PaddleClas提供的都是现成的网络结构和权重,不一定适用,所以有必要掌握魔改的技能。
PaddleClas版本:2.5
1:新建 mynet.py
- 在 ppcls/arch/backbone/model_zoo/ 文件夹下新建一个自己的模型结构文件 mynet.py,即你自己的 backbone;

2:模型搭建
- 在mynet.py中搭建自己的网络,可以参考model_zoo或legendary_models中的众多模型文件;
#我以legendary_models/mobilenet_v3.py为参考,添加激活函数FReLU
# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# reference: https://arxiv.org/abs/1905.02244
from __future__ import absolute_import, division, print_function
import paddle
import paddle.nn as nn
from paddle import ParamAttr
from paddle.nn import AdaptiveAvgPool2D, BatchNorm, Conv2D, Dropout, Linear
from paddle.regularizer import L2Decay
from ..base.theseus_layer import TheseusLayer
from ....utils.save_load import load_dygraph_pretrain, load_dygraph_pretrain_from_url
MODEL_URLS = {
"MobileNetV3_large_FRELU":""
}
MODEL_STAGES_PATTERN = {
"MobileNetV3_large_FRELU":
["blocks[0]", "blocks[2]", "blocks[5]", "blocks[11]", "blocks[14]"]
}
__all__ = MODEL_URLS.keys()
# "large", "small" is just for MobinetV3_large, MobileNetV3_small respectively.
# The type of "large" or "small" config is a list. Each element(list) represents a depthwise block, which is composed of k, exp, se, act, s.
# k: kernel_size
# exp: middle channel number in depthwise block
# c: output channel number in depthwise block
# se: whether to use SE block
# act: which activation to use
# s: stride in depthwise block
NET_CONFIG = {
"large": [
# k, exp, c, se, act, s
[3, 16, 16, False, "frelu", 1],#[3, 16, 16, False, "relu", 1],
[3, 64, 24, False, "frelu", 2],
[3, 72, 24, False, "frelu", 1],
[5, 72, 40, True, "relu", 2],
[5, 120, 40, True, "relu", 1],
[5, 120, 40, True, "relu", 1],
[3, 240, 80, False, "hardswish", 2],
[3, 200, 80, False, "hardswish", 1],
[3, 184, 80, False, "hardswish", 1],
[3, 184, 80, False, "hardswish", 1],
[3, 480, 112, True, "hardswish", 1],
[3, 672, 112, True, "hardswish", 1],
[5, 672, 160, True, "hardswish", 2],
[5, 960, 160, True, "hardswish", 1],
[5, 960, 160, True, "hardswish", 1],
]
}
# first conv output channel number in MobileNetV3
STEM_CONV_NUMBER = 16
# last second conv output channel for "large"
LAST_SECOND_CONV_LARGE = 960
# last conv output channel number for "large"
LAST_CONV = 1280
class FReLU(nn.Layer):
def __init__(self, dim, init_weight=False):
super().__init__()
self.conv = nn.Conv2D(dim, dim, 3, 1, 1, groups=dim)
self.bn = nn.BatchNorm2D(dim)
if init_weight:
self.apply(self._init_weight)
def _init_weight(self, m):
init = nn.initializer.Normal(mean=0, std=.02)
zeros = nn.initializer.Constant(0.)
ones = nn.initializer.Constant(1.)
if isinstance(m, nn.Conv2D):
init(m.weight)
zeros(m.bias)
if isinstance(m, nn.BatchNorm2D):
ones(m.weight)
zeros(m.bias)
def forward(self, x):
x1 = self.bn(self.conv(x))
out = paddle.maximum(x, x1)
return out
def _make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def _create_act(act, dim):
if act == "hardswish":
return nn.Hardswish()
elif act == "relu":
return nn.ReLU()
elif act == "frelu":
return FReLU(dim)
elif act is None:
return None
else:
raise RuntimeError(
"The activation function is not supported: {}".format(act))
class MobileNetV3_FReLU(TheseusLayer):
"""
MobileNetV3_FReLU
Args:
config: list. MobileNetV3 depthwise blocks config.
scale: float=1.0. The coefficient that controls the size of network parameters.
class_num: int=1000. The number of classes.
inplanes: int=16. The output channel number of first convolution layer.
class_squeeze: int=960. The output channel number of penultimate convolution layer.
class_expand: int=1280. The output channel number of last convolution layer.
dropout_prob: float=0.2. Probability of setting units to zero.
Returns:
model: nn.Layer. Specific MobileNetV3 model depends on args.
