承接上篇文章
大数据之数据采集项目总结——hadoop,hive,openresty,frcp,nginx,flume
https://blog.csdn.net/qq_43759478/article/details/131520375?spm=1001.2014.3001.5501
在上个阶段:完成了数据收集,使用flume把日志文件上传到hdfs,并且使用hive创建了分区表
。
现在补充:使用sqoop把hdfs/hive中的数据导出到MySQL中。
总览:
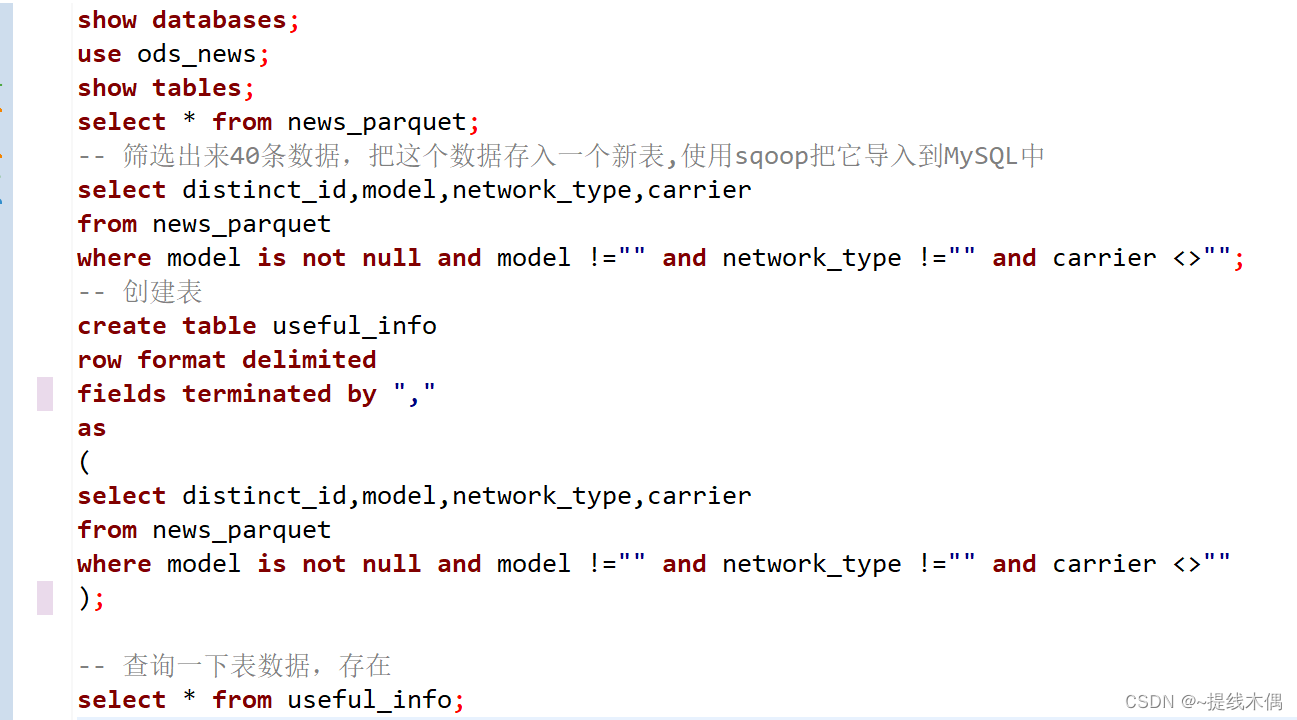
show databases;
use ods_news;
show tables;
select * from news_parquet;
