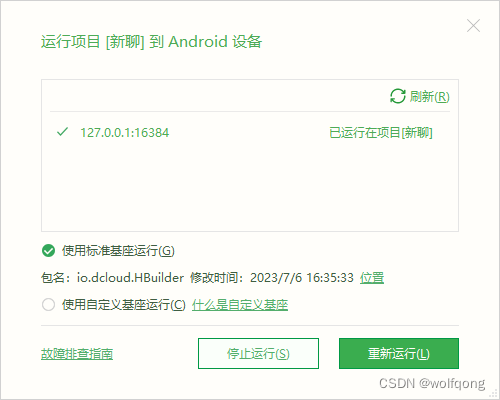
是什么
任何时候对于动态系统存在不确定信息,都可使用卡尔曼滤波(Kalman Filter,下面简称为KF)对系统下一步要做什么做出有根据的猜测。
KF对于连续变化的系统是理想的,优点是占用内存小而且速度快,非常适用于实时问题和嵌入式系统。
使用KF可以干啥
举例:制造了一个可以在树林里游荡的小机器人,它需要知道自己的确切位置,这样它才能导航。
假设机器人状态表示为向量
x
k
→
\overrightarrow{x_k}
xk,包含位置和速度:
x
k
→
=
(
p
⃗
,
v
⃗
)
\overrightarrow{x_k}=(\vec{p}, \vec{v})
xk=(p,v)
状态可以是任何想要追踪的东西。
我们可以从GPS传感器及我们发送给机器人的指令来获取机器人的状态,但是这两个来源都存在一定的不确定性和误差。
如果利用所有可以获取到的信息,可能会给出更好的判断,这就是KF的作用。
KF如何看待我们的问题
继续使用一个仅有位置和速度的简单状态
x
⃗
=
[
p
v
]
\vec{x}=\left[\begin{array}{l} p \\ v \end{array}\right]
x=[pv]
我们不知道实际的位置和速度是多少;位置和速度的组合有很多,但其中一些比其他的可能性更大
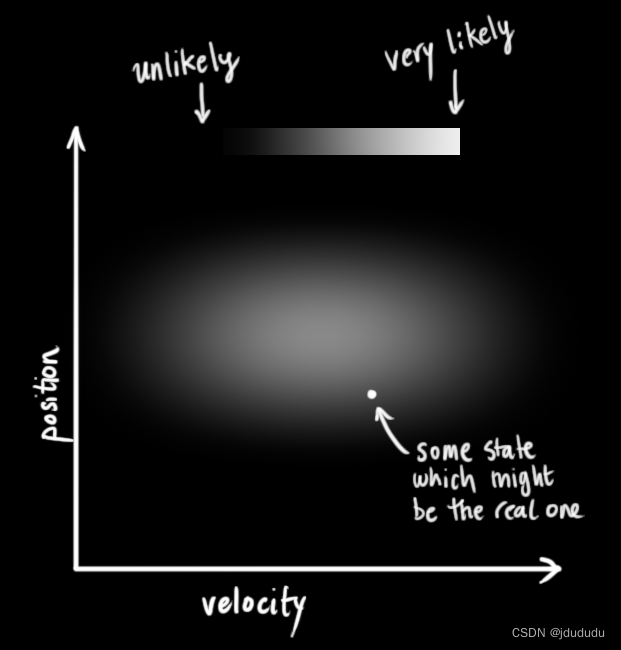
KF假设两个变量都是随机的并且符合高斯分布,每个变量都有平均值KaTeX parse error: Undefined control sequence: \μ at position 1: \̲μ̲(随机分布的中心)和方差
σ
2
\sigma^2
σ2(不确定性)
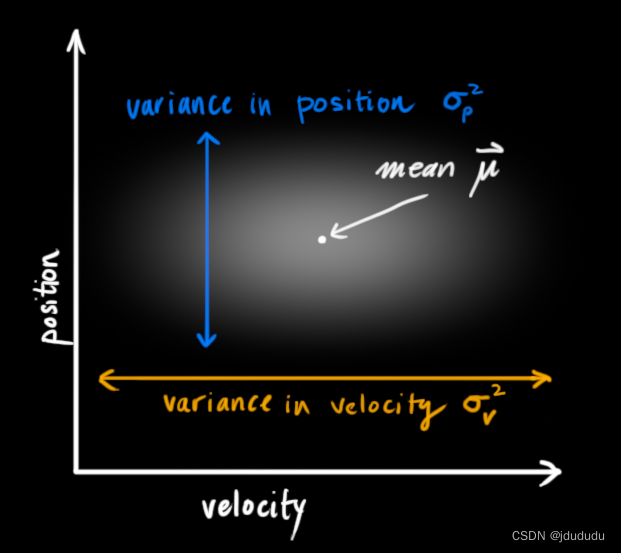
在上图中,位置和速度是不相关的。
下图中位置和速度是相关的,观察到特定位置的可能性与速度有关。
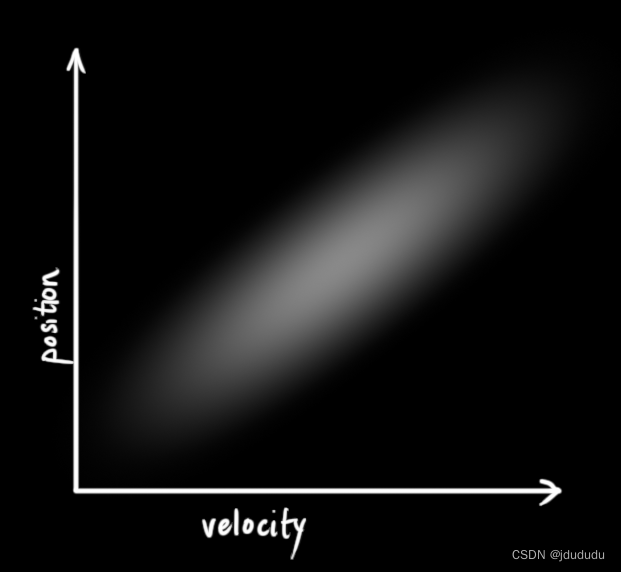
追踪这种关系可以给我们提供更多的信息,一个测量值告诉我们其他测量值可能是什么。这就是卡尔曼滤波器的目标,我们想要从不确定的测量中尽可能多地压缩信息!
