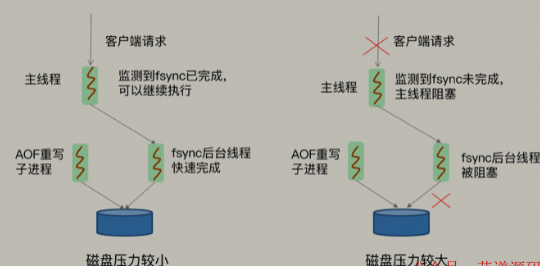
文章目录
- 一、检测相关(15篇)
- 1.1 Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
- 1.2 Shi-NeSS: Detecting Good and Stable Keypoints with a Neural Stability Score
- 1.3 HODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
- 1.4 Graph-level Anomaly Detection via Hierarchical Memory Networks
- 1.5 Feasibility of Universal Anomaly Detection without Knowing the Abnormality in Medical Images
- 1.6 LXL: LiDAR Exclusive Lean 3D Object Detection with 4D Imaging Radar and Camera Fusion
- 1.7 SSC3OD: Sparsely Supervised Collaborative 3D Object Detection from LiDAR Point Clouds
- 1.8 Efficient Visual Fault Detection for Freight Train Braking System via Heterogeneous Self Distillation in the Wild
- 1.9 A MIL Approach for Anomaly Detection in Surveillance Videos from Multiple Camera Views
- 1.10 End-to-End Out-of-distribution Detection with Self-supervised Sampling
- 1.11 Human-to-Human Interaction Detection
- 1.12 Detection of River Sandbank for Sand Mining with the Presence of Other High Mineral Content Regions Using Multi-spectral Images
- 1.13 Image Matters: A New Dataset and Empirical Study for Multimodal Hyperbole Detection
- 1.14 Obscured Wildfire Flame Detection By Temporal Analysis of Smoke Patterns Captured by Unmanned Aerial Systems
- 1.15 A Parts Based Registration Loss for Detecting Knee Joint Areas
一、检测相关(15篇)
1.1 Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
伪像映射:用于目标检测和三维定位的多模式语义映射
论文地址:
https://arxiv.org/abs/2307.01121

几何导航是当今机器人领域的一个成熟的领域,研究重点正在转向更高层次的场景理解,如语义映射。当机器人需要与环境交互时,它必须能够理解周围环境的上下文信息。这项工作的重点是分类和定位地图内的对象,这是正在建设(SLAM)或已经建成。为了进一步探索这个方向,我们提出了一个框架,可以自主检测和定位在已知环境中的预定义对象,使用多模态传感器融合方法(结合RGB和深度数据从RGB-D相机和激光雷达)。该框架由三个关键要素组成:通过RGB数据理解环境,通过多模态传感器融合估计深度,以及管理伪像(即,过滤和稳定测量)。实验表明,该框架可以准确地检测出真实样本环境中98%的目标,无需后期处理,而85%和80%的目标是使用单个RGBD相机或RGB +激光雷达设置分别映射。与单传感器(相机或激光雷达)实验的比较进行表明,传感器融合允许机器人准确地检测近和远的障碍物,这将是噪声或不精确的纯视觉或基于激光的方法。
1.2 Shi-NeSS: Detecting Good and Stable Keypoints with a Neural Stability Score
施奈斯:用神经稳定性评分检测良好和稳定的关键点
论文地址:
https://arxiv.org/abs/2307.01069

学习特征点检测器由于关键点的定义的模糊性以及相应地需要针对这样的点专门准备的地面实况标签而提出挑战。在我们的工作中,我们解决了这两个问题,利用手工制作的Shi检测器和神经网络的组合。我们建立在由Shi检测器提供的原则性和局部化关键点的基础上,并使用由神经网络回归的关键点稳定性得分-神经稳定性得分(NeSS)来执行它们的选择。因此,我们的方法被命名为Shi-NeSS,因为它结合了Shi检测器和关键点稳定性得分的属性,并且它只需要训练图像集,而无需数据集预标记或重建对应标记的需要。我们评估了Shi-NeSS的HPatches,ScanNet,MegaDepth和IMC-PT,展示了国家的最先进的性能和良好的泛化下游任务。
1.3 HODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
HODINet:用于RGB-D显著目标检测的高阶差异交互网络
论文地址:
https://arxiv.org/abs/2307.00954

