注1:本文系“简要介绍”系列之一,仅从概念上对大规模三维场景理解进行非常简要的介绍,不适合用于深入和详细的了解。
大规模三维场景理解:从点云到智能导航
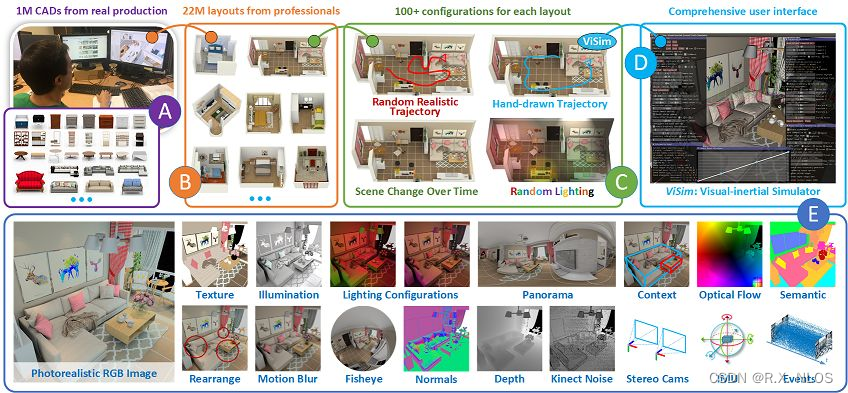
InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset
大规模三维场景理解是计算机视觉和机器学习领域的一个重要分支,旨在从点云数据、图像数据或其他数据源重建和理解三维场景。三维场景理解在许多应用领域具有广泛的应用前景,如无人驾驶、机器人导航、增强现实和虚拟现实等。本文将介绍大规模三维场景理解的背景、原理、研究现状、挑战和未来展望。
1 背景介绍
三维场景理解的需求随着计算机视觉和机器学习技术的快速发展而不断增长。传统的二维图像处理技术在很大程度上已经能够实现目标检测、物体识别等任务,但在处理现实世界中的复杂三维场景时,仍然面临诸多挑战。三维场景理解关注的核心问题是如何从大量的原始数据中提取有价值的信息,以支持自动驾驶汽车、无人机、机器人等智能系统的高效、安全操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G03Cwpeb-1688453884128)(https://i.imgur.com/MW2ClHK.jpg)]
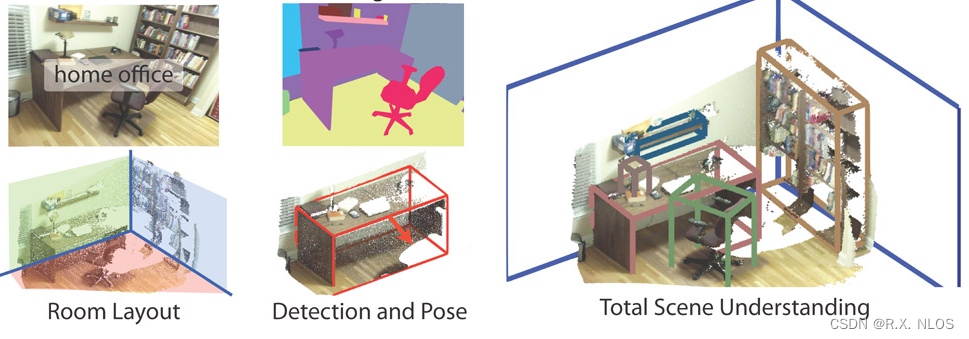
在大规模三维场景理解领域,常用的数据类型是点云。点云是由大量空间中的点组成的数据集,每个点包含位置、颜色等属性。点云数据可以从激光雷达扫描仪、多视图立体成像系统等设备获取。
2 原理介绍和推导
2.1 数据预处理
在进行三维场景理解之前,首先需要对原始点云数据进行预处理,以减少噪声、填补缺失值等。预处理的方法包括降采样、滤波等。降采样可以通过随机抽样、体素网格滤波等方法实现;滤波可以通过高斯滤波、双边滤波等方法实现。
2.2 特征提取
在预处理完成后,需要从点云数据中提取有用的特征,以支持后续的场景理解任务。特征提取的方法包括基于局部的方法和基于全局的方法。基于局部的方法从点云的局部邻域中提取特征,如法线估计、曲率估计等;基于全局的方法从整个点云中提取特征,如轴对齐边界框、凸包等。
2.3 场景分割与分类
点云特征提取完成后,接下来的任务是对场景进行分割和分类。场景分割将点云划分为多个相互关联的区域,如地面、建筑物、植被等;场景分类则为每个区域分配一个类别标签。场景分割和分类的方法包括基于传统机器学习的方法(如支持向量机、随机森林等)和基于深度学习的方法(如卷积神经网络、循环神经网络等)。深度学习方法在近年来取得了显著的进展,尤其是针对大规模点云数据的处理。
汇总|三维语义场景理解的数据集-极市开发者社区
3 研究现状
3.1 基于深度学习的方法
近年来,基于深度学习的方法在大规模三维场景理解领域取得了显著的成果。这些方法通常采用卷积神经网络(CNN)或循环神经网络(RNN)作为基本模型,以处理点云数据的特点。代表性的方法包括:
-
PointNet:一种直接处理点云数据的神经网络结构,通过共享权重的多层感知器(MLP)实现对点云中每个点的特征提取,并通过最大池化层实现全局特征的提取。PointNet可以用于点云分类、分割等任务。
-
PointCNN:一种将卷积操作扩展到点云数据的方法,通过学习一个空间变换矩阵,将点云中的点映射到规范化的坐标系中,从而实现卷积操作。PointCNN可以用于点云分类、分割等任务。
-
Graph Attention Networks (GAT):一种基于图神经网络的方法,将点云数据表示为图结构,并通过注意力机制实现自适应邻域特征的融合。GAT可以用于点云分类、分割等任务。
3.2 自监督学习方法
自监督学习(SSL)是一种无需人工标注数据的训练方法,通过设计特定的任务,使神经网络从无标签数据中学习有用的特征。在大规模三维场景理解领域,自监督学习方法具有很大的潜力,可以降低数据标注的成本并提高模型的泛化能力。代表性的方法包括:
-
Contrastive Learning:一种基于对比学习的方法,通过将相似的数据点映射到相近的特征空间,同时将不相似的数据点映射到远离的特征空间,实现无监督特征学习。Contrastive Learning可以用于点云特征的预训练和领域适应等任务。
-
Cycle Consistency:一种基于循环一致性的方法,通过设计一个可逆的数据变换任务(如旋转、翻转等),使神经网络学会在变换前后的数据空间中建立对应关系。Cycle Consistency可以用于点云特征的预训练和领域适应等任务。
4 挑战和未来展望
