3.2线性回归模型-part-2
Let’s look in this video at the process of how supervised learning works. Supervised learning algorithm will input a dataset and then what exactly does it do and what does it output? Let’s find out in this video. Recall that a training set in supervised learning includes both the input features, such as the size of the house and also the output targets, such as the price of the house. The output targets are the right answers to the model we’ll learn from. To train the model, you feed the training set, both the input features and the output targets to your learning algorithm.
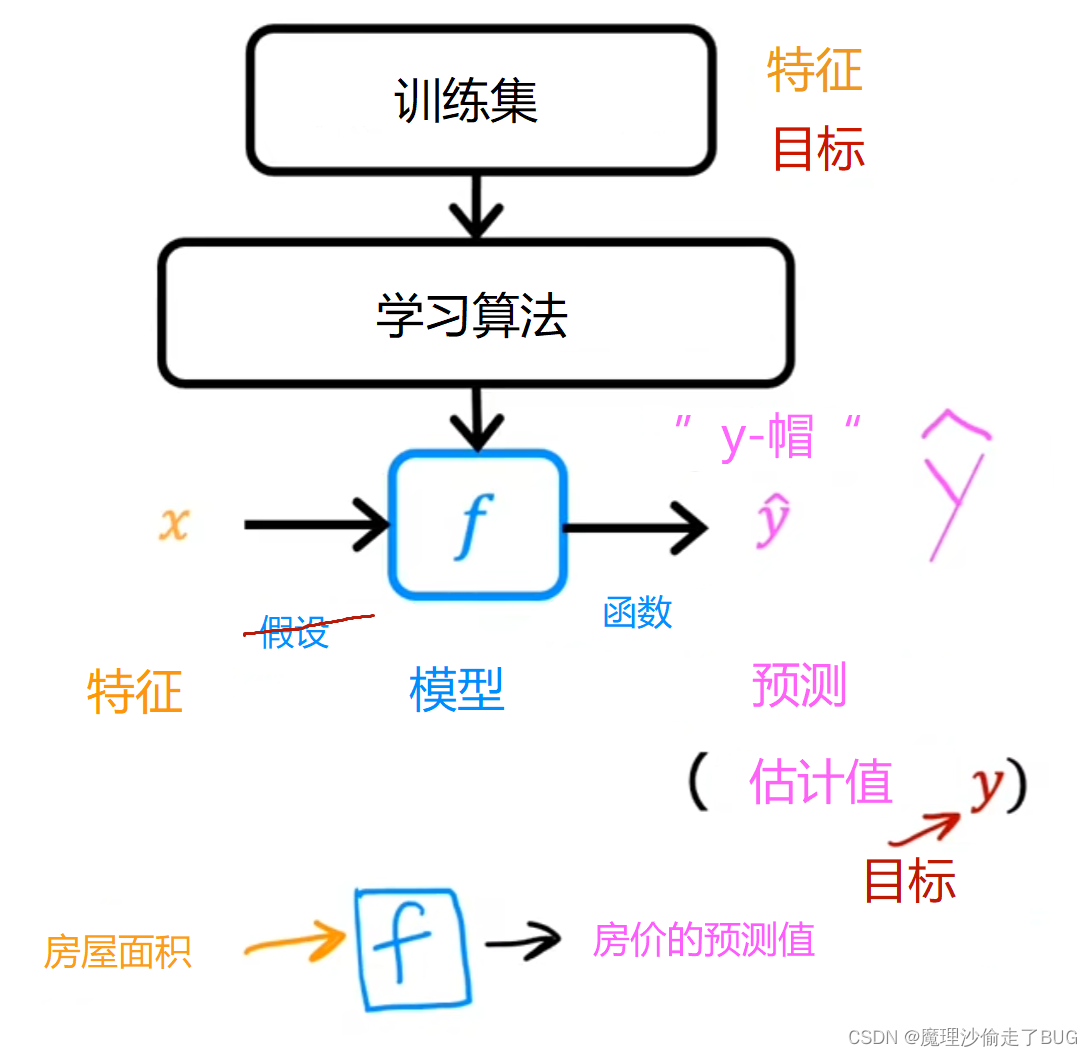
在这个视频中,让我们来看一下监督学习的工作过程。我们将一个数据集输入到监督学习算法中,然后它究竟做了些什么?它的输出是什么?让我们在这个视频中一探究竟。回想一下,在监督学习中,训练集包括输入特征,例如房屋的大小,以及输出目标,例如房屋的价格。对于监督学习模型来说,输出的目标是我们给算法提供学习的正确答案。为了训练模型,你需要将训练集的输入特征和输出目标一起提供给学习算法。
Then your supervised learning algorithm will produce some function. We’ll write this function as lowercase f, where f stands for function. Historically, this function used to be called a hypothesis, but I’m just going to call it a function f in this class. The job with f is to take a new input x and output and estimate or a prediction, which I’m going to call y-hat, and it’s written like the variable y with this little hat symbol on top. In machine learning, the convention is that y-hat is the estimate or the prediction for y. The function f is called the model.
