Qlib 可灵活调度强化学习智能体的训练及测试环境的这一功能,实现提高回测并行度以加速策略的评估。
实时市场动态建模:更有效地预测未来数据分布
在现实世界的真实场景中,人们处理的数据往往是随时间顺序收集的流式数据,但机器学习算法能够被广泛应用于现实世界一般依赖数据独立同分布的假设。然而,金融领域的数据是非独立同分布的,它的规律会随着时间产生变化,这就导致传统的依赖独立同分布假设的机器学习模型难以在不同时间上同时进行有效预测。这种流数据分布以不易预测的方式发生变化的现象被称为概念漂移。
为了处理概念漂移,此前的方法是先检测概念漂移发生的时间,再调整模型以适应最新数据的分布,但是这类方法无法应对数据分布在下一个时刻继续发生变化的问题。Qlib 团队的研究员们发现,除了一些极端难以预料的分布突变,概念漂移常常以渐进地非随机方式演变,且这种渐进的概念漂移在某种程度上是可预测的,即概念漂移本身就存在一定的趋势和规律。而实际上这种场景在流数据中十分常见,但大多数现有研究都较少关注这一方向。因此,Qlib 团队通过预测未来的数据分布来关注可预测的概念漂移,并提出了新的方法 DDG-DA(Data Distribution Generation for Predictable Concept Drift Adaptation),来有效地预测数据分布的演变,并提高模型的性能。其具体的思路是,首先训练预测器来估计未来的数据分布,然后利用它生成训练样本,最后在生成的数据上训练模型。

图4:DDG-DA 算法示意图
DDG-DA 方法已经在三个实际任务中进行了实验:股票价格趋势、电力负荷和太阳辐照度的时序预测,并在多个广泛使用的模型上获得了显著的性能提升。

表3:DDG-DA 在概念漂移可预测场景中的 SOTA 表现
微软亚洲研究院高级研究员杨骁表示,“如果用户在使用工具时没有考虑到时间上数据分布的动态变化 ,那么最终的建模将是不完善的。我们的动态市场建模方法可以动态调整数据分布,让模型更好地学习和适应当前市场的规律。相比于传统使用历史数据构建模型进行预测的方法,DDG-DA 能够根据实时的市场规律变化,使用与未来分布更相似的数据建模,从而可以更准确地预测未来。”
元学习框架助力市场动态性建模
在市场动态性研究中,DDG-DA 通过调整数据分布间接地影响预测模型的训练过程,从而影响最终的预测结果。这种训练模式本质上是在学习如何训练一个模型,可以归结到元学习(Meta Learning)范畴。Qlib 提供了一套元学习框架,定义了元学习中任务、数据、模型的接口规范。
使用这套框架,研究者和从业人员不仅可以训练模型,还可以设计元模型(meta model)来自动地学习如何更好地训练模型,这为开展 DDG-DA 类似的研究工作提供了极大的便利。未来,Qlib 团队希望这个框架能够为更多的元学习算法提供支持,从市场动态性研究开始,扩展到更多的场景和问题。
更新版Qlib已开源,全新功能等你来探索
集成了最新功能的多范式 Qlib 现已在 GitHub 上发布。其新增的框架和组件能更好地支持强化学习这一学习范式在金融领域中进行智能决策相关的研究和应用。同时 Qlib 团队还发布了基于 Qlib 框架在订单执行这一典型场景下,基于强化学习的先知策略提取 OPD 及多智能体协作 MARL 的两个示例算法。而对元学习范式的支持也使得类似于市场动态性建模这类依赖元学习范式场景上的相关研究得以高效地开展并且更方便于实际应用,为智能金融决策又增加了一个成功的砝码。
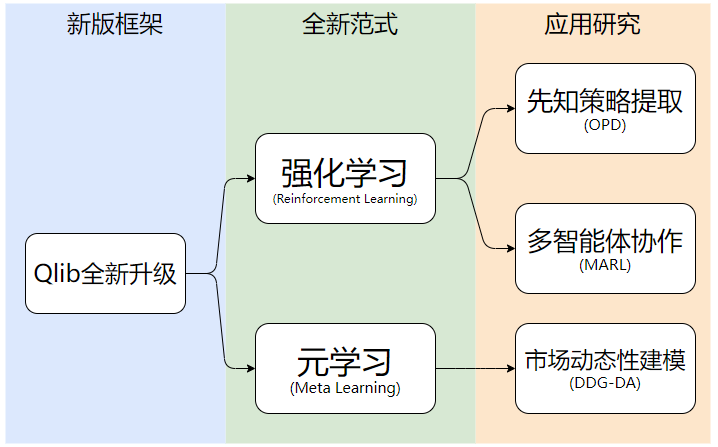
图5:新版 Qlib 更新内容
“从数据处理到算法支撑,再到模型的训练与验证,此前的 Qlib 在纵向深度上为金融 AI 研究者和金融行业从业者提供了一个全方位面向 AI 量化投资的研究框架,而升级后的 Qlib 则在横向广度上为智能金融决策提供了更多新的学习范式,能够帮助使用者更精准地匹配金融业务及相关研究的需求。全新升级的 Qlib 将更多的 AI 算法、学习范式与更广阔的金融任务、场景相连接,提供了一个更易用、更高效的量化金融研究平台。”微软亚洲研究院首席研究员刘炜清表示。
相关论文:
Universal Trading for Order Execution with Oracle Policy Distillation
https://arxiv.org/abs/2103.10860
DDG-DA: Data Distribution Generation for Predictable Concept Drift Adaptation
https://arxiv.org/abs/2201.04038
GitHub链接:
https://github.com/microsoft/qlib