-- 筛选出来40条数据,把这个数据存入一个新表,使用sqoop把它导入到MySQL中
select distinct_id,model,network_type,carrier
from news_parquet
where model is not null and model !="" and network_type !="" and carrier <>"";
-- 创建表
create table useful_info
row format delimited
fields terminated by ","
as
(
select distinct_id,model,network_type,carrier
from news_parquet
where model is not null and model !="" and network_type !="" and carrier <>""
);
-- 查询一下表数据,存在
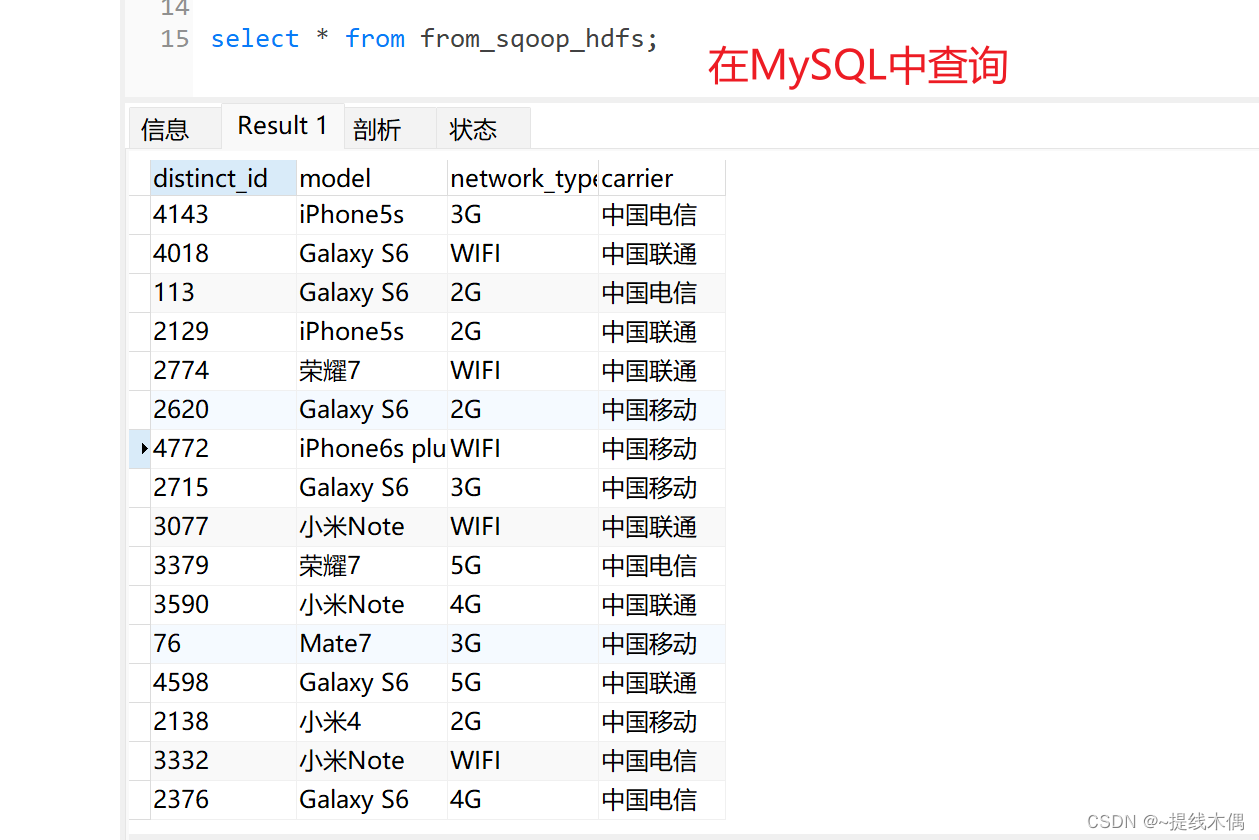
select * from useful_info;
数据展示:
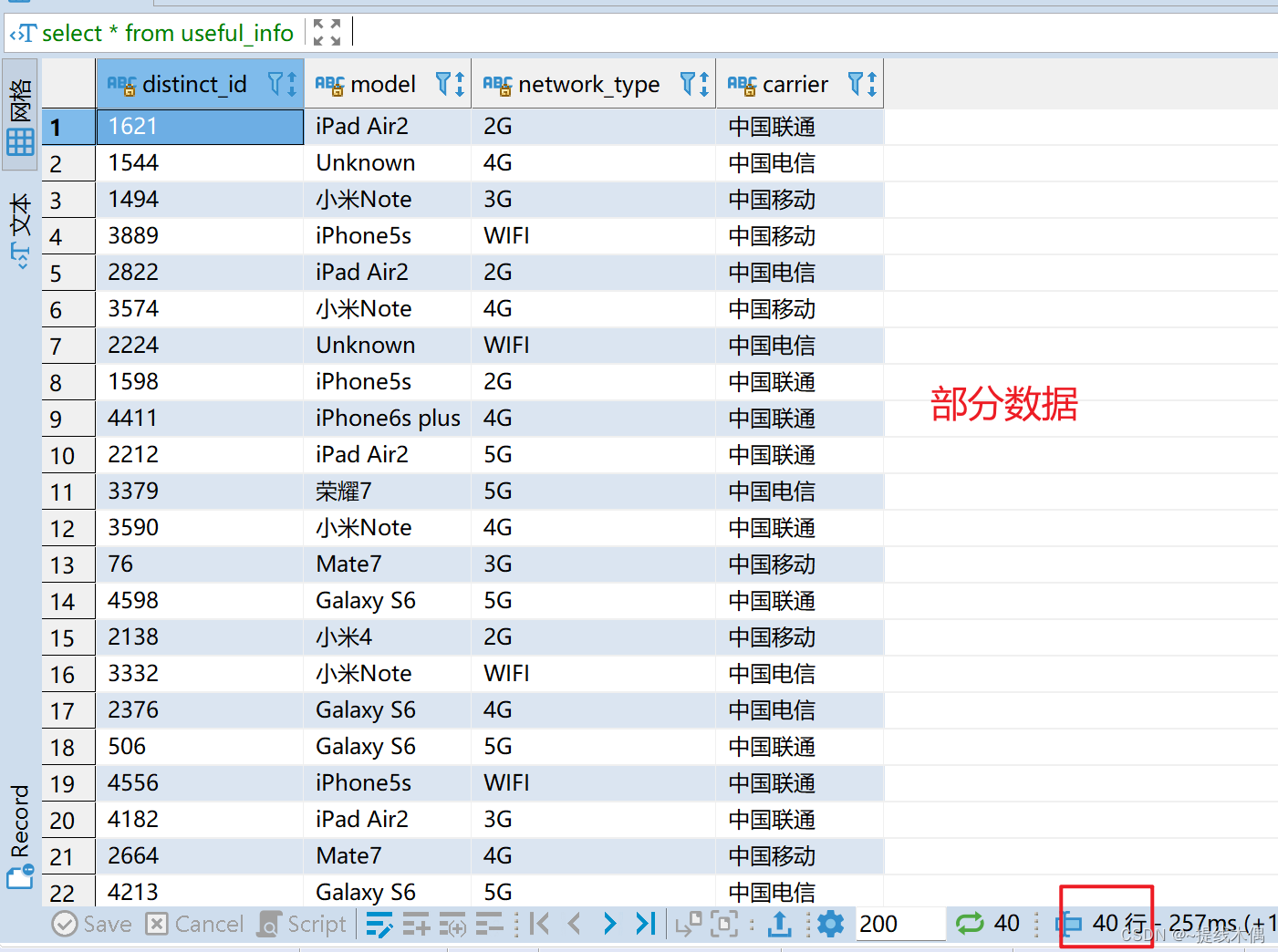
在hdfs上:

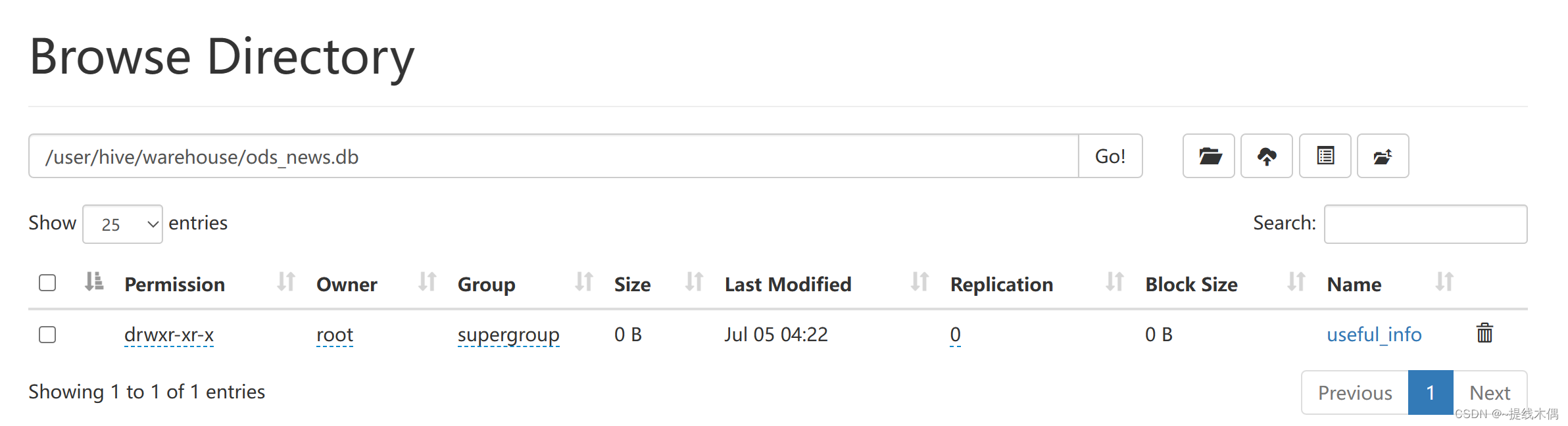
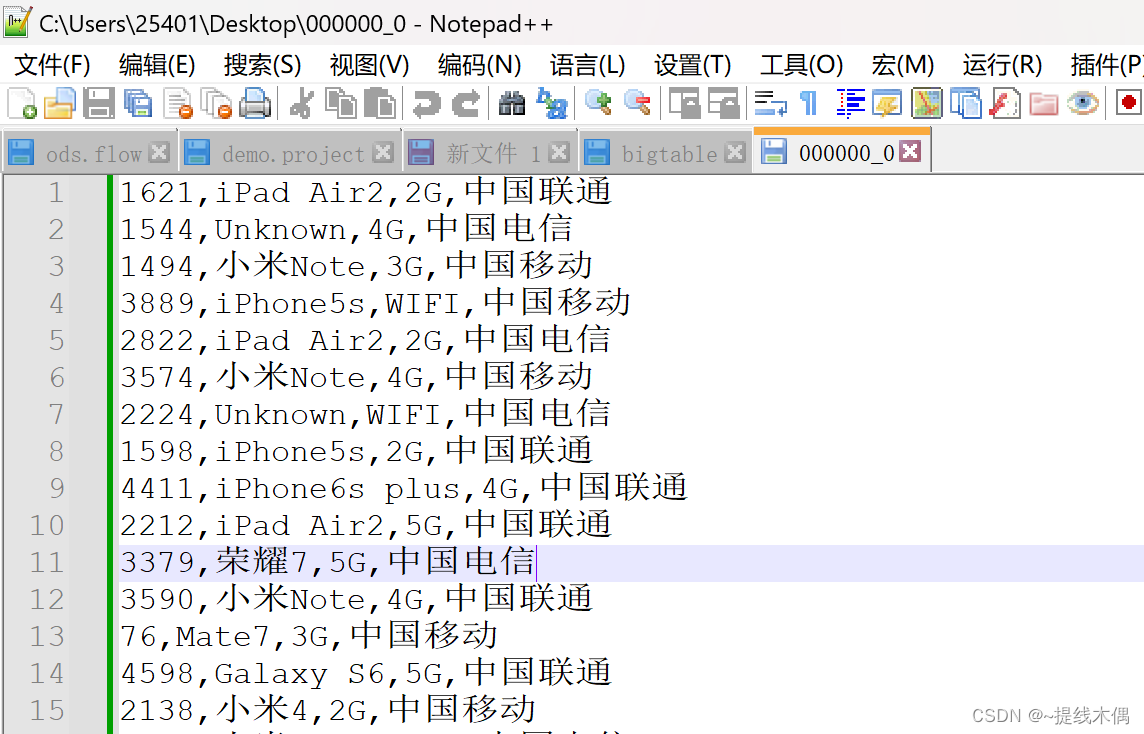
编写sqoop,把数据导出到MySQL
把useful_info中的数据导出到datacollection上的MySQL数据库中。