然后,你的监督学习算法将产生一个函数。我们将把这个函数写成小写的
f
f
f,其中
f
f
f 代表函数。从历史上看,这个函数过去被称为假设函数,但在本课程中,我将简单地称它为函数
f
f
f。函数
f
f
f 的作用是接收一个新的输入
x
x
x,并输出一个估计值或预测值,我将称之为 y-hat(读作:y帽),它用字母
y
y
y 加上一个小帽子符号上标来表示,即写作"
y
^
\hat{y}
y^“。在机器学习中,我们约定俗成将
y
^
\hat{y}
y^表示
y
y
y 的估计值或预测值。函数
f
f
f 被称为模型。
X is called the input or the input feature, and the output of the model is the prediction, y-hat. The model’s prediction is the estimated value of y. When the symbol is just the letter y, then that refers to the target, which is the actual true value in the training set. In contrast, y-hat is an estimate. It may or may not be the actual true value.
x
x
x 被称为输入或者输入特征,而模型的输出是预测值
y
^
\hat{y}
y^。模型的预测值是
y
y
y 的估计值。当符号只是字母
y
y
y时,那表示目标值,也就是训练集中的真实值。相反,
y
^
\hat{y}
y^ 是一个估计值。
y
^
\hat{y}
y^可能是真实值,也可能不是真实值。
Well, if you’re helping your client to sell the house, well, the true price of the house is unknown until they sell it. Your model f, given the size, outputs the price which is the estimator, that is the prediction of what the true price will be.
如果你正在帮助你的客户出售房屋,那么直到出售之前,房屋的真实价格都是未知的。你的模型
f
f
f 根据房屋的大小输出价格,这就是估计值,即对真实价格的预测。
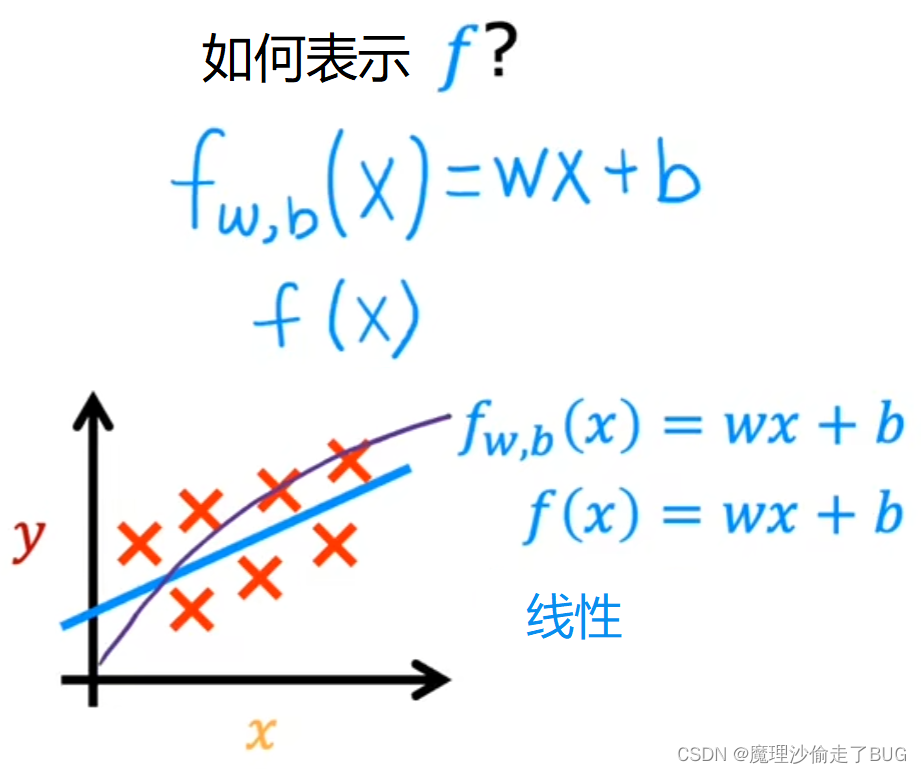
Now, when we design a learning algorithm, a key question is, how are we going to represent the function f? Or in other words, what is the math formula we’re going to use to compute f? For now, let’s stick with f being a straight line. You’re function can be written as f_w, b of x equals, I’m going to use w times x plus b. I’ll define w and b soon. But for now, just know that w and b are numbers, and the values chosen for w and b will determine the prediction y-hat based on the input feature x. This f_w b of x means f is a function that takes x as input, and depending on the values of w and b, f will output some value of a prediction y-hat.
