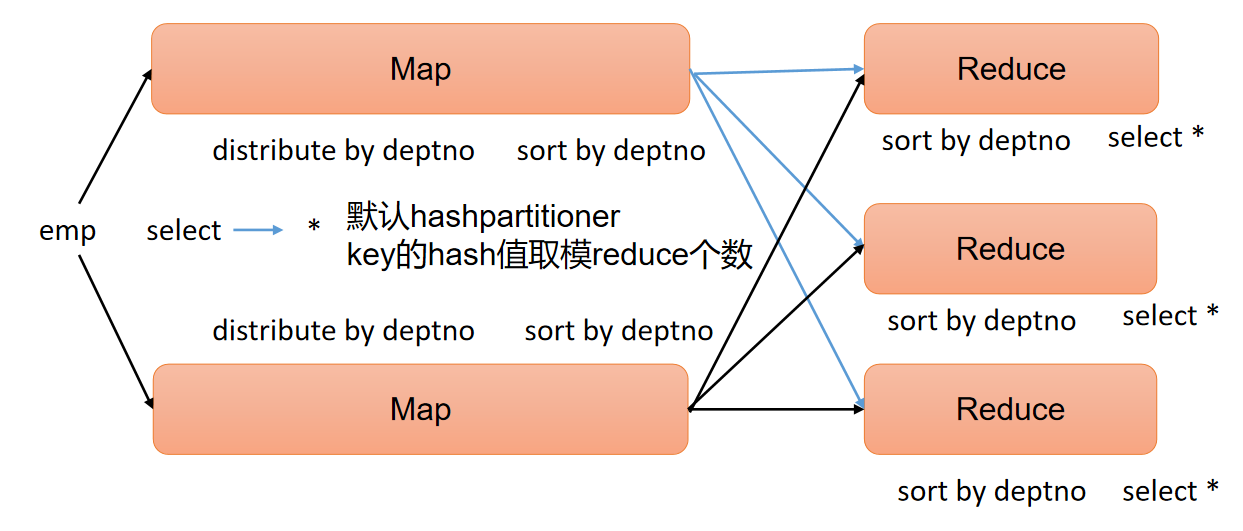
问题现象
在性能测试中,分别对两个版本差异间隔一天的 ShardingSphere-Proxy 做性能测试,发现版本更新的 Proxy 比旧的 Proxy 在 TPC-C 场景下峰值 tpmC 下降了 7% 左右。
排查过程
在性能测试期间,使用 async-profiler 分别对两个进程进行采样。
火焰图未发现明显代码路径异常
使用 IDEA 对比火焰图差异,发现性能下降的 Proxy 在 I/O 相关调用的比例略微减少(绿色部分),在 ShardingSphere 计算逻辑的比例略微增加(红色部分)。
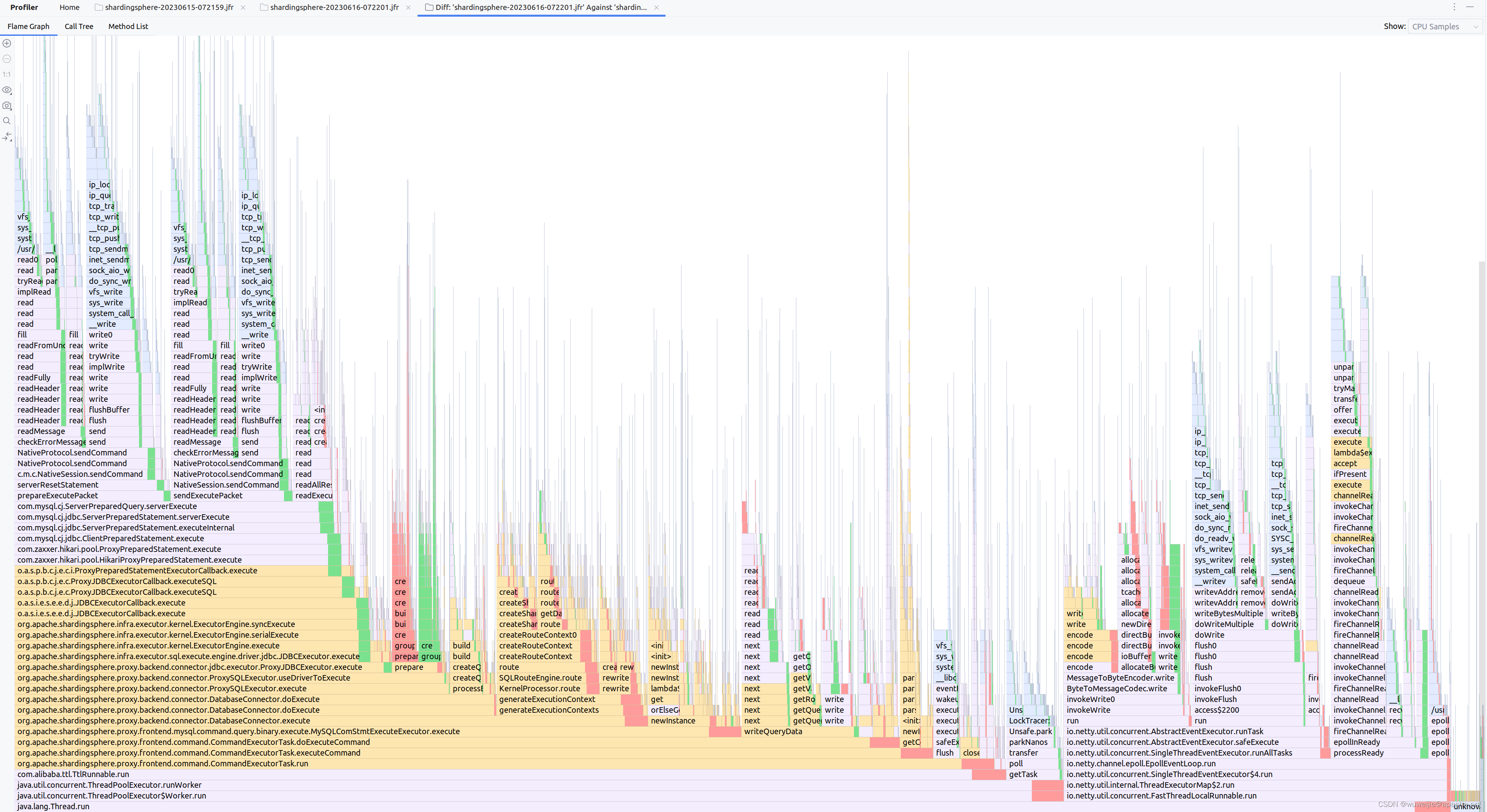
但是,从火焰图看并没有发现性能下降的 Proxy 有什么新增的逻辑。
CPU 使用率存在细微差异
async-profiler 采样期间,每秒会读取一次 JVM 进程的用户态/内核态的 CPU 使用率,以及系统 CPU 使用率。
有时候,从 CPU 使用率的细微差异可以发现一些异常。