这种相关性由协方差矩阵表示,矩阵的每个元素 Σ i j \Sigma_{i j} Σij表示第i个状态变量和第j个状态变量的相关程度。协方差矩阵是对称阵,由 Σ \Sigma Σ表示,每个元素表示为 Σ i j \Sigma_{i j} Σij。
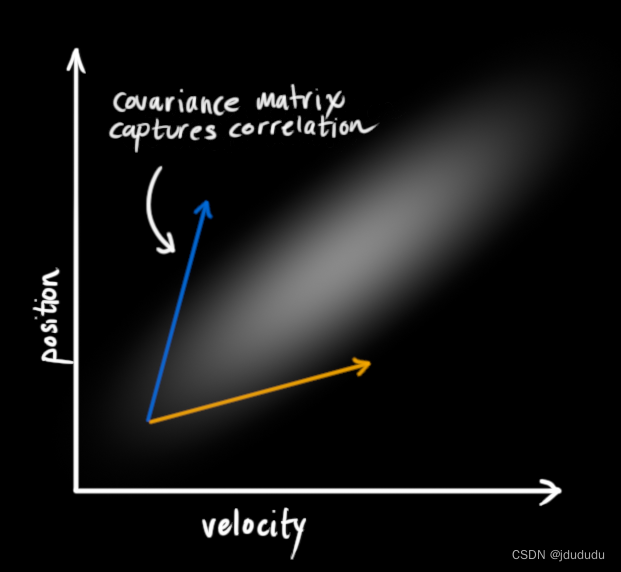
使用矩阵描述问题
要将关于状态的知识建模成高斯分布,需要知道 k k k时刻的两条信息:最佳估计 x ^ k \hat{\mathbf{x}}_{\mathbf{k}} x^k(平均值)和它的协方差矩阵 P k \mathbf{P}_{\mathbf{k}} Pk。
x ^ k = [ position velocity ] P k = [ Σ p p Σ p v Σ v p Σ v v ] \hat{\mathbf{x}}_k=\left[\begin{array}{l} \text { position } \\ \text { velocity } \end{array}\right] \mathbf{P}_k=\left[\begin{array}{ll} \Sigma_{p p} & \Sigma_{p v} \\ \Sigma_{v p} & \Sigma_{v v} \end{array}\right] x^k=[ position velocity ]Pk=[ΣppΣvpΣpvΣvv]
随后,需要一种方式来看当前状态( k − 1 k-1 k−1时刻)并预测下个状态( k k k时刻)
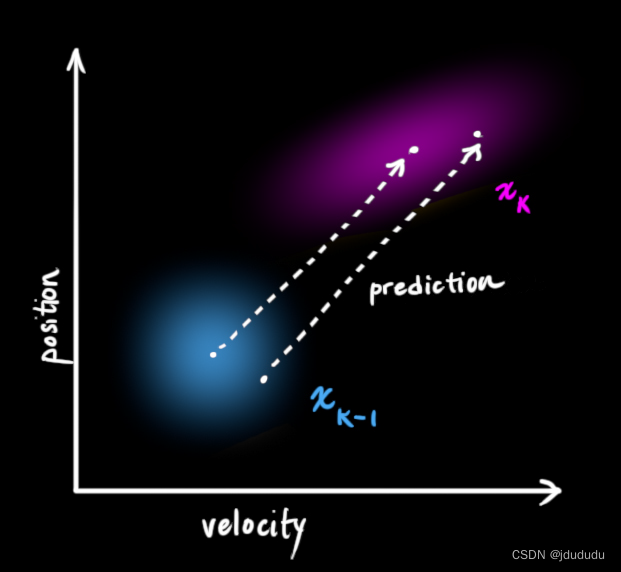
可以用矩阵
F
k
\mathbf{F}_{\mathbf{k}}
Fk来表示这个预测步骤
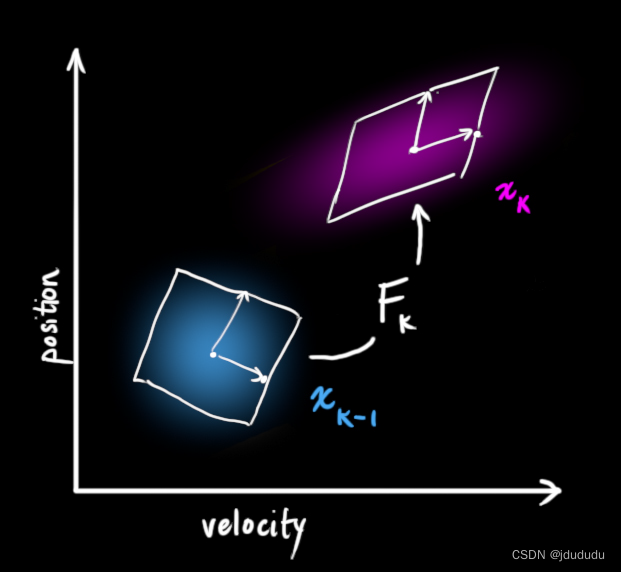
它将原始估计中的每个点移动到一个新的预测位置,如果原始估计是正确的,系统就会移动到这个位置。
使用运动学公式预测下一时刻的位置和速度
p
k
=
p
k
−
1
+
Δ
t
v
k
−
1
v
k
=
v
k
−
1
\begin{array}{lr} p_k=p_{k-1}+\Delta t v_{k-1} \\ v_k= v_{k-1} \end{array}