RGB-D显着对象检测(SOD)旨在通过联合建模RGB和深度信息来检测显着区域。大多数RGB-D SOD方法应用相同类型的骨干和融合模块,以相同地学习多模态和多级特征。然而,这些特征对最终显著性结果的贡献不同,这引起了两个问题:1)如何对RGB图像和深度图的差异特性进行建模; 2)如何在不同阶段融合这些跨模态特征。在本文中,我们提出了一个高阶差异相互作用网络(HODINet)的RGB-D SOD。具体地,我们首先采用基于变换器和基于CNN的架构作为主干来分别编码RGB和深度特征。然后,精细地提取高阶表示,并嵌入空间和信道注意,以实现不同阶段的跨模态特征融合。具体来说,我们设计了一个高阶空间融合(HOSF)模块和一个高阶信道融合(HOCF)模块来融合前两个阶段和后两个阶段的功能,分别。此外,采用级联金字塔重构网络,以自顶向下的方式逐步解码融合特征。广泛的实验进行了七个广泛使用的数据集,以证明所提出的方法的有效性。我们在四个评估指标下实现了对24个国家的最先进的方法的竞争性能。
1.4 Graph-level Anomaly Detection via Hierarchical Memory Networks
基于分层记忆网络的图级异常检测
论文地址:
https://arxiv.org/abs/2307.00755

图级异常检测旨在识别与图集中的大多数相比表现出异常结构和节点属性的异常图。一个主要的挑战是学习正常模式表现在细粒度和整体视图的图形,以识别图形是异常的部分或整体。为了应对这一挑战,我们提出了一种新的方法,称为分层存储器网络(HimNet),它学习分层存储器模块-节点和图形存储器模块-通过图形自动编码器网络架构。节点级存储器模块被训练为对节点之间的细粒度内部图交互进行建模以用于检测局部异常图,而图级存储器模块专用于学习整体正常模式以用于检测全局异常图。这两个模块联合优化,以检测本地和全球异常图。对来自不同领域的16个真实世界图数据集的广泛实证结果表明,i)HimNet显著优于最先进的方法,ii)它对异常污染具有鲁棒性。代码可从以下网址获得:https://github.com/Niuchx/HimNet。
1.5 Feasibility of Universal Anomaly Detection without Knowing the Abnormality in Medical Images
医学图像不知道异常情况下通用异常检测的可行性
论文地址:
https://arxiv.org/abs/2307.00750

最近已经开发了许多异常检测方法,特别是深度学习方法,以通过在训练期间仅采用正常图像来识别异常图像形态。不幸的是,许多现有的异常检测方法针对特定的“已知”异常(例如,脑肿瘤、骨分数、细胞类型)。此外,即使在训练过程中仅使用正常图像,在验证过程期间也经常采用异常图像(例如,异常图像)。历元选择、超参数调整),这可能无意地泄漏假定的“未知”异常。在这项研究中,我们调查了这两个基本方面的普遍异常检测医学图像(1)跨四个医学数据集比较各种异常检测方法,(2)研究关于如何在仅使用正常图像的验证阶段期间无偏地选择最佳异常检测模型的不可避免但经常被忽视的问题,(3)提出了一种简单的决策级集成方法,在不知道异常的情况下,充分利用不同类型异常检测的优点。我们的实验结果表明,没有一个评估的方法在所有数据集上始终达到最佳性能。我们提出的方法增强了一般性能的鲁棒性(平均AUC 0.956)。
1.6 LXL: LiDAR Exclusive Lean 3D Object Detection with 4D Imaging Radar and Camera Fusion
LXL:激光雷达独有的4D成像雷达和相机融合的倾斜3D目标检测
论文地址:
https://arxiv.org/abs/2307.00724