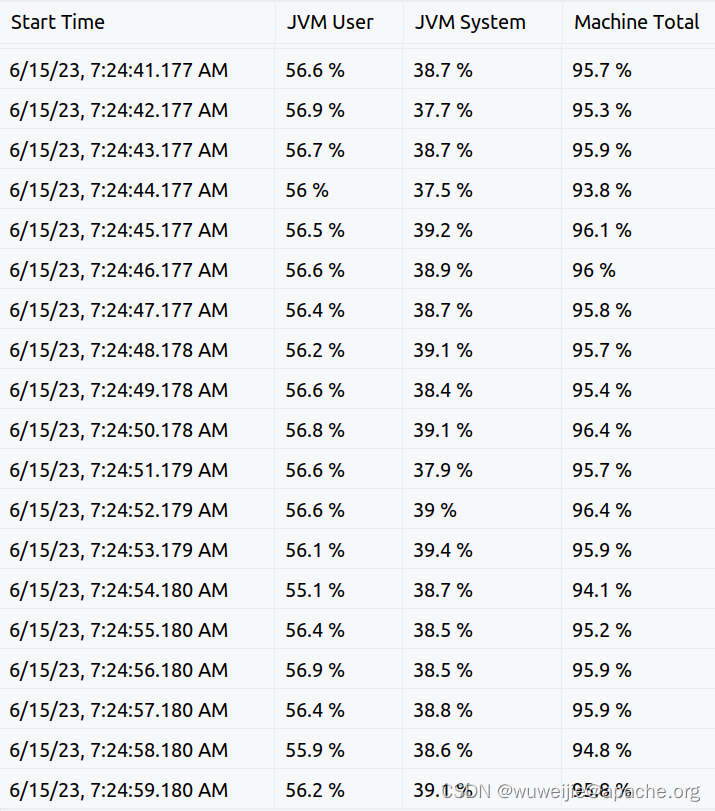
性能正常的 ShardingSphere-Proxy
性能下降的 ShardingSphere-Proxy
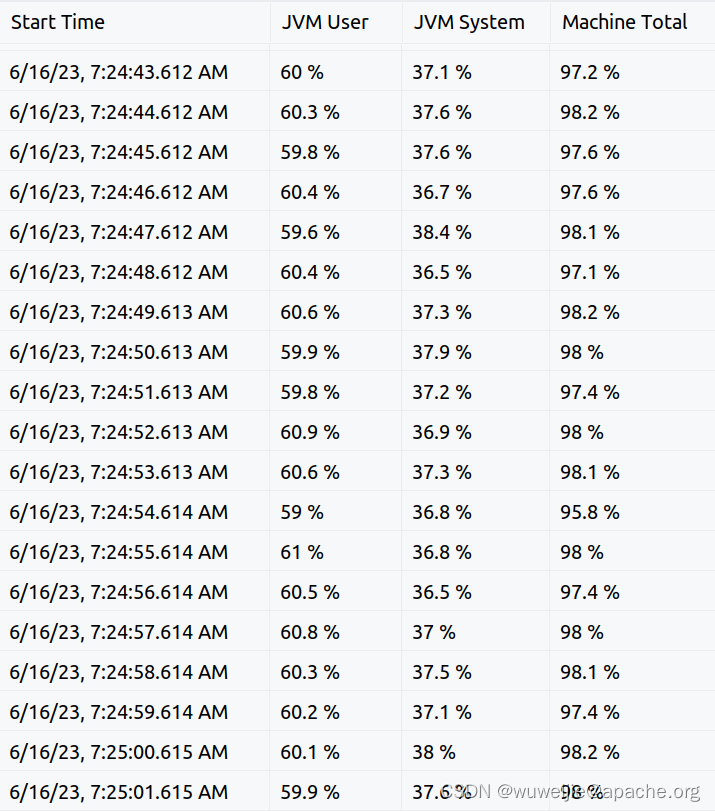
性能正常的 Proxy 进程 JVM User 使用率更低,JVM System 更高;性能异常的 Proxy 进程 JVM User 使用率略高,JVM System 略低。
这个现象和上一节火焰图对比差异能够对应上,看起来性能异常的 Proxy 在 ShardingSphere 的计算逻辑上 CPU 消耗更多。
但这还不能确定性能问题的原因,还需要更多信息。
从 Java 进程启动时的 Warning 信息中发现端倪
在同一个环境下,分别对两个 ShardingSphere-Proxy 执行 start.sh -v 查看版本时,发现其中一个 Proxy 的脚本执行后 JVM 给出了两行警告信息,另一个 Proxy 却没有警告信息。
+ /tmp/shardingsphere-proxy/bin/start.sh -v
/usr/local/openjdk-17/bin/java
we find java version: java17, full_version=17.0.2, full_path=/usr/local/openjdk-17/bin/java
OpenJDK 64-Bit Server VM warning: UseNUMA is not fully compatible with SHM/HugeTLBFS large pages, disabling adaptive resizing (-XX:-UseAdaptiveSizePolicy -XX:-UseAdaptiveNUMAChunkSizing)
OpenJDK 64-Bit Server VM warning: Failed to reserve and commit memory. req_addr: 0x0000000400000000 bytes: 17179869184 page size: 2097152 (errno = 12).