pk=pk−1+Δtvk−1vk=vk−1
写成矩阵形式
x
^
k
=
[
1
Δ
t
0
1
]
x
^
k
−
1
=
F
k
x
^
k
−
1
\begin{aligned} \hat{\mathbf{x}}_k & =\left[\begin{array}{cc} 1 & \Delta t \\ 0 & 1 \end{array}\right] \hat{\mathbf{x}}_{k-1} \\ & =\mathbf{F}_k \hat{\mathbf{x}}_{k-1} \end{aligned}
x^k=[10Δt1]x^k−1=Fkx^k−1
现在有了预测矩阵给出下一状态,但是仍然不知如何更新协方差矩阵。
首先记住一个公式:
Cov
(
x
)
=
Σ
Cov
(
A
x
)
=
A
Σ
A
T
\begin{aligned} \operatorname{Cov}(x) & =\Sigma \\ \operatorname{Cov}(\mathbf{A} x) & =\mathbf{A} \Sigma \mathbf{A}^T \end{aligned}
Cov(x)Cov(Ax)=Σ=AΣAT
将上面两个式子结合,可得
x
^
k
=
F
k
x
^
k
−
1
P
k
=
F
k
P
k
−
1
F
k
T
\begin{aligned} \hat{\mathbf{x}}_k & =\mathbf{F}_k \hat{\mathbf{x}}_{k-1} \\ \mathbf{P}_k & =\mathbf{F}_{\mathbf{k}} \mathbf{P}_{k-1} \mathbf{F}_k^T \end{aligned}
x^kPk=Fkx^k−1=FkPk−1FkT
外部影响
可能还会存在一些与状态无关的变化,外界世界可能也会影响系统
例如,如果状态模拟火车的运动,火车操作员可能会推油门,导致火车加速。
将这些外部世界的影响装入一个 u k → \overrightarrow{\mathrm{u}_k} uk向量中,将其作为预测的修正项。
假如已知加速度
a
a
a,由运动学公式:
p
k
=
p
k
−
1
+
Δ
t
v
k
−
1
+
1
2
a
Δ
t
2
v
k
=
v
k
−
1
+
a
Δ
t