作为一种新兴技术和相对便宜的设备,4D成像雷达已经被证实在自动驾驶中执行3D物体检测方面是有效的。然而,4D雷达点云的稀疏性和噪声性阻碍了进一步的性能改善,并且缺乏对其与其他模态融合的深入研究。另一方面,大多数基于摄像机的感知方法通过Lift-Splat-Shoot(LSS)中提出的“基于深度的溅射”将提取的图像透视图特征几何地转换为鸟瞰图,一些研究人员利用其他模态,如LiDAR或普通汽车雷达进行增强。最近,一些作品已经将“采样”策略应用于图像视图变换,表明即使没有图像深度预测,它也优于“飞溅”。然而,“采样”的潜力并没有完全释放出来。本文研究了基于摄像机和四维成像雷达融合的“采样”视图变换策略的三维目标检测。在所提出的模型中,LXL,预测的图像深度分布图和雷达3D占用网格被用来帮助图像视图变换,称为“雷达占用辅助的基于深度的采样”。在VoD和TJ 4DRadSet数据集上的实验表明,该方法比现有的3D目标检测方法有显着的优势,没有花里胡哨。消融研究表明,我们的方法在不同的增强设置中表现最好。
1.7 SSC3OD: Sparsely Supervised Collaborative 3D Object Detection from LiDAR Point Clouds
SSC3OD:基于稀疏监督的激光雷达点云协同三维目标检测
论文地址:
https://arxiv.org/abs/2307.00717

协同3D目标检测以其多个智能体之间的交互优势,在自动驾驶中得到了广泛的研究。然而,现有的协作式3D对象检测器在一个完全监督的范例严重依赖于大规模的注释的3D边界框,这是劳动密集型和耗时的。为了解决这个问题,我们提出了一个稀疏监督的协同3D对象检测框架SSC 3 OD,它只需要每个代理随机标记场景中的一个对象。具体地,该模型由两个新颖的组件组成,即,基于柱的掩码自动编码器(Pillar-MAE)和实例挖掘模块。Pillar-MAE模块旨在以自我监督的方式对高级语义进行推理,实例挖掘模块在线为协作检测器生成高质量的伪标签。通过引入这些简单而有效的机制,所提出的SSC 3 OD可以减轻不完整的注释的不利影响。我们基于协作感知数据集生成稀疏标签来评估我们的方法。在三个大规模数据集上进行的大量实验表明,我们提出的SSC 3 OD可以有效地提高稀疏监督协作3D对象检测器的性能。
1.8 Efficient Visual Fault Detection for Freight Train Braking System via Heterogeneous Self Distillation in the Wild
基于异质自蒸馏的货车制动系统野外高效视觉故障检测
论文地址:
https://arxiv.org/abs/2307.00701

在受限的硬件环境下,高效的货物列车视觉故障检测是保证铁路安全运行的关键环节。尽管基于深度学习的方法在对象检测方面表现出色,但货运训练故障检测的效率仍不足以应用于现实世界的工程。本文提出了一种异构的自蒸馏框架,以确保检测的准确性和速度,同时满足低资源需求。输出特征知识中的特权信息可以通过蒸馏从教师转移到学生模型以提高性能。我们首先采用一个轻量级的骨干来提取特征,并生成一个新的异构知识颈。这样的颈部通过并行编码对通道之间的位置信息和长程依赖性进行建模,以优化特征提取能力。然后,我们利用一般分布,以获得更可靠和准确的包围盒估计。最后,我们采用了一种新的损失函数,使网络很容易集中在标签附近的值,以提高学习效率。四个故障数据集上的实验表明,我们的框架可以实现超过37帧每秒,并保持最高的精度与传统的蒸馏方法相比。此外,与最先进的方法相比,我们的框架表现出更有竞争力的性能,更低的内存使用量和最小的模型大小。
1.9 A MIL Approach for Anomaly Detection in Surveillance Videos from Multiple Camera Views
一种多视角监控视频异常检测的MIL方法
论文地址:
https://arxiv.org/abs/2307.00562