"""
def __init__(self,
config,
stages_pattern,
scale=1.0,
class_num=1000,
inplanes=STEM_CONV_NUMBER,
class_squeeze=LAST_SECOND_CONV_LARGE,
class_expand=LAST_CONV,
dropout_prob=0.2,
return_patterns=None,
return_stages=None,
**kwargs):
super().__init__()
self.cfg = config
self.scale = scale
self.inplanes = inplanes
self.class_squeeze = class_squeeze
self.class_expand = class_expand
self.class_num = class_num
self.conv = ConvBNLayer(
in_c=3,
out_c=_make_divisible(self.inplanes * self.scale),
filter_size=3,
stride=2,
padding=1,
num_groups=1,
if_act=True,
act="frelu")
self.blocks = nn.Sequential(* [
ResidualUnit(
in_c=_make_divisible(self.inplanes * self.scale if i == 0 else
self.cfg[i - 1][2] * self.scale),
mid_c=_make_divisible(self.scale * exp),
out_c=_make_divisible(self.scale * c),
filter_size=k,
stride=s,
use_se=se,
act=act) for i, (k, exp, c, se, act, s) in enumerate(self.cfg)
])
self.last_second_conv = ConvBNLayer(
in_c=_make_divisible(self.cfg[-1][2] * self.scale),
out_c=_make_divisible(self.scale * self.class_squeeze),
filter_size=1,
stride=1,
padding=0,
num_groups=1,
if_act=True,
act="hardswish")
self.avg_pool = AdaptiveAvgPool2D(1)
self.last_conv = Conv2D(
in_channels=_make_divisible(self.scale * self.class_squeeze),
out_channels=self.class_expand,
kernel_size=1,
stride=1,
padding=0,
bias_attr=False)
self.hardswish = nn.Hardswish()
if dropout_prob is not None:
self.dropout = Dropout(p=dropout_prob, mode="downscale_in_infer")
else:
self.dropout = None
self.flatten = nn.Flatten(start_axis=1, stop_axis=-1)
self.fc = Linear(self.class_expand, class_num)
super().init_res(
stages_pattern,
return_patterns=return_patterns,
return_stages=return_stages)
def forward(self, x):
x = self.conv(x)
x = self.blocks(x)
x = self.last_second_conv(x)
x = self.avg_pool(x)
x = self.last_conv(x)
x = self.hardswish(x)
if self.dropout is not None:
x = self.dropout(x)
x = self.flatten(x)
x = self.fc(x)
return x
class ConvBNLayer(TheseusLayer):
def __init__(self,
in_c,
out_c,
filter_size,
stride,
padding,
num_groups=1,
if_act=True,
act=None):
super().__init__()
self.conv = Conv2D(
in_channels=in_c,
out_channels=out_c,
kernel_size=filter_size,
stride=stride,
padding=padding,
groups=num_groups,
bias_attr=False)
self.bn = BatchNorm(
num_channels=out_c,
act=None,
param_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
self.if_act = if_act
self.act = _create_act(act,out_c)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.if_act:
x = self.act(x)
return x
class ResidualUnit(TheseusLayer):
def __init__(self,
in_c,
mid_c,
out_c,
filter_size,
stride,
use_se,
act=None):
super().__init__()
self.if_shortcut = stride == 1 and in_c == out_c
self.if_se = use_se
self.expand_conv = ConvBNLayer(
in_c=in_c,
out_c=mid_c,
filter_size=1,
stride=1,
padding=0,
if_act=True,
act=act)
self.bottleneck_conv = ConvBNLayer(
in_c=mid_c,
out_c=mid_c,
filter_size=filter_size,
stride=stride,
padding=int((filter_size - 1) // 2),
num_groups=mid_c,
if_act=True,
act=act)
if self.if_se:
self.mid_se = SEModule(mid_c)
self.linear_conv = ConvBNLayer(
in_c=mid_c,
out_c=out_c,
filter_size=1,
stride=1,
padding=0,
if_act=False,
act=None)
def forward(self, x):
identity = x
x = self.expand_conv(x)
x = self.bottleneck_conv(x)
if self.if_se:
x = self.mid_se(x)
x = self.linear_conv(x)
if self.if_shortcut:
x = paddle.add(identity, x)
return x
# nn.Hardsigmoid can't transfer "slope" and "offset" in nn.functional.hardsigmoid
class Hardsigmoid(TheseusLayer):
def __init__(self, slope=0.2, offset=0.5):
super().__init__()
self.slope = slope
self.offset = offset
def forward(self, x):
return nn.functional.hardsigmoid(
x, slope=self.slope, offset=self.offset)
class SEModule(TheseusLayer):
def __init__(self, channel, reduction=4):
super().__init__()
self.avg_pool = AdaptiveAvgPool2D(1)
self.conv1 = Conv2D(
in_channels=channel,
out_channels=channel // reduction,
kernel_size=1,
stride=1,
padding=0)
self.relu = nn.ReLU()
self.conv2 = Conv2D(
in_channels=channel // reduction,
out_channels=channel,
kernel_size=1,
stride=1,
padding=0)
self.hardsigmoid = Hardsigmoid(slope=0.2, offset=0.5)
def forward(self, x):
identity = x
x = self.avg_pool(x)
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.hardsigmoid(x)
return paddle.multiply(x=identity, y=x)
def _load_pretrained(pretrained, model, model_url, use_ssld):
if pretrained is False:
pass
else:
raise RuntimeError(
"pretrained type is not available. Please use `string` or `boolean` type."
