目录
1.SRM介绍 编辑
2.SRM引入到yolov5
2.1 加入common.py中:
2.2 加入yolo.py中:
2.3 yolov5s_SRM.yaml
2.4 yolov5s_SRM1.yaml
3.YOLOv5/YOLOv7魔术师专栏介绍

1.SRM介绍 
论文:https://openaccess.thecvf.com/content_ICCV_2019/papers/Lee_SRM_A_Style-Based_Recalibration_Module_for_Convolutional_Neural_Networks_ICCV_2019_paper.pdf
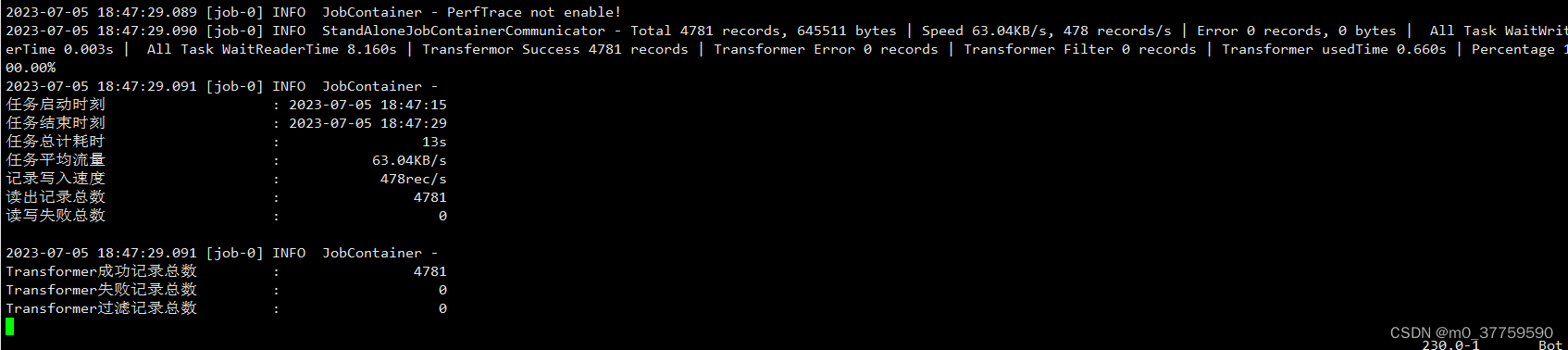
SRM的总体结构如 Figure 1 所示。它由两个主要组件组成:Style Pooling 和 Style Integration。Style Pooling 运算符通过汇总跨空间维度的特征响应来从每个通道提取风格特征。紧随其后的是 Style Integration 运算符,该运算符通过基于通道的操作利用风格特征来生成特定于示例的风格权重。

SRM首先通过“style pooling”从特征图的每个通道中提取风格信息,然后通过与通道无关的风格集成来估计每个通道的重新校准权重。通过将单个风格的相对重要性纳入特征图,SRM有效地增强了CNN的表示能力。
Figure 3 展示了带有 SRM 和其他特征重新校准方法的 ResNet-50 的训练和验证曲线。在整个训练过程中,无论是在训练还是在验证曲线上,SRM的准确性都比SE和GE高得多。这意味着,在SRM中使用风格,比在SE中建模通道相关性或在GE中收集全局上下文更有效,这两方面都有助于训练和提高泛化能力。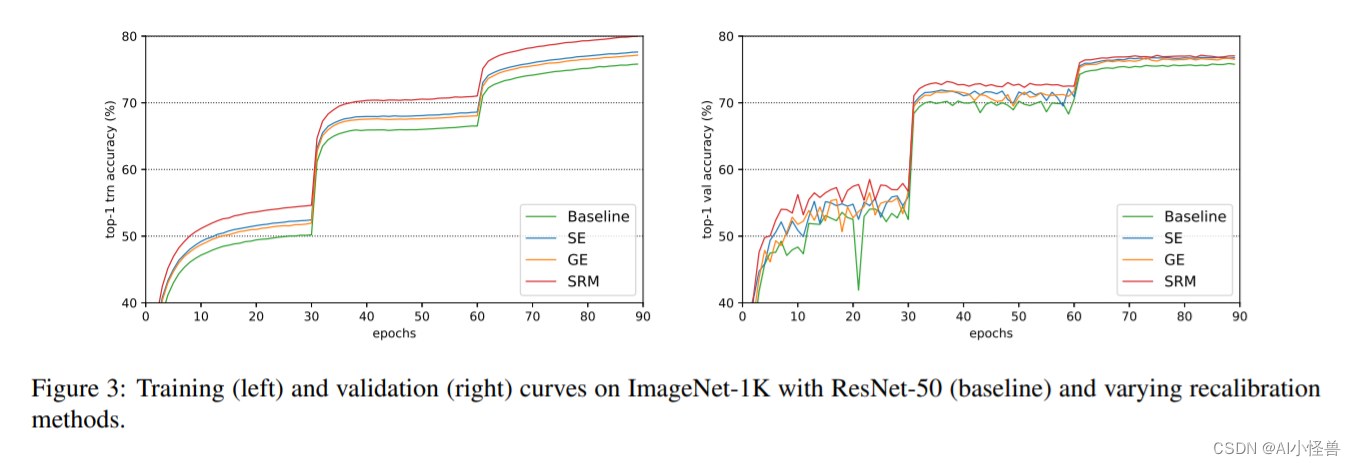
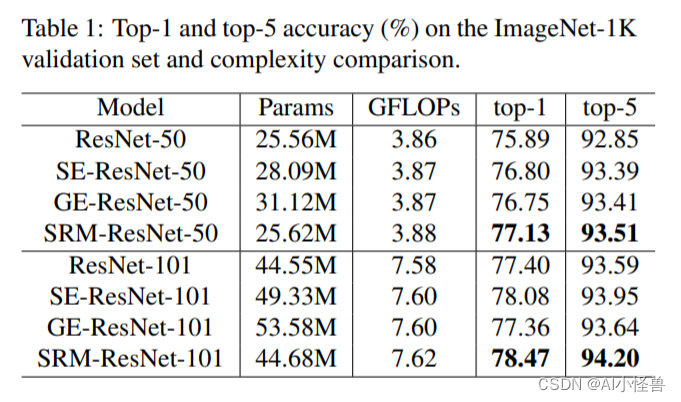
值得注意的是,SRM的性能优于SE和GE,其附加参数的数量较少。
2.SRM引入到yolov5
2.1 加入common.py中:
###################### SRM attention #### START by AI&CV ###############################
"""
PyTorch implementation of Srm : A style-based recalibration module for
convolutional neural networks
As described in https://arxiv.org/pdf/1903.10829
SRM first extracts the style information from each channel of the feature maps by style pooling,
then estimates per-channel recalibration weight via channel-independent style integration.
By incorporating the relative importance of individual styles into feature maps,
SRM effectively enhances the representational ability of a CNN.
"""
import torch
from torch import nn
class SRM(nn.Module):
def __init__(self,feature, channel):
super().__init__()
