文章目录
- @[toc]
- C++11
- **`lambda` 表达式**
- `lambda` 表达式
- `lambda` 表达式底层
- 包装器 `function`
- `function` 包装普通可调用对象
- `function` 包装类内成员函数
- `bind()`
- `bind()` 使用 及 功能
- 1. 调整参数位置
- 2. 绑定参数
文章目录
- @[toc]
- C++11
- **`lambda` 表达式**
- `lambda` 表达式
- `lambda` 表达式底层
- 包装器 `function`
- `function` 包装普通可调用对象
- `function` 包装类内成员函数
- `bind()`
- `bind()` 使用 及 功能
- 1. 调整参数位置
- 2. 绑定参数
C++11
上一篇介绍C++11常用的新特性只介绍了一部分. 本篇文章继续分析介绍.
lambda 表达式
C++11之前, 我们使用 std::sort() 接口对自定义类型进行排序 或者 设置降序排列, 需要使用 仿函数, 就像这样:
#include <iostream>
#include <iterator>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
using std::cout;
using std::endl;
using std::greater;
using std::string;
using std::vector;
struct Goods {
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
: _name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
// 价格升序仿函数
struct ComparePriceLess {
bool operator()(const Goods& gl, const Goods& gr) {
return gl._price < gr._price;
}
};
// 价格降序仿函数
struct ComparePriceGreater {
bool operator()(const Goods& gl, const Goods& gr) {
return gl._price > gr._price;
}
};
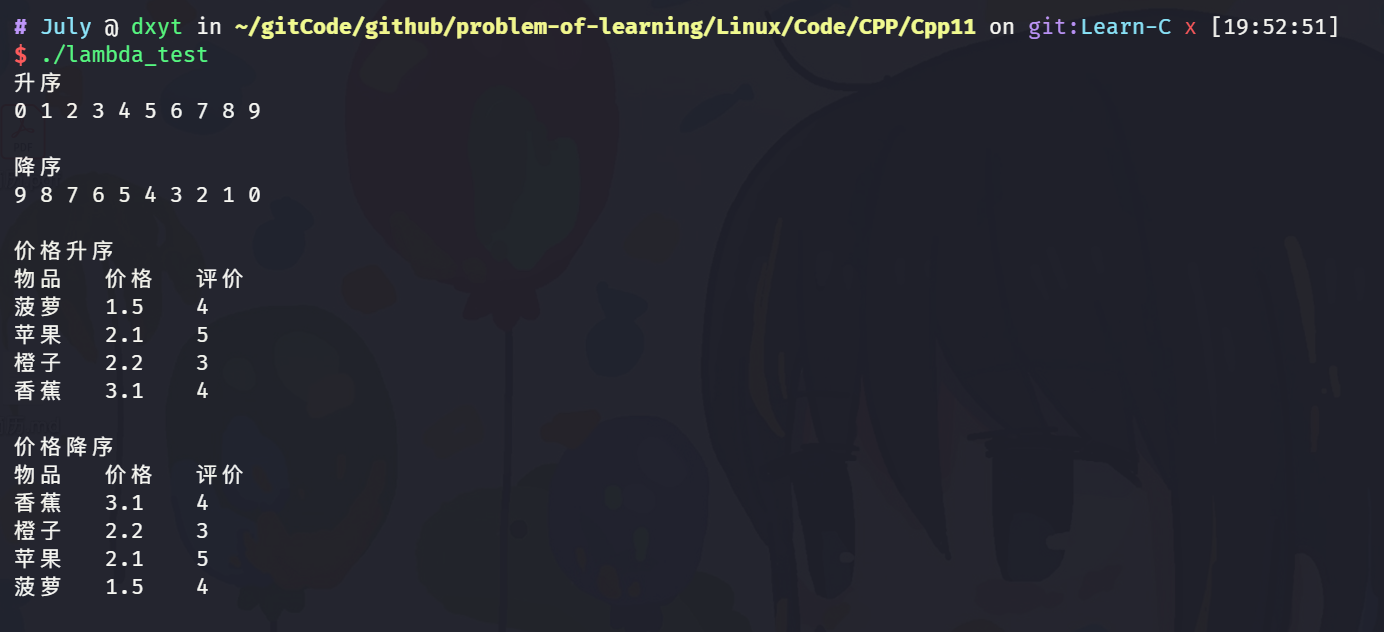
int main() {
int array[] = {4, 1, 8, 5, 3, 7, 0, 9, 2, 6};
// 默认按照小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
cout << "升序" << endl;
for (auto e : array) {
cout << e << " ";
}
cout << endl << endl;
// 如果需要降序,需要改变元素的比较规则
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
cout << "降序" << endl;
for (auto e : array) {
cout << e << " ";
}
cout << endl << endl;
vector<Goods> v = {
{"苹果", 2.1, 5},
{"香蕉", 3.1, 4},
{"橙子", 2.2, 3},
{"菠萝", 1.5, 4}
};
sort(v.begin(), v.end(), ComparePriceLess());