ShardingSphere-5.3.3-SNAPSHOT
Branch: master
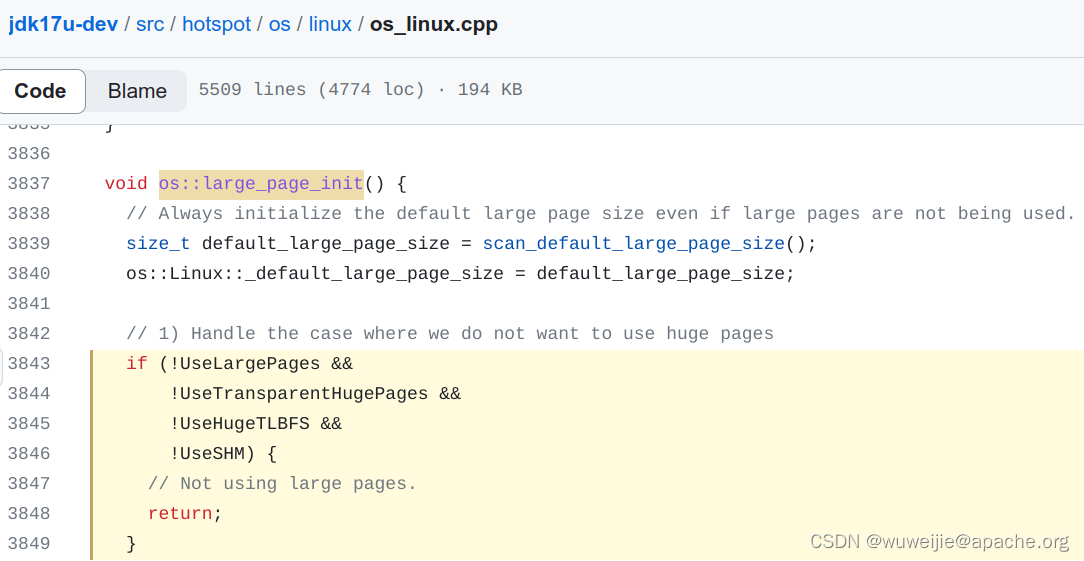
注意:虽然 Proxy 启动参数指定了
-XX:LargePageSizeInBytes=128m,但如果没有直接指定或间接(AggressiveHeap)指定-XX:+UseLargePages,实际上没有效果。
https://github.com/openjdk/jdk17u-dev/blob/9b895233315c21920edc7ba48915afdc0a5c220a/src/hotspot/os/linux/os_linux.cpp#L3843-L3849
查看两个 Proxy 的 JVM 参数,发现参数唯一差异在于,性能正常的 Proxy 指定了 -XX:+AggressiveHeap,而性能较差的没有。


给性能较差的 Proxy 加上 -XX:+AggressiveHeap 并重新测试性能后,发现性能恢复到正常水平。
JVM 参数 AggressiveHeap 原理是什么?
ShardingSphere-Proxy 启用了 AggressiveHeap
ShardingSphere-Proxy 的启动脚本 start.sh 会根据使用的 JRE 版本,适当增加可以提升性能的参数。笔者曾经在 start.sh 中增加了一些适用于 Java 11 和 Java 17 的 JVM 参数以提高 ShardingSphere-Proxy 的性能,其中有一项就是 -XX:+AggressiveHeap。
https://github.com/apache/shardingsphere/pull/15117

AggressiveHeap 是什么?
