建模核心代码
#员工自评AutoML
from autogluon.tabular import TabularDataset, TabularPredictor
import warnings
warnings.filterwarnings('ignore')
train_data = TabularDataset(train_df2)
# 预测标签
label = '员工自评'
# 模型保存文件名
save_path = '../data/AUO-train/model/AM/worker5/worker5.pkl'
# 建立预测模型,verbosity(0~4),默认为2就好
worker5 = TabularPredictor(label=label,path=save_path,verbosity=2)
# presets='best_quality'不考虑时间成本,追求最好模型
worker5.fit(train_data,presets='best_quality',num_bag_folds=5,num_bag_sets=1,num_stack_levels=1)
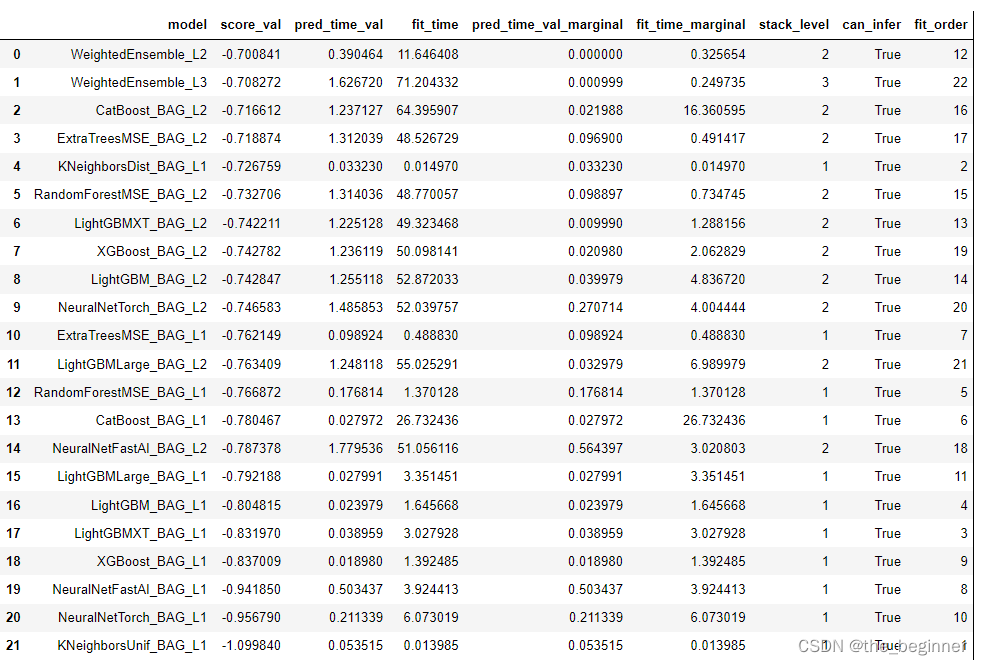
# 输出模型表现
worker5.leaderboard(silent=True)
训练结果
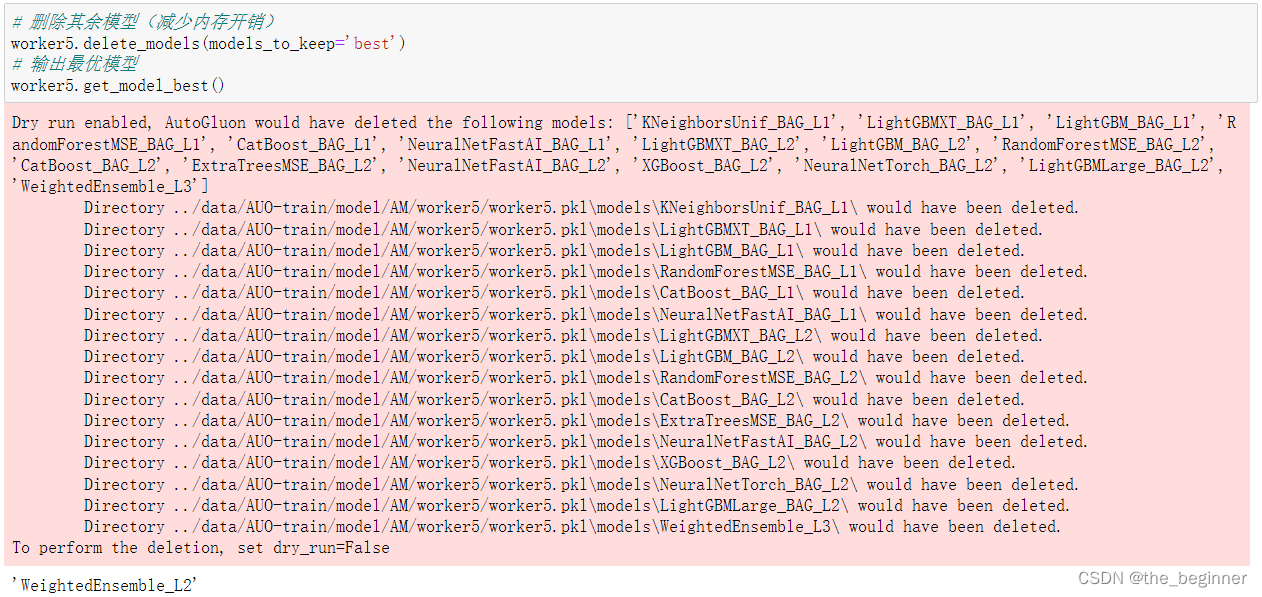
保留最优模型
# 删除其余模型(减少内存开销)
worker5.delete_models(models_to_keep='best')
# 输出最优模型
worker5.get_model_best()
保存模型
import sklearn.externals
import joblib
#保存模型
joblib.dump(worker5, '../data/AUO-train/model/AM/worker5/worker5_best_0705.pkl')