\begin{aligned} & p_k=p_{k-1}+\Delta t v_{k-1}+\frac{1}{2} a \Delta t^2 \\ & v_k=\quad v_{k-1}+a \Delta t \end{aligned}
pk=pk−1+Δtvk−1+21aΔt2vk=vk−1+aΔt
x
^
k
=
F
k
x
^
k
−
1
+
[
Δ
t
2
2
Δ
t
]
=
F
k
x
^
k
−
1
+
B
k
u
k
→
\begin{aligned} \hat{\mathbf{x}}_k & =\mathbf{F}_k \hat{\mathbf{x}}_{k-1}+\left[\begin{array}{c} \frac{\Delta t^2}{2} \\ \Delta t \end{array}\right] \\ & =\mathbf{F}_k \hat{\mathbf{x}}_{k-1}+\mathbf{B}_k \overrightarrow{u_k} \end{aligned}
x^k=Fkx^k−1+[2Δt2Δt]=Fkx^k−1+Bkuk
B
k
\mathbf{B}_k
Bk被称为控制矩阵,
u
k
→
\overrightarrow{\mathrm{u}_k}
uk被称为运动向量,对于没有外部影响的系统可以省略这些项。
外部不确定性
例如如果我们跟踪一架四轴飞行器,它可能会受到风的冲击。如果我们追踪的是轮式机器人,轮子可能会打滑,或者地面上的颠簸会让它减速。我们无法跟踪这些事情,如果这些发生了,我们的预测可能会出错,因为我们没有考虑这些额外的力。
可以在每个预测步骤之后加上一些不确定性来对不确定性进行建模
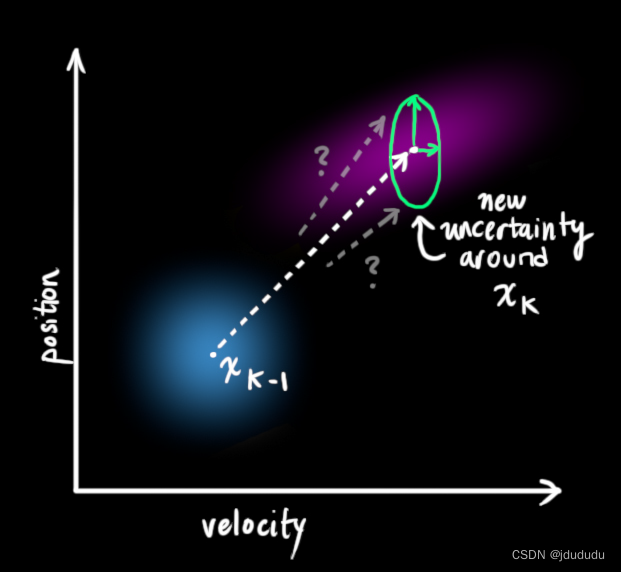
可以说每个点
x
^
k
−
1
\hat{\mathbf{x}}_{k-1}
x^k−1都被移动到一个协方差为
Q
k
\mathbf{Q}_k
Qk的高斯分布中的某处,也可以说我们将未知的外部影响当作具有协方差
Q
k
\mathbf{Q}_k
Qk的噪声。
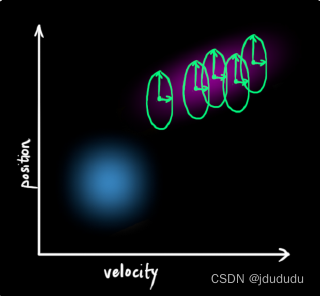
这将会产生一个与之前具有不同协方差和相同平均值的高斯分布。
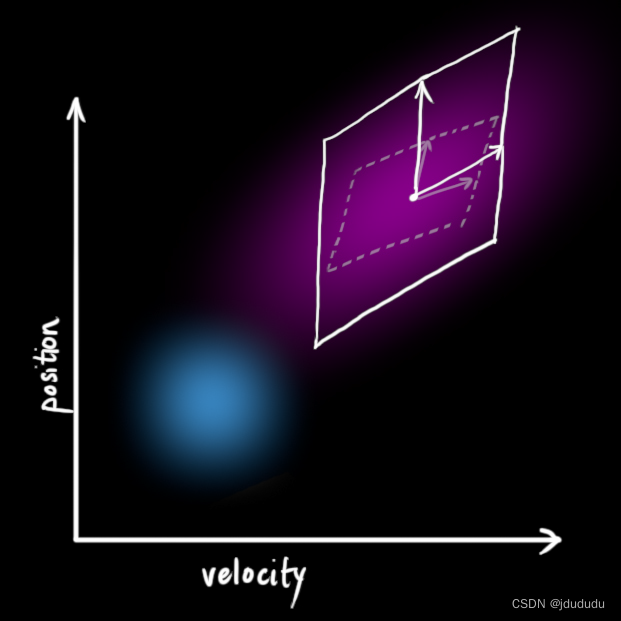