现在,当我们设计一个学习算法时,一个关键问题是如何表示函数
f
f
f?换句话说,我们将使用什么数学公式来计算
f
f
f?现在,让我们将
f
f
f 视作一条直线(即一次函数)。你的函数可以写成
f
w
,
b
(
x
)
=
w
x
+
b
f_{w,b}(x)=wx+b
fw,b(x)=wx+b. 我很快会就会定义
w
w
w 和
b
b
b. 但现在,你只要知道
w
w
w 和
b
b
b 是数字,并且给
w
w
w和
b
b
b赋的值将决定基于输入的特征
x
x
x的预测值
y
^
\hat{y}
y^(他的意思是,不同的
w
w
w和
b
b
b能有不同的预测值
y
^
\hat{y}
y^)。关于
x
x
x的函数
f
w
,
b
(
x
)
f_{w,b}(x)
fw,b(x)是一个以
x
x
x 为输入的函数,根据
w
w
w 和
b
b
b 的值的不同,
f
f
f 将输出某个预测值
y
^
\hat{y}
y^.
As an alternative to writing this, f_w, b of x, I’ll sometimes just write f of x without explicitly including w and b into subscript. Is just a simpler notation that means exactly the same thing as f_w b of x. Let’s plot the training set on the graph where the input feature x is on the horizontal axis and the output target y is on the vertical axis. Remember, the algorithm learns from this data and generates the best-fit line like maybe this one here.
f
w
,
b
(
x
)
f_{w,b}(x)
fw,b(x)的有另一种简单的写法,即写成
f
(
x
)
f(x)
f(x),不明确地包含 $w 和
b
b
b 的下标。这只是一个更简单的表示法,与
f
w
,
b
(
x
)
f_{w,b}(x)
fw,b(x)的意思完全相同。让我们将训练集绘制在图表上,其中输入特征
x
x
x 在横轴上,输出目标
y
y
y 在纵轴上。记住,算法从这些数据中学习,并生成最佳拟合线,可能就像这条线一样(图中蓝色的直线)。

Here’s what this function is doing, it’s making predictions for the value of y using a streamline function of x. You may ask, why are we choosing a linear function, where linear function is just a fancy term for a straight line instead of some non-linear function like a curve or a parabola? Well, sometimes you want to fit more complex non-linear functions as well, like a curve like this. But since this linear function is relatively simple and easy to work with, let’s use a line as a foundation that will eventually help you to get to more complex models that are non-linear.
这个函数的作用是使用一个关于
x
x
x的线性函数对
y
y
y 的值进行预测。你可能会问,为什么我们选择线性函数,而不是一些非线性函数,比如曲线或抛物线呢?线性函数只是直线的一个华丽说法。有时候你可能也想要拟合更复杂的非线性函数,比如这样的曲线(图中紫色曲线)。但由于线性函数相对简单且易于处理,让我们将直线作为学习的基础,它最终帮助你掌握更复杂的非线性模型。
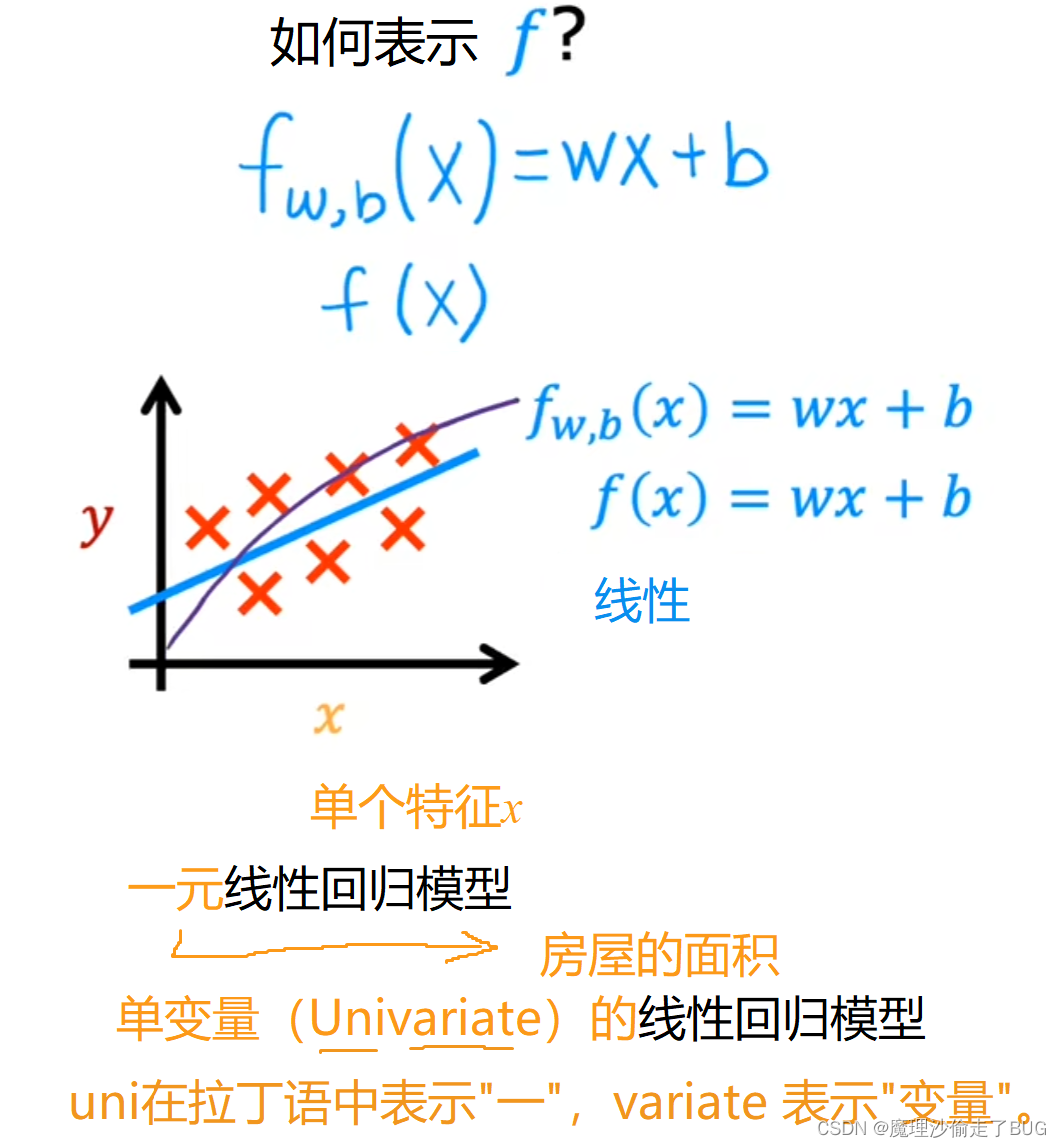