self.cfc = nn.Conv1d(channel, channel, kernel_size=2, groups=channel,
bias=False)
self.bn = nn.BatchNorm1d(channel)
def forward(self, x):
b, c, h, w = x.shape
# style pooling
mean = x.reshape(b, c, -1).mean(-1).unsqueeze(-1)
std = x.reshape(b, c, -1).std(-1).unsqueeze(-1)
u = torch.cat([mean, std], dim=-1)
# style integration
z = self.cfc(u)
z = self.bn(z)
g = torch.sigmoid(z)
g = g.reshape(b, c, 1, 1)
return x * g.expand_as(x)
###################### SRM attention #### END by AI&CV ###############################
2.2 加入yolo.py中:
def parse_model(d, ch): # model_dict, input_channels(3)
添加以下内容
if m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF,DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,SRM}:2.3 yolov5s_SRM.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SRM, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.4 yolov5s_SRM1.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, SRM, [256]], # 18
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, SRM, [512]], # 22
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, SRM, [1024]], # 26
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.YOLOv5/YOLOv7魔术师专栏介绍
💡💡💡YOLOv5/YOLOv7魔术师,独家首发创新(原创),持续更新,最终完结篇数≥100+,适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络
💡💡💡重点:通过本专栏的阅读,后续你也可以自己魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
专栏介绍:
✨✨✨原创魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉持续更新中,定期更新不同数据集涨点情况
本专栏提供每一步改进步骤和源码,开箱即用,在你的数据集下轻松涨点
通过注意力机制、小目标检测、Backbone&Head优化、 IOU&Loss优化、优化器改进、卷积变体改进、轻量级网络结合yolo等方面进行展开点
专栏链接如下:
https://blog.csdn.net/m0_63774211/category_12240482.html