现在预测步骤可以表示为:
x
^
k
=
F
k
x
^
k
−
1
+
B
k
u
k
→
P
k
=
F
k
P
k
−
1
F
k
T
+
Q
k
\begin{aligned} \hat{\mathbf{x}}_k & =\mathbf{F}_k \hat{\mathbf{x}}_{k-1}+\mathbf{B}_k \overrightarrow{u_k} \\ \mathbf{P}_k & =\mathbf{F}_{\mathbf{k}} \mathbf{P}_{k-1} \mathbf{F}_k^T+\mathbf{Q}_k \end{aligned}
x^kPk=Fkx^k−1+Bkuk=FkPk−1FkT+Qk
也就是说新的最佳估计是由以前的最佳估计做出的预测加上对已知外部影响的修正
而新的不确定性是从旧的不确定性中预测出来的,还有一些来自环境的额外不确定性。
现在由 x ^ k \hat{\mathbf{x}}_k x^k和 P k \mathbf{P}_k Pk可以对系统将来的状态有一个模糊的估计。
如果能从传感器获取一些信息,会发生什么呢?
通过测量细化估计
使用矩阵
H
k
\mathbf{H}_k
Hk表示传感器。
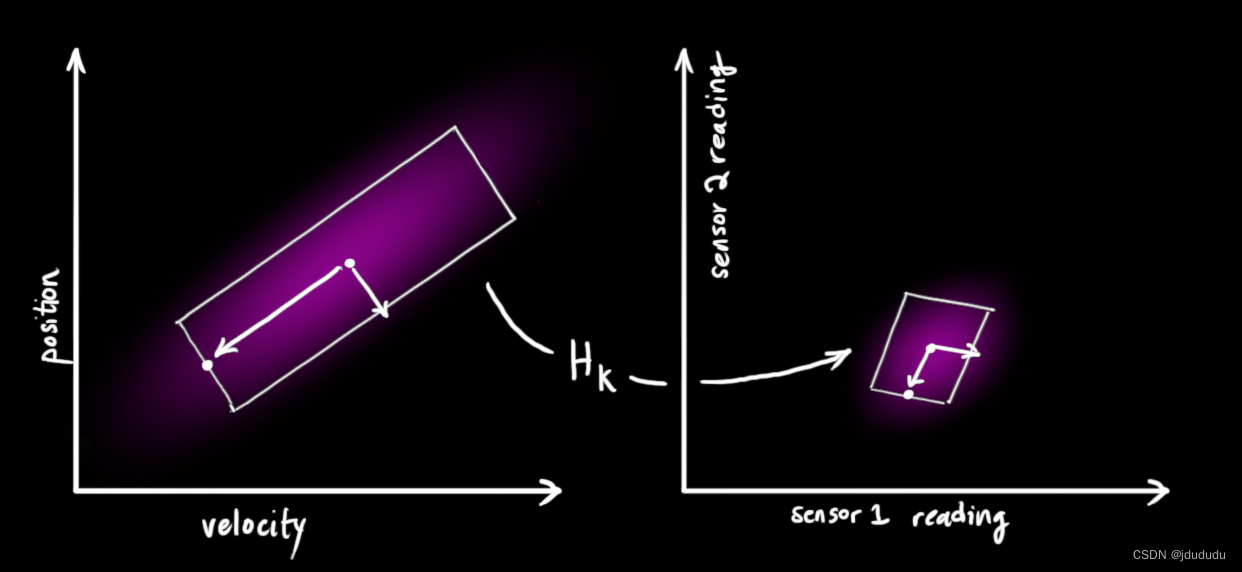
可以用通常的方式表示出传感器读数分布:
μ
⃗
expected
=
H
k
x
^
k
Σ
expected
=
H
k
P
k
H
k
T
\begin{aligned} \vec{\mu}_{\text {expected }} & =\mathbf{H}_k \hat{\mathbf{x}}_k \\ \boldsymbol{\Sigma}_{\text {expected }} & =\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T \end{aligned}
μexpected Σexpected =Hkx^k=HkPkHkT
KF很擅长处理传感器噪声,换句话说传感器多少都有点不可靠,最初估计的每个状态可能都会导致一定范围的传感器读数。
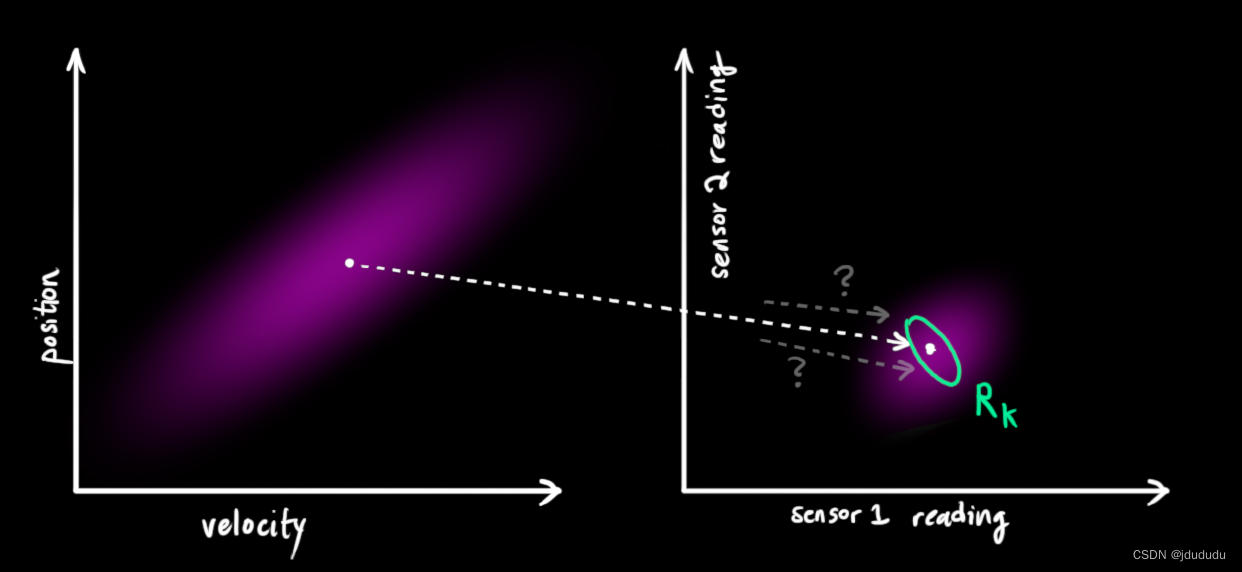