加载模型
#加载模型
import joblib
model_best=joblib.load('../data/AUO-train/model/AM/worker5/worker5_best.pkl')
使用模型进行预测
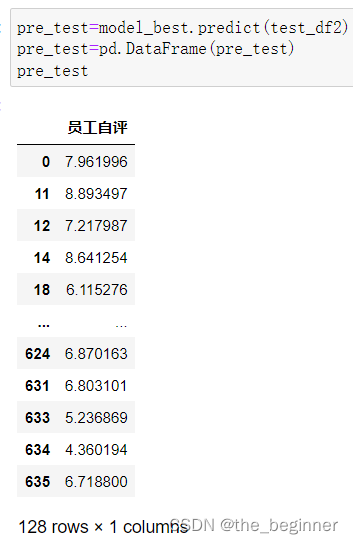
pre_test=model_best.predict(test_df2)
pre_test=pd.DataFrame(pre_test)
pre_test
模型评估
自定义模型评估函数
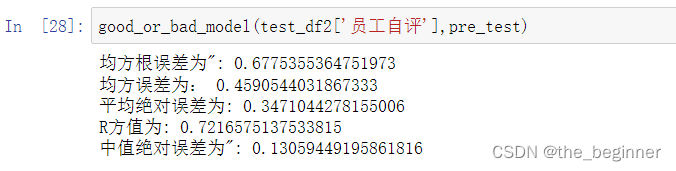
def good_or_bad_model(y_test, y_test_pred):
from sklearn.metrics import explained_variance_score, \
mean_absolute_error, mean_squared_error, \
median_absolute_error, r2_score
print(f'均方根误差为": {np.sqrt(mean_squared_error(y_test, y_test_pred))} ')
print('均方误差为:', mean_squared_error(y_test, y_test_pred))
print(f'平均绝对误差为: {mean_absolute_error(y_test, y_test_pred)}')
print(f'R方值为: { r2_score(y_test, y_test_pred)} ')
print(f'中值绝对误差为": {median_absolute_error(y_test, y_test_pred)} ')
建模数据+和核心代码下载:1积分