日前,业界正式发布国内首个 具备可视化和自动化的AI 原生云向量数据库 " 据悉,向量数据库专门用于存储和查询向量数据,业界称之为大模型的 " 海马体 ",可解决大模型预训练成本高、没有 " 长期记忆 "、知识更新不足、提示词工程复杂等问题,并突破大模型在时间和空间上的限制,加速大模型落地行业场景。
随着大模型的不断发展和普及,AI 原生向量数据库将成为企业数据处理的标配。

AI 原生云向量数据库将能够被广泛应用于大模型的训练、推理和知识库补充等场景,例如支撑训练阶段海量数据的分类、去重和清洗,给大模型的训练降本增效;通过新数据的带入,帮助大模型提升处理新问题的能力,突破预训练带来的知识时间限制,避免大模型出现幻觉等。
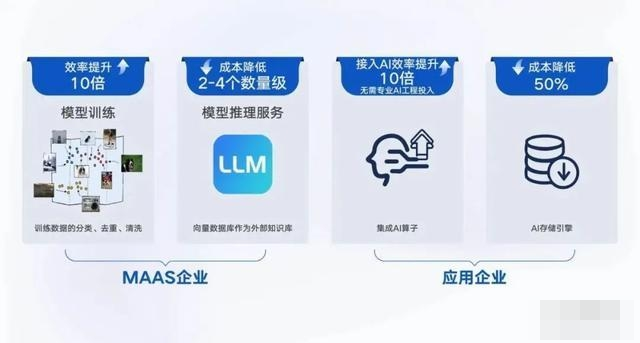
AI 原生云向量数据库用于大模型预训练数据的分类、去重和清洗,相比传统方式可实现 10 倍效率的提升,如将其作为外部知识库用于模型推理,则可将成本降低 2-4 个数量级。
AI 原生云向量数据库,提供了接入层、计算层、存储层的全面 AI 化解决方案,,使得用户在使用向量数据库的全生命周期都能应用到 AI 能力。

其中在接入层,AI 原生云向量数据库支持自然语言文本的输入,同时采用 " 标量 + 向量 " 的查询方式,支持全内存索引;在计算层,AI 原生云向量数据库能实现全量数据 AI 计算,一站解决企业在搭建私域知识库时的文本切分 ( segment ) 、向量化 ( embedding ) 等难题;在存储层,AI 原生云向量数据库支持数据智能存储分布,让企业存储成本降低 50%。

AI 原生云向量数据库最高支持业界领先的 10 亿级向量检索规模,并可将延迟控制在毫秒级,相比传统单机插件式数据库检索规模提升 10 倍,同时还具备百万级每秒查询 ( QPS ) 的峰值能力。据悉,使用AI 原生云向量数据库后,企业接入大模型需要花费的时间能从一个月降低至三天左右。