)
def MobileNetV3_large_FRelu(pretrained=False, use_ssld=False, **kwargs):
"""
MobileNetV3_large_x1_0
Args:
pretrained: bool=False or str. If `True` load pretrained parameters, `False` otherwise.
If str, means the path of the pretrained model.
use_ssld: bool=False. Whether using distillation pretrained model when pretrained=True.
Returns:
model: nn.Layer. Specific `MobileNetV3_large_x1_0` model depends on args.
"""
model = MobileNetV3_FReLU(
config=NET_CONFIG["large"],
scale=1.0,
stages_pattern=MODEL_STAGES_PATTERN["MobileNetV3_large_FRELU"],
class_squeeze=LAST_SECOND_CONV_LARGE,
**kwargs)
_load_pretrained(pretrained, model, MODEL_URLS["MobileNetV3_large_FRELU"],
use_ssld)
return model
3:声明自己的模型
- 在 ppcls/arch/backbone/__init__.py 中添加自己设计的 backbone 的类;

4:配置训练yaml文件
- 参考 ppcls/configs/ImageNet/MobileNetV3/MobileNetV3_small_x1_0.yaml;
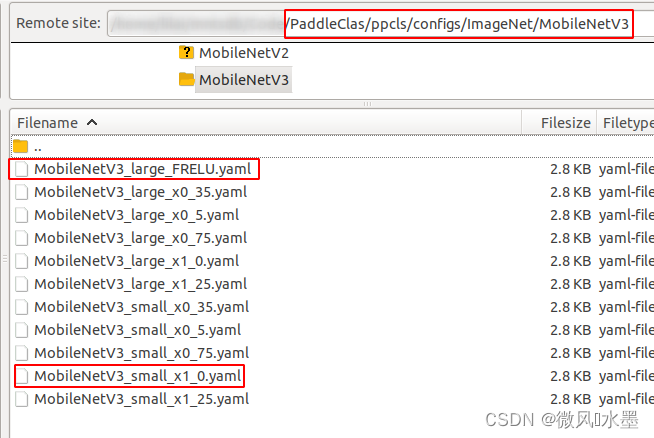
具体如下:根据自己的数据进行类别数目、数据位置的调整
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 100
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# model architecture
Arch:
name: MobileNetV3_large_FRELU
class_num: 100
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Cosine
learning_rate: 0.04
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: ./dataset/CIFAR100/
cls_label_path: ./dataset/CIFAR100/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 32
- RandFlipImage:
flip_code: 1
- AutoAugment:
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: ./dataset/CIFAR100/
cls_label_path: ./dataset/CIFAR100/test_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 36
- CropImage:
size: 32
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: True
Infer:
infer_imgs: docs/images/inference_deployment/whl_demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 36
- CropImage:
size: 32
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 5]
Eval:
- TopkAcc:
topk: [1, 5]5:启动训练
python3 -m paddle.distributed.launch \
--gpus="0" \
tools/train.py \
-c ./ppcls/configs/ImageNet/MobileNetV3/MobileNetV3_large_FRELU.yaml \
-o Global.output_dir="./output/output_CIFAR_mbv3_FRELU" \
-o Optimizer.lr.learning_rate=0.01

顺利跑完,不过很尴尬的是:自己改动的FRELU版本比未原版精度低了好几个点。。。也许FRELU需要调参数吧。
参考:
https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/docs/zh_CN/FAQ/faq_2020_s1.md#1






![[网鼎杯 2020 青龙组]AreUSerialz1](https://img-blog.csdnimg.cn/img_convert/54968359efa74f26bfcc21bd7423dc46.png)