cout << "价格升序" << endl;
cout << "物品 价格 评价" << endl;
for (auto e : v) {
cout << e._name << " " << e._price << " " << e._evaluate << endl;
}
cout << endl;
sort(v.begin(), v.end(), ComparePriceGreater());
cout << "价格降序" << endl;
cout << "物品 价格 评价" << endl;
for (auto e : v) {
cout << e._name << " " << e._price << " " << e._evaluate << endl;
}
cout << endl;
return 0;
}
std::sort() 针对标准类型, 默认是按照降序排序的.
在上述代码中, 我们通过 标准中的仿函数 std::greater 可以让 std::sort 对数组升序排序.
而如果我们想要实现 对自定义类型进行排序, 就需要根据排序需求 定义相应的仿函数传给 std::sort() 然后才可以正确的排序.
上面代码的执行结果是:
但是, 如果每次想要对不同自定义类型实现按需求排序, 那就 每次都需要定义一个满足需求的仿函数. 这样好像太麻烦了.
所以, C++11 引入了 lambda 表达式
lambda 表达式
什么是 lambda 表达式呢?
先来看一下效果:
// 其他部分还是 上面代码中的部分
void printGoods(vector<Goods>& v) {
cout << "物品 价格 评价" << endl;
for (auto e : v) {
cout << e._name << " " << e._price << " " << e._evaluate << endl;
}
cout << endl;
}
int main() {
vector<Goods> v = {
{"苹果", 2.1, 5},
{"香蕉", 3.1, 4},
{"橙子", 2.2, 3},
{"菠萝", 1.5, 4}
};
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._price < g2._price; });
cout << "价格升序" << endl;
printGoods(v);
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._price > g2._price; });
cout << "价格降序" << endl;
printGoods(v);
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._evaluate < g2._evaluate; });
cout << "评价升序" << endl;
printGoods(v);
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._evaluate > g2._evaluate; });
cout << "评价降序" << endl;
printGoods(v);
return 0;
}
这段代码的执行结果是:
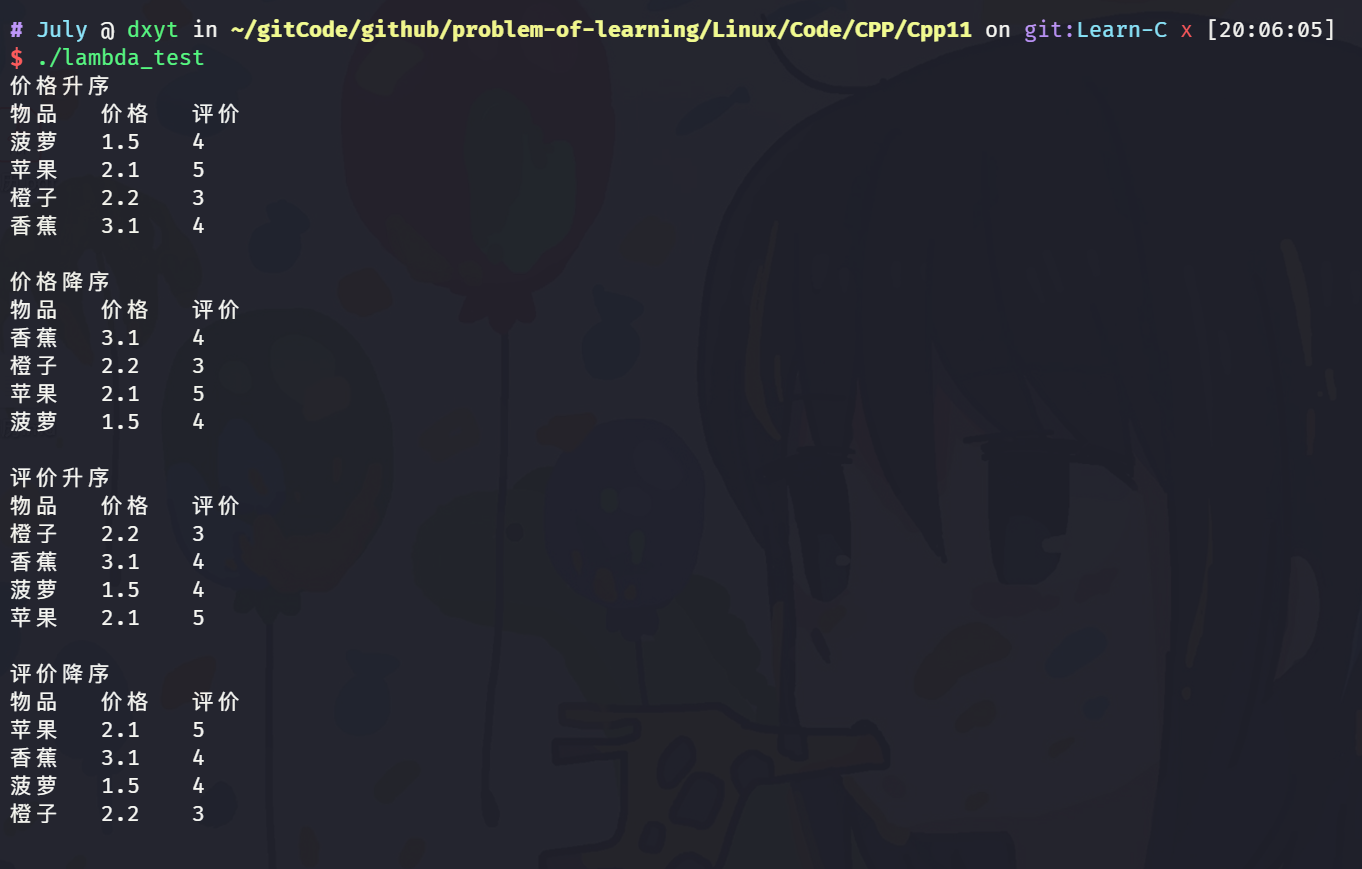
我们没有实现仿函数, 但是依旧实现了按需求排序. 这就是因为使用了 lambda 表达式
上面的例子中, std::sort() 的第三个参数:

这些都是 lambda 表达式. 不过 并不完整, lambda 表达式的完整格式为:
[captureList] (parameters) mutable -> returnType { statement }
[]()mutable->xxx{ }
这些都表示什么意思呢?
-
[capture-list]:捕捉列表该列表总是出现在
lambda表达式的开始位置, 编译器根据[]来判断接下来的代码是否为lambda表达式, 捕捉列表能够捕捉上下文中的变量供lambda表达式使用 -
(parameters):参数列表与 普通函数的参数列表 一致. 如果不需要参数传递, 则可以连同
()一起省略 -
mutable默认情况下,
lambda函数总是一个const函数, 即 它的捕捉的 值对象 可以被看作默认被const修饰.mutable可以取消其常量性. 使用该修饰符时,参数列表不可省略(即使参数为空) -
-->returnType:返回值类型用 追踪返回类型形式 声明函数的返回值类型, 没有返回值时此部分可省略. 返回值类型明确情况下. 也可省略. 由编译器对返回类型进行推导
什么是返回值类型明确的情况下?
看一看上面的例子, 结果一定是一个
bool所以可以省略返回值声明类似的情况就可以省略
-
{ statement }:函数体与普通函数的编写方式相同. 但是 在此作用域内, 只能使用传入的参数 或 捕捉到的父级作用域对象.
参数列表、mutable、返回值类型在特定情况下都可以省略
从 lambda 表达式的组成来看, 与函数非常的相似. 而实际上, lambda 表达式就是一个 匿名函数对象, 可以被称为 匿名函数, 因为它没有函数名.
且, lambda 表达式 除了可以直接匿名使用之外, 还可以这样:
int main() {
vector<Goods> v = {
{"苹果", 2.1, 5},
{"香蕉", 3.1, 4},
{"橙子", 2.2, 3},
{"菠萝", 1.5, 4}
};
auto priceUp = [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price; };
sort(v.begin(), v.end(), priceUp);
cout << "价格升序" << endl;
printGoods(v);
return 0;
}
通过 auto 来对 lambda 表达式 定义一个变量. 这样 相应的 lambda 表达式 就可以通过此变量被调用.
认识了 lambda 表达式之后, 有关于 lambda 表达式的使用还有一些关于 捕捉列表 细节需要介绍.
我们使用 lambda 表达式, 尝试实现交换对象的值:
int main() {
int a = 10, b = 20;
cout << a << " " << b << endl;
auto lamSwap1 = [](int x, int y){
int tmp = x;
x = y;
y = tmp;
};
auto lamSwap2 = [](int& x, int& y){
int tmp = x;
x = y;
y = tmp;
};
lamSwap1(a, b);
cout << "lamSwap1:: "<< a << " " << b << endl;
lamSwap2(a, b);
cout << "lamSwap2:: "<< a << " " << b << endl;
return 0;
}
上面两个 lambda 表达式, 哪一个可以成功让 a 和 b 交换值?
一定是 lamSwap2, 因为 传入函数内的参数 如果是临时变量改变 不会影响到原数据. 而 lamSwap2 使用的是 左值引用.