AggressiveHeap 这个参数比较冷门,能够搜到的资料非常有限,且搜索结果基本没有解释这个参数原理,而且有些博客对这个参数的理解存在偏差。
AggressiveHeap 是从 JDK 10 引入的一个参数,参数的解释就一句话:
Optimize heap options for long-running memory intensive apps
https://github.com/openjdk/jdk17u-dev/blob/9b895233315c21920edc7ba48915afdc0a5c220a/src/hotspot/share/gc/shared/gc_globals.hpp#L303-L304

这要如何理解?
解读 JDK 17 AggressiveHeap 源码
文档没说清楚,看源码是理解这个参数最直观准确的方式。
https://github.com/openjdk/jdk17u-dev/blob/9b895233315c21920edc7ba48915afdc0a5c220a/src/hotspot/share/runtime/arguments.cpp#L1789-L1895
源码较长,本文中不贴出。
总结一下,启用 AggressiveHeap 实际上不对应某一个具体的能力,而是让 JVM 自动设置一组 JVM 参数,大致如下:
- 如果没有指定
-Xmx,则指定并固定堆内存大小为Min(物理内存 / 2, 物理内存 - 160 MB); - 如果没有指定新生代比例,则设置
-XX:NewSize=堆内存的 3/8-XX:MaxNewSize=堆内存的 3/8; - 非 BSD 和 AIX 环境下,则启用
-XX:+UseLargePages; -XX:BaseFootPrintEstimate=堆内存大小,这个参数看起来和 ParallelGC 有关,笔者尚未进一步研究;- 固定 TLAB 空间为 256 KB
-XX:TLABSize=262144-XX:-ResizeTLAB; -XX:YoungPLABSize=262144(默认 8192);-XX:OldPLABSize=8192(默认 1024);- 自 JDK 9 起,默认的 GC 为 G1,但 AggressiveHeap 会使用 ParallelGC
-XX:+UseParallelGC; -XX:ThresholdTolerance=100(默认值 10),可能与回收频率控制有关,笔者尚未进一步研究;- 禁用 Full GC 前对新生代执行回收
-XX:-ScavengeBeforeFullGC。
总结
为什么其中一个 Proxy 移除了 AggressiveHeap?
笔者询问了 Proxy 移除 AggressiveHeap 的原因,大致如下:
- 目前 ShardingSphere-Proxy 在容器环境下(环境变量
IS_DOCKER不为空),会不指定-Xmx-Xms-Xmn等指定堆内存的参数,而是使用百分比的方式指定内存使用。-XX:InitialRAMPercentage=80.0-XX:MinRAMPercentage=80.0-XX:MaxRAMPercentage=80.0 - 在实际容器环境中部署发现:使用 ShardingSphere-Proxy 镜像,容器可用内存 16GB,但 JVM 进程的堆内存只有 8GB,与参数指定的 80% 相差较大。移除 AggressiveHeap 后,JVM 堆内存接近可用内存 80%。
https://github.com/apache/shardingsphere/blob/b483b4ca96a87012ed12bc398fa34db35ef7ab11/distribution/proxy/src/main/resources/bin/start.sh#L78-L82

AggressiveHeap 仅考虑了是否指定了堆内存的具体大小,通过 MaxRAMPercentage 指定内存使用百分比不在 AggressiveHeap 的考虑范围之内,因此,AggressiveHeap 的逻辑会覆盖 MaxRAMPercentage 指定的上限。
琐碎想法
笔者认为,通过百分比设置 ShardingSphere-Proxy 的内存不是一个非常稳妥的办法。笔者曾经接触过部署在 Kubernetes 上的一些 Java 项目是通过环境变量设置 JVM 参数,指定明确的堆内存大小也许是个更合适的方式。





![[网络安全提高篇] 一二一.恶意软件动态分析Cape沙箱Report报告的API序列批量提取详解](https://img-blog.csdnimg.cn/36f21b1bf14c4e52b8b3331651aadc4d.png#pic_center)