More specifically, this is linear regression with one variable, where the phrase one variable means that there’s a single input variable or feature x, namely the size of the house. Another name for a linear model with one input variable is univariate linear regression, where uni means one in Latin, and where variate means variable. Univariate is just a fancy way of saying one variable.
更具体地说,这是一元线性回归,其中一元表示只有一个输入变量或特征
x
x
x,即房屋的大小。一元线性回归也可以称为具有单个输入变量的(univariate)线性模型,其中 uni在拉丁语中表示"一”,variate 表示"变量"。"一元"只是对一个变量的华丽说法。
In a later video, you’ll also see a variation of regression where you’ll want to make a prediction based not just on the size of a house, but on a bunch of other things that you may know about the house such as number of bedrooms and other features. By the way, when you’re done with this video, there is another optional lab. You don’t need to write any code. Just review it, run the code and see what it does. That will show you how to define in Python a straight line function. The lab will let you choose the values of w and b to try to fit the training data. You don’t have to do the lab if you don’t want to, but I hope you play with it when you’re done watching this video.
在后面的视频中,你还会看到一种回归的变体,它不仅仅基于房屋的大小进行预测,还要考虑到一大堆其他你可能了解的房屋信息,比如卧室的数量和其他特征。顺便说一下,当你完成这个视频后,还有一个可选的实验室。你不需要编写任何代码,只需查看并运行其中的代码,看看它是如何工作的。这将向你展示如何在 Python 中定义一个直线函数。实验室会让你选择
w
w
w 和
b
b
b 的值,以尝试拟合训练数据。如果你不想做这个实验室,你不必强迫自己,但我希望你在观看完这个视频后能去尝试一下。
That’s linear regression. In order for you to make this work, one of the most important things you have to do is construct a cost function. The idea of a cost function is one of the most universal and important ideas in machine learning, and is used in both linear regression and in training many of the most advanced AI models in the world. Let’s go on to the next video and take a look at how you can construct a cost function.
这就是线性回归。为了使算法正常工作,你需要做的最重要的事情之一就是构建一个代价函数。代价函数的概念是机器学习中最普适和重要的想法之一,它既用于线性回归,也用于训练世界上许多最先进的人工智能模型。让我们继续下一个视频,看看如何构建一个代价函数。