直接传参可以实现交换数据.
不过我们还可以是用另外一种写法. 使用 捕捉列表
捕捉列表 描述了上下文中哪些数据可以在 lambda表达式作用域内 使用, 以及使用的方式传值还是传引用.
[var]:表示值传递方式捕捉变量var[=]:表示值传递方式捕获所有父作用域中的变量(包括this)[&var]:表示引用传递捕捉变量var[&]:表示引用传递捕捉所有父作用域中的变量(包括this)[this]:表示值传递方式捕捉当前的this指针
具体的使用如下:
int main() {
int a = 10, b = 20;
cout << a << " " << b << endl;
auto lamSwap1 = [a, b](){
int tmp = a;
a = b;
b = tmp;
};
auto lamSwap2 = [&a, &b](){
int tmp = a;
a = b;
b = tmp;
};
lamSwap1();
cout << "lamSwap1:: "<< a << " " << b << endl;
lamSwap2();
cout << "lamSwap2:: "<< a << " " << b << endl;
return 0;
}
此次的两个 lambda 表达式, 哪一个可以成功让 a 和 b 交换值?
lamSwap2 肯定可以, 不过 lamSwap1 可以吗?

很可惜, 这段代码编译无法通过, 并且 问题出在了 某个 lambda 表达式上.
是 lamSwap1. 我们在介绍 lambda 表达式的结构时 介绍过一个内容:
默认情况下,
lambda函数总是一个const函数, 即 它的捕捉的 值对象 可以被看作默认被const修饰.mutable可以取消其常量性. 使用该修饰符时,参数列表不可省略(即使参数为空)
在 lamSwap1 中, 我们捕捉的 [a, b] 就是 值对象. 所以, 此时 lamSwap1 内的 a 和 b 都是被 const 修饰的值.
所以是无法修改的. 要想在内部修改, 就要使用 mutable :
auto lamSwap1 = [a, b]()mutable{
int tmp = a;
a = b;
b = tmp;
};
修改之后:

可以看到, 可以编译通过. 但是 执行之后, 值并没有被交换. 因为, lamSwap1 是 传值捕捉.
所以, 其实 mutable 这个关键词, 显得很没有用.
传值捕捉 默认const修饰, 想要修改需要使用mutable. 但是使用之后, 又因为传值捕捉, 导致无法修改实际内容. 所以 mutable 好像没有什么太大作用.
不过, 现在我们知道了 []捕捉列表 的用法. 可以捕捉 父级作用域的对象, 让其可以在 lambda 表达式内部使用.
并且, 使用 [&var] 就是传引用捕捉, [var] 就是传值捕捉.
但是, 如果想要使用父级作用域的所有对象, 如果还需要一一显式捕捉的话, 就太繁琐了
所以, C++11还设计了, 使用 [&] 就是传引用捕捉所有父级作用域内的对象, 使用 [=] 就是传值捕捉所有父级作用域内的对象
并且, C++11还设计了 混合使用. 即, 可以实现类似下面这样的捕捉:
[&, a] // a对象传值捕捉, 其他父级作用域内的所有对象 传引用捕捉
[=, &a] // a对象传引用捕捉, 其他父级作用域的所有对象 传值捕捉
所以, lambda 表达式的使用, 实际上是非常灵活的.
但是, lambda 表达式 禁止重复捕捉:
[&, &a]
[&a, &a]
[=, a]
[a, a]
像类似上面的这些操作, 在某些编译器上 是会报错的:

GCC不会报错, 只会报出警告:
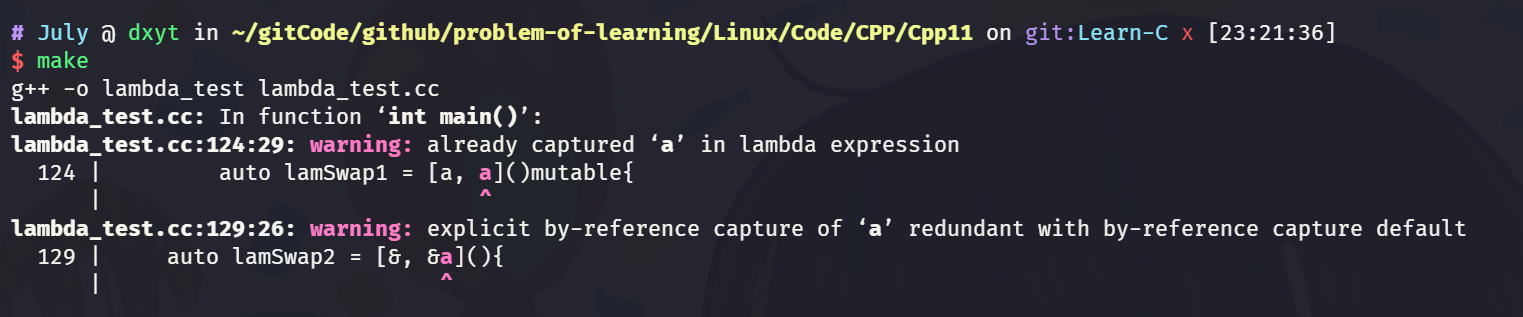
还有一点就是, lambda 表达式 只能捕捉父级作用域中的对象. 即 包含此 lambda 表达式的作用域
lambda 表达式底层
关于 lambda 表达式 还有一个非常重要的内容是 关于它的类型.
我们可以通过 auto 接收一个 lambda 表达式. 但是他究竟是什么呢?
lambda 表达式能不能相互赋值呢?
答案是, 不能
即使是像这样的 看起来几乎一样的 lambda 表达式, 也不能相互赋值:
int main() {
auto f1 = []{cout << "hello world" << endl; };
auto f2 = []{cout << "hello world" << endl; };
f1 = f2;
return 0;
}
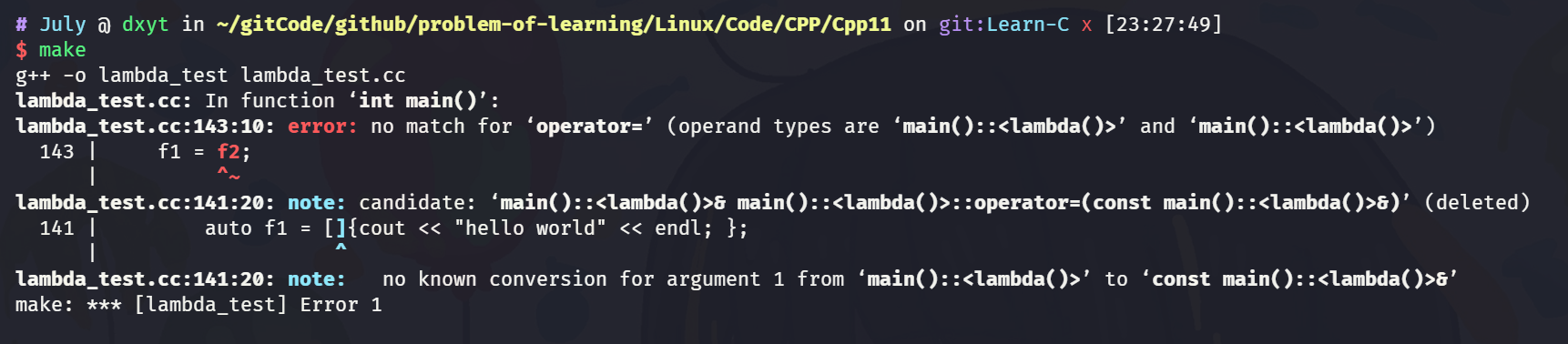
但是, 可以通过 拷贝构造的形式, 创建一个 lambda 表达式的副本.
也可以, 将 lambda 表达式赋值给一个 参数和返回值类型都相同的函数指针
void (*pF)();
int main() {
auto f1 = []{cout << "hello world" << endl; };
auto f2(f1);
f2();
pF = f1;
pF();
return 0;
}