遮挡和杂波是导致监控视频中异常检测困难的两种场景状态。此外,异常事件是罕见的,因此,类别不平衡和缺乏标记的异常数据也是该任务的关键特征。因此,弱监督方法被大量研究用于该应用。在本文中,我们解决这些典型的问题,异常检测在监控视频相结合的多实例学习(MIL),以处理缺乏标签和多个摄像机视图(MC),以减少遮挡和杂波的影响。在由此产生的MC-MIL算法中,我们应用多相机组合损失函数来训练回归网络与Sultani的MIL排名函数。为了评估这里首次提出的MC-MIL算法,多相机PETS-2009基准数据集被重新标记用于来自多个相机视图的异常检测任务。结果显示,与单摄像头配置相比,F1分数的性能有了显着提高。
1.10 End-to-End Out-of-distribution Detection with Self-supervised Sampling
基于自监督采样的端到端非分布检测
论文地址:
https://arxiv.org/abs/2307.00519

分布外(OOD)检测使模型在封闭集上训练,以识别开放世界中的未知数据。尽管许多现有技术已经产生了相当大的改进,但是仍然存在两个关键的障碍。首先,尚未提出一个统一的视角来看待具有个人设计的发展艺术,这对于提供相关方向的见解至关重要。其次,大多数研究集中在预训练特征的后处理方案上,而忽视了端到端训练的优越性,极大地限制了OOD检测的上限。为了解决这些问题,我们提出了一个通用的概率框架来解释许多现有的方法和OOD数据自由模型,即自监督采样OOD检测(SSOD),以展现端到端学习的潜力。基于卷积的局部特性,SSOD有效地利用来自于分布(ID)数据的自然OOD信号。通过这些监督,它联合优化OOD检测和传统的ID分类。大量的实验表明,SSOD在许多大规模基准测试上建立了有竞争力的最先进的性能,在那里它比最近的方法,如KNN,以很大的幅度,例如,FPR95时SUN为48.99%至35.52%。
1.11 Human-to-Human Interaction Detection
人与人的交互检测
论文地址:
https://arxiv.org/abs/2307.00464

全面了解视频流中感兴趣的人与人之间的互动,如排队、握手、打斗和追逐,对于校园、广场和公园等区域的公共安全监控具有极其重要的意义。不同于传统的人类交互识别,它使用编排的视频作为输入,忽略并发的交互组,并在不同的阶段进行检测和识别,我们引入了一个新的任务,名为人与人的交互检测(HID)。HID致力于在一个模型中检测主体,识别个人明智的行为,并根据他们的互动关系对人进行分组。首先,基于流行的AVA数据集创建的动作检测,我们建立了一个新的HID基准,称为AVA-Interaction(AVA-I),通过添加注释的交互关系,在一帧一帧的方式。AVA-I由85,254帧和86,338个交互组组成,每个图像最多包括4个并发交互组。第二,我们提出了一种新的基线方法SaMFormer HID,包含一个视觉特征提取器,分裂阶段,利用基于变换器的模型解码动作实例和交互式组,和一个合并阶段,重建实例和组之间的关系。所有SaMFormer组件都以端到端的方式进行联合培训。在AVA-I上的大量实验验证了SaMFormer优于代表性方法的优越性。数据集和代码将公开,以鼓励更多的后续研究。
1.12 Detection of River Sandbank for Sand Mining with the Presence of Other High Mineral Content Regions Using Multi-spectral Images
利用多光谱图像检测其他高矿物含量区域的采砂河流沙洲
论文地址:
https://arxiv.org/abs/2307.00314