大规模三维场景理解领域仍然面临诸多挑战,如数据不完整性、噪声干扰、计算资源限制等。为了解决这些挑战,研究者们正在探索更先进的技术方法,以提高三维场景理解的精度、鲁棒性和实时性。未来的研究方向可能包括:
-
多模态融合:通过整合来自不同传感器(如激光雷达、相机、声呐等)的数据,实现对三维场景的更全面、准确的理解。多模态融合方法需要考虑数据的异构性、时空对齐等问题。
-
动态场景理解:在实际应用中,三维场景往往是动态变化的,如行人、车辆等移动目标。动态场景理解需要考虑目标的运动状态、相互遮挡等问题,以实现对场景的实时、连续分析。
-
可解释性和安全性:随着神经网络模型的复杂度不断增加,模型的解释性和安全性问题日益突出。研究者们需要探索更具可解释性的模型结构、训练策略,以及有效的安全防御手段,以支持高可信度的三维场景理解。
总之,大规模三维场景理解是一个充满挑战和机遇的研究领域。随着计算机视觉和机器学习技术的不断进步,我们有理由相信,未来的三维场景理解技术将更加智能、高效、安全,为无人驾驶、机器人导航、增强现实和虚拟现实等应用带来更加美好的体验。
5 代码案例
以下是一个使用 Python 和 PyTorch 实现的简单三维点云分类模型示例。我们使用 PointNet 网络结构进行点云分类任务。请注意,这只是一个简化的示例。
import torch
import torch.nn as nn
import torch.nn.functional as F
class TNet(nn.Module):
def __init__(self, k=3):
super(TNet, self).__init__()
self.k = k
self.conv1 = nn.Conv1d(k, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k * k)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = torch.eye(self.k).view(1, self.k * self.k).repeat(batch_size, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x
class PointNet(nn.Module):
def __init__(self, num_classes):
super(PointNet, self).__init__()
self.tnet1 = TNet(k=3)
self.tnet2 = TNet(k=64)
self.conv1 = nn.Conv1d(3, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, num_classes)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
B, N, _ = x.size()
input_transform = self.tnet1(x)
x = torch.bmm(x, input_transform)
x = x.transpose(2, 1)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
feature_transform = self.tnet2(x)
x = torch.bmm(x.transpose(2, 1), feature_transform).transpose(2, 1)
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.dropout(x)
x = self.fc3(x)
return F.log_softmax(x, dim=1), feature_transform
使用该模型对点云数据进行分类:
point_cloud = torch.randn(1, 1024, 3) # 假设有一个包含 1024 个点的点云数据
point_cloud = point_cloud.transpose(2, 1) # 调整张量形状以匹配网络输入
log_probs, _ = pointnet(point_cloud)
probs = torch.exp(log_probs)
prediction = torch.argmax(probs, dim=1)
print("分类概率:", probs)
print("预测类别:", prediction.item())
这个示例仅仅是一个起点,实际应用中,你需要根据具体任务调整网络结构、训练策略等,并使用真实的点云数据集进行训练和测试。