查看datacollection中MySQL的数据库和表
show databases;

use test1;
show tables;
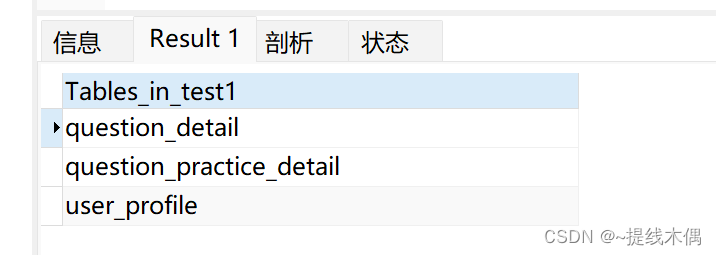
1、在MySQL创建表
注意:导出并不会自动创建对应的表,需要提前自己创建
在test1 数据库中新建一个表 from_sqoop_hdfs
CREATE TABLE from_sqoop_hdfs(
distinct_id VARCHAR(20),
model VARCHAR(50),
network_type VARCHAR(50),
carrier VARCHAR(50)
) CHARACTER SET utf8;
2、将hive上的数据导入mysql表中
在Linux命令行直接输入下面的语句:
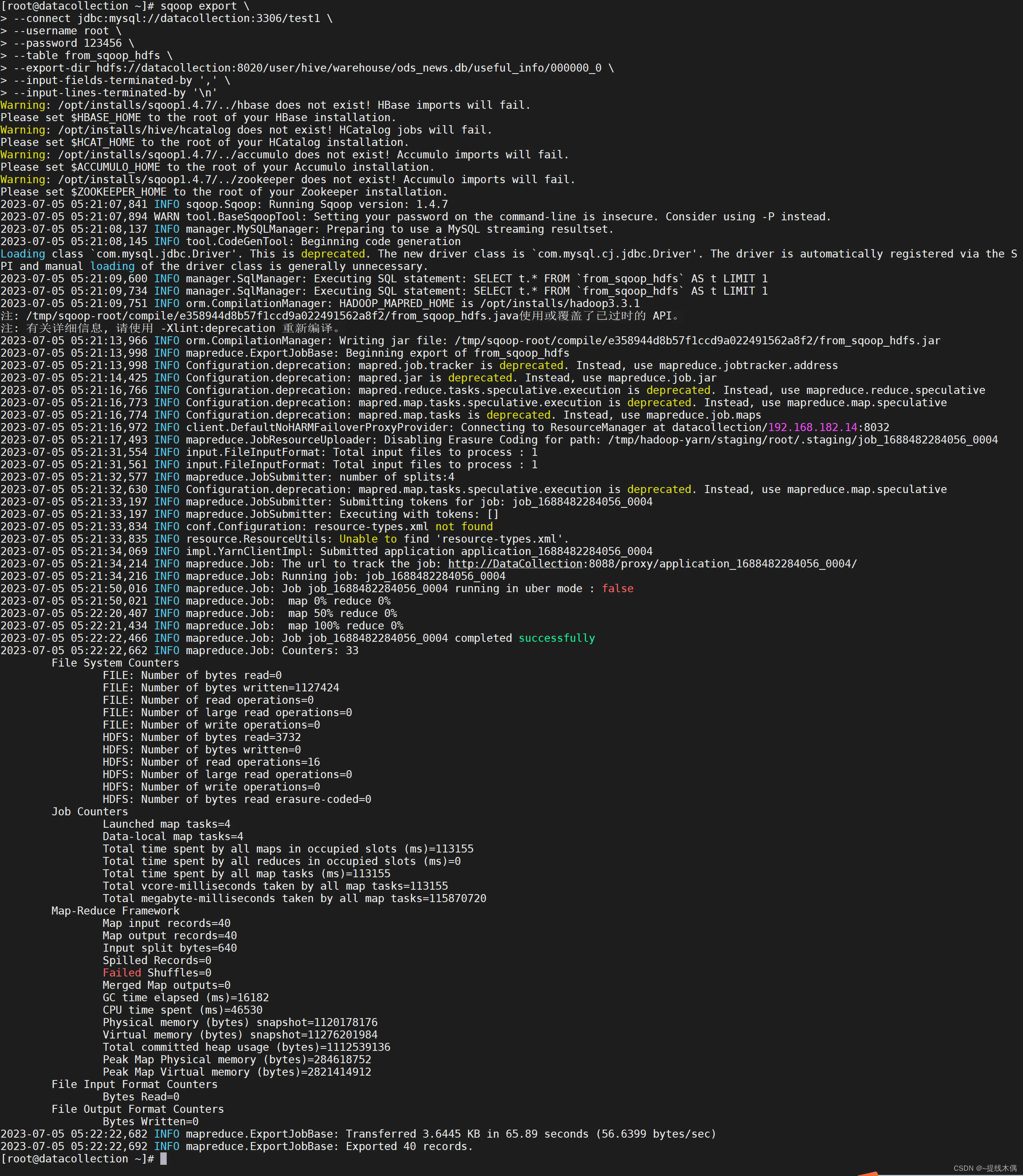
sqoop export \
--connect jdbc:mysql://datacollection:3306/test1 \
--username root \
--password 123456 \
--table from_sqoop_hdfs \
--export-dir hdfs://datacollection:8020/user/hive/warehouse/ods_news.db/useful_info/000000_0 \
--input-fields-terminated-by ',' \
--input-lines-terminated-by '\n'
成功啦!必须截个图纪念一下!!