采砂是一个蓬勃发展的行业。河流沙洲是采砂的主要来源之一。河道采砂潜在区域的探测直接影响到经济、社会和环境。在过去,半监督和监督技术已被用于检测采矿区域,包括采砂。一些技术采用多模态分析结合不同的模态,如多光谱成像,合成孔径雷达(SAR)成像,航空图像,和点云数据。然而,区别河流沙洲地区的光谱特征尚未得到充分的探索。本文提出了一种新的方法来检测河流沙洲地区的采砂利用多光谱图像没有任何标记的数据,在季节。与河流的联系和丰富的矿物是这一地区最突出的特征。拟议的工作使用这些区别特征来确定河流沙洲地区的光谱特征,这对其他高矿物丰度地区是鲁棒的。它遵循两个步骤的方法,首先,潜在的高矿物质区域被检测到,然后,它们被隔离使用河流的存在。所提出的技术提供了平均准确度,精确度和召回率分别为90.75%,85.47%和73.5%,在没有使用任何标记的数据集从Landsat 8图像的季节。
1.13 Image Matters: A New Dataset and Empirical Study for Multimodal Hyperbole Detection
IMAGE Matters:一种新的多模式夸张检测数据集及实证研究
论文地址:
https://arxiv.org/abs/2307.00209

夸张是一种常见的语言现象。夸张的检测是理解人类表情的重要组成部分。目前已经有一些关于夸张识别的研究,但大多数研究都是针对语篇情态的。然而,随着社交媒体的发展,人们可以用各种模态来创建双曲表达,包括文本、图像、视频等。在本文中,我们专注于多模态夸张检测。我们创建了一个多模态检测数据集\footnote{该数据集将向社区发布。}从微博(一个中国的社交媒体),并进行了一些研究。本文将微博中的文本和图像作为两种模态,探讨了文本和图像在夸张检测中的作用。不同的预先训练的多模态编码器也在该下游任务上进行评估,以显示它们的性能。此外,由于该数据集是由五个不同的主题构建的,我们还评估了不同模型的跨域性能。这些研究可以作为一个基准,并指出进一步研究的方向多模态夸张检测。
1.14 Obscured Wildfire Flame Detection By Temporal Analysis of Smoke Patterns Captured by Unmanned Aerial Systems
基于无人机烟雾模式时间分析的隐蔽野火火焰探测
论文地址:
https://arxiv.org/abs/2307.00104

本研究论文解决了使用仅配备RGB摄像机的无人机实时检测模糊野火(当火焰被树木,烟雾,云和其他自然障碍物覆盖时)的挑战。我们提出了一种新的方法,采用语义分割的基础上的时间分析的烟雾模式在视频序列。我们的方法利用基于深度卷积神经网络架构的编码器-解码器架构,具有预训练的CNN编码器和用于解码的3D卷积,同时使用特征的顺序堆叠来利用时间变化。预测的火灾位置可以帮助无人机有效地抗击森林火灾,并在准确的火焰位置精确定位阻燃化学品滴。我们将我们的方法应用到一个策划的数据集,从FLAME 2数据集,包括RGB视频以及IR视频,以确定地面实况。我们所提出的方法具有独特的属性,检测模糊的火,并实现了85.88%的骰子得分,同时实现了92.47%的高精度和90.67%的分类准确率的测试数据显示有前途的结果时,目视检查。事实上,我们的方法优于其他方法的一个显着的边际视频级火灾分类,我们获得了约100%的准确率使用MobileNet+CBAM作为编码器骨干。
1.15 A Parts Based Registration Loss for Detecting Knee Joint Areas
一种基于零件的膝关节区域检测方法
论文地址:
https://arxiv.org/abs/2307.00083

在本文中,被认为是基于零件的损失微调登记膝关节区域。这里的部分被定义为抽象的特征向量的位置,它们是自动选择的参考图像。对于测试图像,鼓励检测到的部分具有与参考图像中的对应部分相似的空间配置。