这就是 lambda 表达式.
这是为什么呢?
为什么会出现 这一部分现象呢? 其实是由于 lambda 的底层实现 是 仿函数.
对, 就是可以像函数一样使用的对象, 就是在类中重载了 operator()运算符 的类对象
这一点, 可以在 VS中通过反汇编代码看出来:
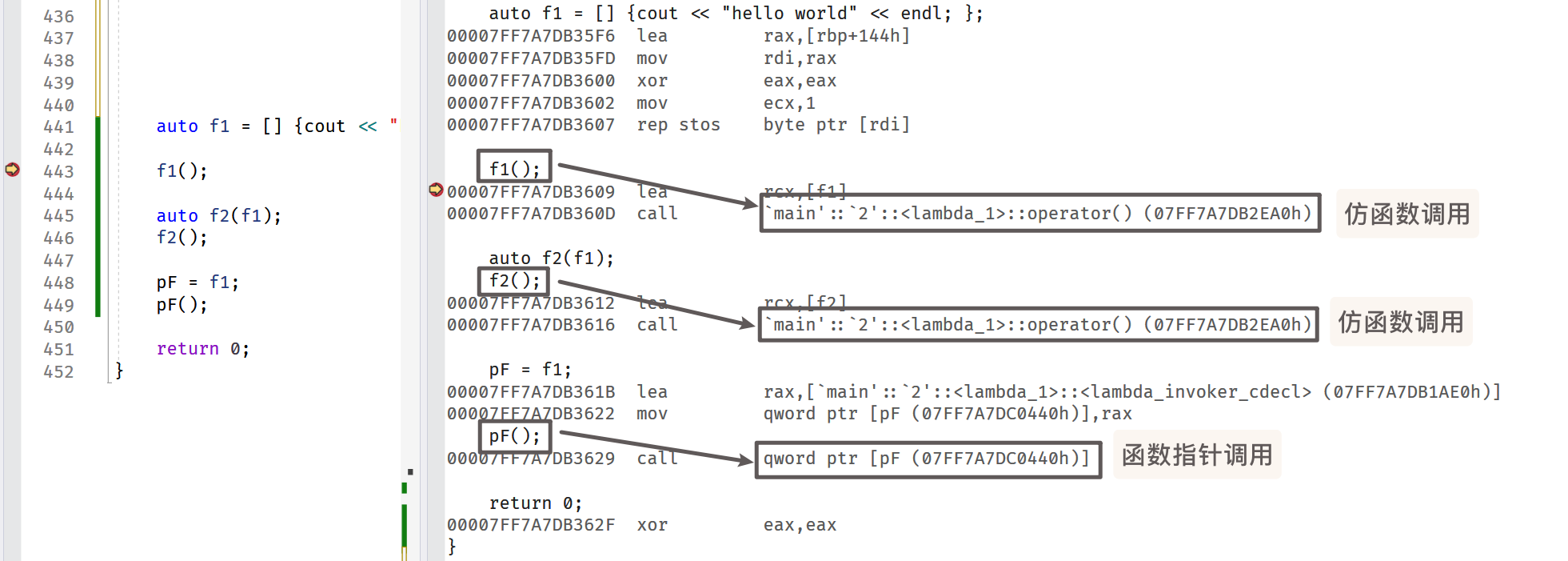
包装器 function
C++11 增添了 lambda 表达式之后.
C++中 可调用类型的对象就变成了三种: 函数指针, 仿函数, lambda
可以通过这三种对象 调用函数.
三种不同类型的可调用对象, 用法又非常的相似. 如果, 恰好模板有需求, 需要在不同场景 使用这三种不同类型的可调用对象, 怎么才能实现呢?
大概就像这样实现:
template<class F, class T>
T useF(F f, T x) {
static int count = 0; // static 用来记录实例化出的同一个函数被执行多少次
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i) {
return i / 2;
}
struct Functor {
double operator()(double d) {
return d / 3;
}
};
int main() {
// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lamber表达式
cout << useF([](double d)->double{ return d / 4; }, 11.11) << endl;
return 0;
}
useF() 模板中, 第一个模板参数是用来接收 可调用对象类型的.
当分别传入 函数名、函数对象、lambda 之后, 此模板会被实例化三个不同的函数:

可以发现, 在 useF() 内定义的 static 每次执行都是1, 且不同的地址.
这就说明 三次执行实例化了三个不同的 useF() 函数.
三种不同类型 传给模板, 实例化三个不同的函数, 非常的正常.
但是 这三种可调用对象的使用方式几乎一样, 通过一个模板 却需要 实例化三个不同的函数, 好像又有一点浪费.
所以, C++11 引入了 包装器
function 包装普通可调用对象
function包装器 也叫作 适配器.
C++11 之后, 设计了一个 std::function类模板, 也是一个包装器.