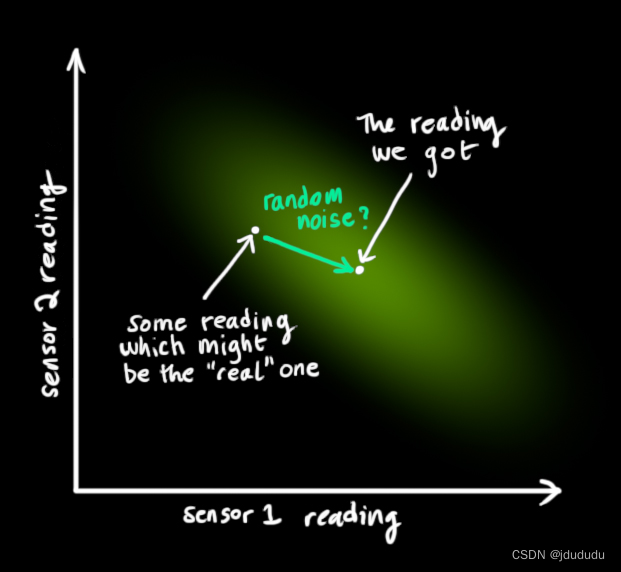
不确定性的协方差用
R
k
\mathbf{R}_k
Rk表示,分布的平均值就是我们观察到的读数,用
Z
k
→
\overrightarrow{\mathbf{Z}_k}
Zk表示
所以现在有两个高斯分布,一个围绕着转换后预测值的平均值,一个围绕着真实的传感器读数。
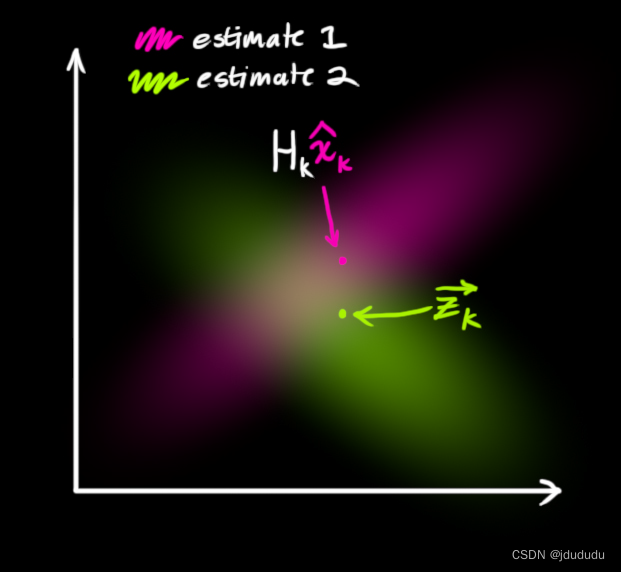
必须试着调和上面的两个值。
什么是最可能的状态呢?对于任何可能的读数 ( z 1 , z 2 ) \left(z_1, z_2\right) (z1,z2),需要下面两种可能性都满足,一个是传感器读数 z k → \overrightarrow{\mathbf{z}_k} zk是错误测量的可能性;另一个是之前的估计认为 ( z 1 , z 2 ) \left(z_1, z_2\right) (z1,z2)是该看到的读数的可能性。
由概率相关的知识,上述两个可能性都为真的概率就是将两者的概率相乘,所以将两个高斯分布相乘。
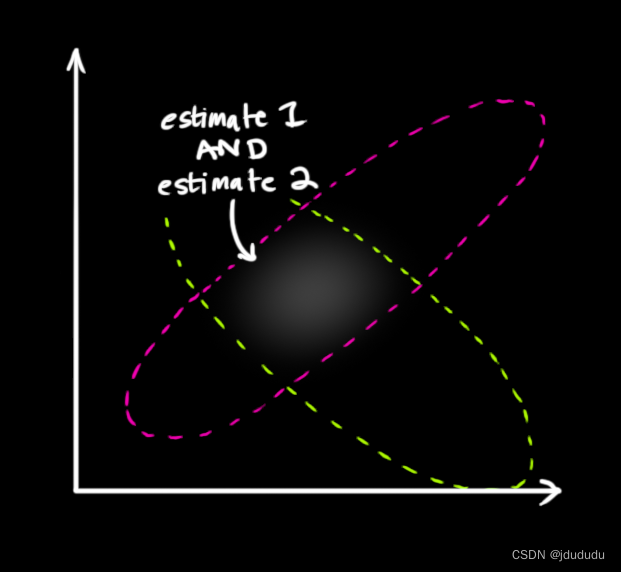
上图中重叠的部分比之前的估计都精确的多,该部分的均值就是两种估计最可能出现的情况,也能给出在现有信息的情况下对于真实状态的最佳猜测。
这就出现了另一个高斯分布
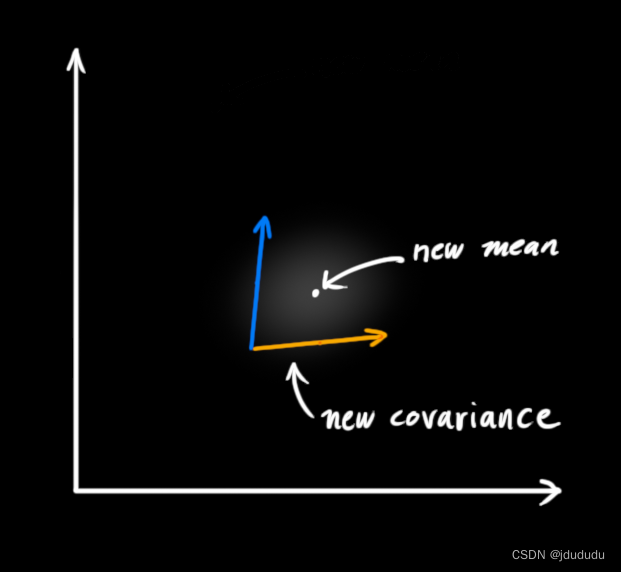
也就是说,将两个高斯分布相乘,得到的是一个新的高斯分布。
组合高斯分布
从一维的角度来看,公式为
N
(
x
,
μ
,
σ
)
=
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
\mathcal{N}(x, \mu, \sigma)=\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{(x-\mu)^2}{2 \sigma^2}}
N(x,μ,σ)=σ2π1e−2σ2(x−μ)2
蓝色曲线就是红绿相乘得到的高斯曲线
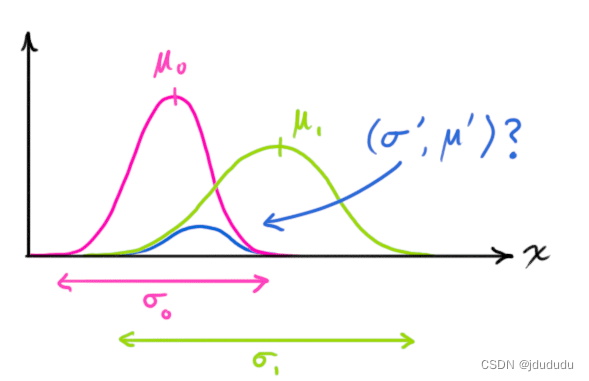
N
(
x
,
μ
0
,
σ
0
)
⋅
N
(
x
,
μ
1
,
σ
1
)
=
?
