DRSN(深度残差收缩网络)和完整Transformer(encoder+decoder)
- DRSN(深度残差收缩网络)
- 模型的代码
- 模型的打印
- 训练与预测
- 训练集的可视化:
- 测试集的可视化:
- DRSN-TCN的效果
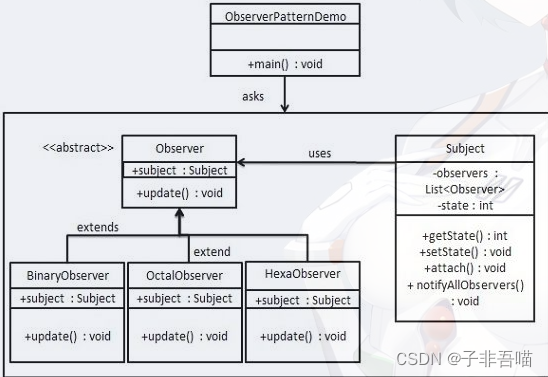
DRSN(深度残差收缩网络)
此次模型是应一位网友提出,怎么将其应用到我们的RUL预测领域中。当时候提出需求的时候,我也不太懂,后面花了两三天写出来了基础代码(就是模型个部分结构基本是固定),后续有花了2天时间修改出来了。比如构建DRSN的Block结构,DRSN与TCN的结合等等。下面参照一些博客大佬写的内容1234的
模型的代码
class DRSN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(DRSN, self).__init__()
self.resnet1 = ResNetBlock(input_size, hidden_size)
self.resnet2 = ResNetBlock(hidden_size, hidden_size)
self.resnet3 = ResNetBlock(hidden_size, hidden_size)
self.soft_threshold = SoftThreshold(hidden_size)
self.attention = Attention(hidden_size)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.resnet1(x)
x = self.resnet2(x)
x = self.resnet3(x)
x = self.soft_threshold(x)
x = self.attention(x)
x = self.linear(x)
return x
class ResNetBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ResNetBlock, self).__init__()
self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm1d(out_channels)
self.bn2 = nn.BatchNorm1d(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x += identity
x = self.relu(x)
return x
class SoftThreshold(nn.Module):
def __init__(self, num_features):
super(SoftThreshold, self).__init__()
# 初始化阈值学习参数
self.thresholds = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
x = torch.sign(x) * torch.max(torch.abs(x) - self.thresholds, torch.zeros_like(x))
return x
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.linear = nn.Linear(hidden_size, 1)
def forward(self, x):
# 计算注意力权重
weights = self.linear(x)
weights = torch.softmax(weights, dim=1)
# 添加注意力权重
x = x * weights
return x
模型的打印
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DRSN [128, 1] --
├─ResNetBlock: 1-1 [128, 128, 16] --
│ └─Conv1d: 2-1 [128, 128, 16] 25,472
│ └─BatchNorm1d: 2-2 [128, 128, 16] 256
│ └─ReLU: 2-3 [128, 128, 16] --
│ └─Conv1d: 2-4 [128, 128, 16] 49,280
│ └─BatchNorm1d: 2-5 [128, 128, 16] 256
│ └─Conv1d: 2-6 [128, 128, 16] 8,576
│ └─LeakyReLU: 2-7 [128, 128, 16] --
├─ResNetBlock: 1-2 [128, 32, 16] --
│ └─Conv1d: 2-8 [128, 32, 16] 12,320
│ └─BatchNorm1d: 2-9 [128, 32, 16] 64
│ └─ReLU: 2-10 [128, 32, 16] --
│ └─Conv1d: 2-11 [128, 32, 16] 3,104
│ └─BatchNorm1d: 2-12 [128, 32, 16] 64
│ └─Conv1d: 2-13 [128, 32, 16] 4,128
│ └─LeakyReLU: 2-14 [128, 32, 16] --
├─ResNetBlock: 1-3 [128, 16, 16] --
│ └─Conv1d: 2-15 [128, 16, 16] 1,552
│ └─BatchNorm1d: 2-16 [128, 16, 16] 32
│ └─ReLU: 2-17 [128, 16, 16] --
│ └─Conv1d: 2-18 [128, 16, 16] 784
│ └─BatchNorm1d: 2-19 [128, 16, 16] 32
│ └─Conv1d: 2-20 [128, 16, 16] 528
│ └─LeakyReLU: 2-21 [128, 16, 16] --
├─SoftThreshold: 1-4 [128, 16, 16] 16
├─Attention: 1-5 [128, 16, 16] --
│ └─Linear: 2-22 [128, 16, 1] 17
├─Linear: 1-6 [128, 1] 17
├─Sigmoid: 1-7 [128, 1] --
==========================================================================================
Total params: 106,498
Trainable params: 106,498
Non-trainable params: 0
Total mult-adds (M): 216.66
==========================================================================================
Input size (MB): 0.54
Forward/backward pass size (MB): 14.70
Params size (MB): 0.43
Estimated Total Size (MB): 15.66
==========================================================================================
最后还有与TCN的结合
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
DRSN [128, 1] --
├─TemporalConvNet: 1-1 [128, 32, 16] --
│ └─Sequential: 2-1 [128, 32, 16] --
│ │ └─TemporalBlock: 3-1 [128, 64, 16] 33,984
│ │ └─TemporalBlock: 3-2 [128, 32, 16] 13,920
│ │ └─TemporalBlock: 3-3 [128, 32, 16] 9,280
├─SoftThreshold: 1-2 [128, 16, 32] 32
├─Attention: 1-3 [128, 16, 32] --
│ └─Linear: 2-2 [128, 16, 1] 33
├─Linear: 1-4 [128, 1] 33
├─Sigmoid: 1-5 [128, 1] --
===============================================================================================
Total params: 57,282
Trainable params: 57,282
Non-trainable params: 0
Total mult-adds (M): 114.99
===============================================================================================
Input size (MB): 0.54
Forward/backward pass size (MB): 12.60
Params size (MB): 0.23
Estimated Total Size (MB): 13.37
===============================================================================================
训练与预测
这还是以PHM2012轴承的工况一的七个轴承为例,Bearing1-1和Beanring1-2做训练,后面Bearing1-3到Bearing15这五个做预测.,使用的特征还是之前的示例数据EMD分解后的IMF分量的6个统计特征。
训练集的可视化:


测试集的可视化:





DRSN-TCN的效果
训练集可视化:



洽谈轴承效果还是比较差,这里就不放图了。总体来说,还是需要对DRSN与TCN的结合进行优化。
深度残差收缩网络(DRSN ↩︎
深度残差收缩网络:一种面向强噪声数据的深度学习方法 ↩︎
残差网络?收缩?深度残差收缩网络看这篇就够了 ↩︎
另类注意力机制之深度残差收缩网络(附代码) ↩︎