function 类模板:
-
第一个模板参数
Ret需要传入可调用对象的返回值类型 -
后面则是
模板可变参数包, 需要传入 可调用对象的参数类型列表 -
不过,
function类模板传参 不需要向其他类模板一样, 将参数用逗号隔开可以直接 这样传参
function< retType(paraType1, paraType2, paraType3, ...)>
可以使用 std::function 类模板 将 不同类型的可调用对象, 包装成一个类型 即 function 类型
使用时, 需要使用
#include <functional>包含functional头文件
#include <functional>
double f(double i) {
return i / 2;
}
struct Functor {
double operator()(double d) {
return d / 3;
}
};
int main() {
// 函数名
std::function<double(double)> func1 = f;
cout << "未使用包装器 f 类型" << typeid(f).name() << endl;
cout << "包装器后 类型" << typeid(func1).name() << endl << endl;
// 函数对象
std::function<double(double)> func2 = Functor();
cout << "未使用包装器 Functor() 类型" << typeid(Functor()).name() << endl;
cout << "包装器后 类型" << typeid(func2).name() << endl << endl;
// lamber表达式
std::function<double(double)> func3 = [](double d)->double{ return d / 4; };
auto lam1 = [](double d)->double{ return d / 4; };
cout << "未使用包装器 lambda 类型" << typeid(lam1).name() << endl;
cout << "包装器后 类型" << typeid(func3).name() << endl;
return 0;
}
这段代码的执行结果:

不用在意未使用包装器时, 究竟是什么类型. 只需要看到 使用包装器之后, 三种可调用对象的类型被统一了.
其实就是使用 不同的可调用对象 实例化了 function 对象. 都是同一个类模板, 肯定是相同的类型.
并且, 我们还可以通过 function 对象来执行 可调用对象的功能:
#include <functional>
double f(double i) {
return i / 2;
}
struct Functor {
double operator()(double d) {
return d / 3;
}
};
int main() {
// 函数名(函数指针)
std::function<double(double)> func1 = f;
cout << func1(1) << endl;
// 函数对象
std::function<double(double)> func2 = Functor();
cout << func2(4) << endl;
// lamber表达式
std::function<int(int, int)> func3 = [](const int a, const int b){ return a + b; };
cout << func3(1, 2) << endl;
return 0;
}

在对不同类型的 可调用对象包装之后, 可以将 function 对象, 传入给其他模板共其使用:
#include <iostream>
#include <functional>
using std::cout;
using std::endl;
template<class F, class T>
T useF(F f, T x) {
static int count = 0; // static 用来记录实例化出的同一个函数被执行多少次
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i) {
return i / 2;
}
struct Functor {
double operator()(double d) {
return d / 3;
}
};
int main() {
// 函数名
std::function<double(double)> func1 = f;
cout << useF(func1, 11.11) << endl << endl;
// 函数对象
std::function<double(double)> func2 = Functor();
cout << useF(func2, 11.11) << endl << endl;
// lamber表达式
std::function<double(double)> func3 = [](double d)->double{ return d / 4; };
cout << useF(func3, 11.11) << endl;
}
这段代码的执行结果:

可以看出, 此时 useF 函数模板 只实例化出了一个函数. 因为, 同一个 count 被 ++、输出了 3 次
function 包装类内成员函数
function 包装器, 除了可以包装这三种基础的可调用对象之外. 还可以包装 类内的成员函数:
class Plus{
public:
static int plusi(int a, int b) {
return a + b;
}
double plusd(double a, double b) {
return a + b;
}
};
int main() {
// 包装静态成员变量
std::function<int(int, int)> func1 = Plus::plusi;
cout << func1(1, 2) << endl;
// 包赚非静态成员变量
std::function<double(Plus, double, double)> func2 = &Plus::plusd;
cout << func2(Plus(), 3.3, 4.4) << endl;
return 0;
}
这段代码的执行结果是:

是可以正常执行相应的函数的.
不过, 通过观察代码 就可以发现, 包装静态成员函数 和 包装非静态成员函数 的方式是 存在不同的
静态成员函数, 因为 不存在隐含的this指针, 本身就可以直接通过类名调用, 比如 Plus::plusi(1, 2). 所以在 实例化 function 对象 进行包装时, 不用在参数中 传入一个 Plus 对象. 并且, 不需要取地址包装.
而 非静态成员函数, 由于是类内函数且非静态 第一个参数是隐含的this指针, 所以需要 通过对象调用. 所以 在进行包装时, 第一个参数是需要指定类的, 并且在使用时, 需要传入一个对象, 例子中使用了 Plus() 来传递匿名对象. 并且, 需要取地址包装.
bind()
什么是 bind() ?