N
(
x
,
μ
′
,
σ
′
)
\mathcal{N}\left(x, \mu_0, \sigma_0\right) \cdot \mathcal{N}\left(x, \mu_1, \sigma_1\right) \stackrel{?}{=} \mathcal{N}\left(x, \mu^{\prime}, \sigma^{\prime}\right)
N(x,μ0,σ0)⋅N(x,μ1,σ1)=?N(x,μ′,σ′)
经过推导,可得
k
=
σ
0
2
σ
0
2
+
σ
1
2
μ
′
=
μ
0
+
k
(
μ
1
−
μ
0
)
σ
′
2
=
σ
0
2
−
k
σ
0
2
\begin{aligned} \mathbf{k} & =\frac{\sigma_0^2}{\sigma_0^2+\sigma_1^2} \\ \mu^{\prime} & =\mu_0+\mathbf{k}\left(\mu_1-\mu_0\right) \\ {\sigma^{\prime}}^2 & =\sigma_0^2-\mathbf{k} \sigma_0^2 \end{aligned}
kμ′σ′2=σ02+σ12σ02=μ0+k(μ1−μ0)=σ02−kσ02
写成矩阵形式如下:
K
=
Σ
0
(
Σ
0
+
Σ
1
)
−
1
μ
⃗
′
=
μ
0
→
+
K
(
μ
1
→
−
μ
0
→
)
Σ
′
=
Σ
0
−
K
Σ
0
\begin{aligned} & \mathbf{K}=\Sigma_0\left(\Sigma_0+\Sigma_1\right)^{-1} \\ & \vec{\mu}^{\prime}=\overrightarrow{\mu_0}+\mathbf{K}\left(\overrightarrow{\mu_1}-\overrightarrow{\mu_0}\right) \\ & \Sigma^{\prime}=\Sigma_0-\mathbf{K} \Sigma_0 \end{aligned}
K=Σ0(Σ0+Σ1)−1μ′=μ0+K(μ1−μ0)Σ′=Σ0−KΣ0
矩阵 K \mathbf{K} K被称为卡尔曼增益
进行组合
将之前的两个分布:预测值
(
μ
0
,
Σ
b
)
=
(
H
k
x
^
k
,
H
k
P
k
H
k
T
)
\left(\mu_0, \Sigma \mathrm{b}\right)=\left(\mathbf{H}_k \hat{\mathbf{x}}_k, \mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T\right)
(μ0,Σb)=(Hkx^k,HkPkHkT)和观测值
(
μ
1
,
Σ
1
)
=
(
z
k
→
,
R
k
)
\left(\mu_1, \Sigma_1\right)=\left(\overrightarrow{\mathbf{z}_k}, \mathbf{R}_k\right)
(μ1,Σ1)=(zk,Rk),代入上面的式子,可以得到重叠:
H
k
x
^
k
′
=
H
k
x
^
k
+
K
(
z
k
→
−
H
k
x
^
k
)
H
k
P
k
′
H
k
T
=
H
k
P
k
H
k
T
−
K
H
k
P
k
H
k
T
\begin{aligned} \mathbf{H}_k \hat{\mathbf{x}}_k^{\prime} & =\mathbf{H}_k \hat{\mathbf{x}}_k & & +\mathbf{K}\left(\overrightarrow{\mathbf{z}_k}-\mathbf{H}_k \hat{\mathbf{x}}_k\right) \\ \mathbf{H}_k \mathbf{P}_k^{\prime} \mathbf{H}_k^T & =\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T & & -\mathbf{K H}_k \mathbf{P}_k \mathbf{H}_k^T \end{aligned}
Hkx^k′HkPk′HkT=Hkx^k=HkPkHkT+K(zk−Hkx^k)−KHkPkHkT
卡尔曼增益为
K
=
H
k
P
k
H
k
T
(
H
k
P
k
H
k
T
+
R
k
)
−
1
\mathbf{K}=\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T\left(\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T+\mathbf{R}_k\right)^{-1}
K=HkPkHkT(HkPkHkT+Rk)−1
将上面的式子进行化简可得
x
^
k
′
=
x
^
k
+
K
′
(
z
k
→
−
H
k
x
^
k
)
P
k
′
=
P
k
−
K
′
H
k
P
k
K
′
=
P
k
H
k
T
(
H
k
P
k
H
k
T
+
R
k
)
−
1
\begin{gathered} \hat{\mathbf{x}}_k^{\prime}=\hat{\mathbf{x}}_k+\mathbf{K}^{\prime}\left(\overrightarrow{\mathbf{z}_k}-\mathbf{H}_k \hat{\mathbf{x}}_k\right) \\ \mathbf{P}_k^{\prime}=\mathbf{P}_k-\mathbf{K}^{\prime} \mathbf{H}_k \mathbf{P}_k \\ \mathbf{K}^{\prime}=\mathbf{P}_k \mathbf{H}_k^T\left(\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T+\mathbf{R}_k\right)^{-1} \end{gathered}
x^k′=x^k+K′(zk−Hkx^k)Pk′=Pk−K′HkPkK′=PkHkT(HkPkHkT+Rk)−1
上面的式子给出了更新步骤,这样
x
^
k
′
\hat{\mathbf{x}}_k^{\prime}
x^k′就是新的最佳估计,然后就可以继续进行多次的预测和更新。
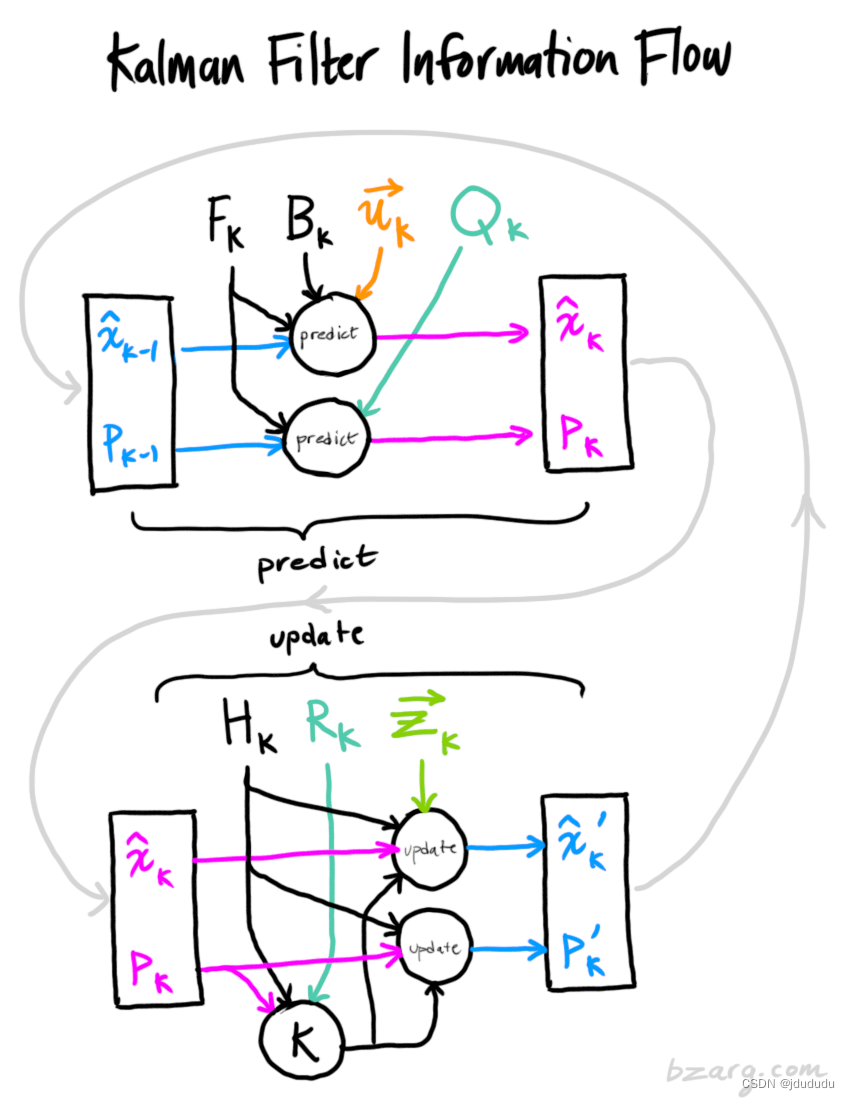
整个过程如上图。
总结
所有需要记住的式子就是:
x
^
k
=
F
k
x
^
k
−
1
+
B
k
u
k
→
P
k
=
F
k
P
k
−
1
F
k
T
+
Q
k
\begin{aligned} \hat{\mathbf{x}}_k & =\mathbf{F}_k \hat{\mathbf{x}}_{k-1}+\mathbf{B}_k \overrightarrow{\mathbf{u}_k} \\ \mathbf{P}_k & =\mathbf{F}_{\mathbf{k}} \mathbf{P}_{k-1} \mathbf{F}_k^T+\mathbf{Q}_k \end{aligned}
x^kPk=Fkx^k−1+Bkuk=FkPk−1FkT+Qk
和
x
^
k
′
=
x
^
k
+
K
′
(
z
k
→
−
H
k
x
^
k
)
P
k
′
=
P
k
−
K
′
H
k
P
k
\begin{aligned} \hat{\mathbf{x}}_k^{\prime} & =\hat{\mathbf{x}}_k+\mathbf{K}^{\prime}\left(\overrightarrow{\mathbf{z}_k}-\mathbf{H}_k \hat{\mathbf{x}}_k\right) \\ \mathbf{P}_k^{\prime} & =\mathbf{P}_k-\mathbf{K}^{\prime} \mathbf{H}_k \mathbf{P}_k \end{aligned}
x^k′Pk′=x^k+K′(zk−Hkx^k)=Pk−K′HkPk
和
K
′
=
P
k
H
k
T
(
H
k
P
k
H
k
T
+
R
k
)
−
1
\mathbf{K}^{\prime}=\mathbf{P}_k \mathbf{H}_k^T\left(\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T+\mathbf{R}_k\right)^{-1}
K′=PkHkT(HkPkHkT+Rk)−1
这些就可以用来对任何线性系统进行建模,对于非线性系统可以使用扩展的KF
简而言之
KF的核心过程如下图:
上述两个状态逐渐迭代罢了
代码实现
#include <iostream>
#include <math.h>
#include <tuple>
using namespace std;
double new_mean, new_var;
// 更新:传感器获取到比较准确的位置信息后来更新当前的预测位置,也就是纠正预测的错误。
tuple<double, double> measurement_update(double mean1, double var1, double mean2, double var2)
{
new_mean = (var2 * mean1 + var1 * mean2)/(var1 + var2);
new_var = 1 / (1 / var1 + 1 / var2);
return make_tuple(new_mean, new_var);
}
// 预测:当前状态环境下,对下一个时间段t的位置估计计算的值。
tuple<double, double> state_prediction(double mean1, double var1, double mean2, double var2)
{
new_mean = mean1 + mean2;
new_var = var1 + var2;
return make_tuple(new_mean, new_var);
}
int main()
{
//Measurements and measurement variance
double measurements[5] = {5, 6, 7, 8, 9};
double measurement_sig = 4;
//Motions and motion variance
double motion[5] = {1, 1, 2, 1, 1};
double motion_sig = 2;
//Initial state
double mu = 0;
double sig = 1000;
for (int i=0; i<sizeof(measurements)/sizeof(measurements[0]); i++)
{
tie(mu, sig) = measurement_update(mu, sig, measurements[i], measurement_sig);
printf("update: [%f, %f]\n", mu, sig);
tie(mu, sig) = state_prediction(mu, sig, motion[i], motion_sig);
printf("predict: [%f, %f]\n", mu, sig);
}
return 0;
}