C++中, bind() 是一个函数模板,它可以 接受一个可调用对象, 生成一个新的可调用对象来“适应”原对象的参数列表
什么意思呢?
直接看一个使用例子:
#include <functional>
int Sub1(int a, int b) {
return a - b;
}
int main() {
std::function<int(int, int)> func1 = std::bind(Sub1, std::placeholders::_1, std::placeholders::_2);
cout << func1(4, 8) << endl;
std::function<int(int, int)> func2 = std::bind(Sub1, std::placeholders::_2, std::placeholders::_1);
cout << func2(4, 8) << endl;
return 0;
}
这段代码的执行结果:

我们通过 std::bind() 绑定了 Sub1() 函数, 并将其包装.
不过, std::bind() 的参数传递, 有一些差别. 导致 包装之后的 函数的执行结果不同.
bind() 使用 及 功能
那么, bind() 的功能究竟是什么呢?
1. 调整参数位置
相信大多数人看不懂上面的例子的原因是因为 std::placeholders::_1 和 std::placeholders::_2. 第一个参数容易理解, 就是需要 bind() 的可调用对象.
那么 std::placeholders::_n 是什么意思呢?
解释之前, 先来看一张图, 看完图或许可以直接理解:

看了还是不理解. 那就要 再介绍一下 bind() 的作用了.
接受一个可调用对象, 生成一个新的可调用对象来“适应”原对象的参数列表
bind() 的第一个参数, 就是接受的可调用对象. 而 后面的 std::placeholders::_n 其实表示的是 可调用对象对应的参数
std::placeholders::_1, 表示 可调用对象的第一个参数
std::placeholders::_2, 表示 可调用对象的第二个参数
std::placeholders::_3, 表示 可调用对象的第三个参数, 以此类推.
那么在上述例子中:
-
std::bind(Sub1, std::placeholders::_1, std::placeholders::_2)_1表示Sub1()的第一个参数,_2表示Sub1()的第一个参数那么,
bind()执行之后, 获得的函数就是Sub1(int a, int b), 函数体不变. -
std::bind(Sub1, std::placeholders::_2, std::placeholders::_1)同样的,
_1表示Sub1()的第一个参数,_2表示Sub1()的第一个参数那么, 此次
bind()执行之后, 获得的函数就是Sub1(int b, int a), 函数体不变.
Sub1() 的函数体是 reutn b - a;
当我们执行 func1(4, 8), func1() <==> Sub1(int a, int b), 所以 结果是 8 - 4 = 4
当我们执行 func2(4, 8), func2() <==> Sub2(int b, int a), 所以 结果是 4 - 8 = -4
所以, std::placeholders::_n 强绑定了 所接受的可调用对象的参数的位置. bind() 后面的参数, 表示了 bind() 执行之后的可调用对象的参数位置
2. 绑定参数
类的非静态成员函数, 因为第一个参数默认为this指针 且无法更改. 所以 在包装时, 需要将包装的函数的第一个参数类型 指明为类. 且在使用时需要传入一个对象.
而 bind() 的作用是 接受一个可调用对象, 生成一个新的可调用对象来“适应”原对象的参数列表
所以, 我们还可以使用 bind(), 将 类的对象 绑定在类的成员函数上, 以便之后使用时 不在手动传入对象:
#include <functional>
class Sub {
public:
int sub(int a, int b) {
return a - b;
}
};
int main() {
Sub s;
// 绑定成员函数
std::function<int(int, int)> func = std::bind(&Sub::sub, s, placeholders::_1, placeholders::_2);
cout << func(3, 4) << endl;
return 0;
}
这段代码的执行结果:

std::bind(&Sub::sub, s, placeholders::_1, placeholders::_2) 通过 在 this 指针的位置 直接传入一个对应类对象.
包装时 就不用在相应位置指定类, 包装之后, 使用包装完成的对象执行可调用对象, 也不用再显式传入一个类对象.
这 才是 bind() 真正常用的功能. 调整参数位置 相应的没有那么常用.
而且, 通过此功能还可以了解到, std::placeholders::_n 占位符 是不包括 this 指针的.