🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:python网络爬虫从基础到实战 欢迎订阅!后面的内容会越来越有意思~
💡往期推荐:
⭐️首先,我们前面讲了多篇基础内容:
【Python爬虫开发基础①】Python基础(变量及其命名规范)
【Python爬虫开发基础②】Python基础(正则表达式)
【Python爬虫开发基础③】Python基础(文件操作方法汇总)
【Python爬虫开发基础④】爬虫原理
【Python爬虫开发基础⑤】HTML概述与基本标签详解
【Python爬虫开发基础⑥】计算机网络基础(Web和HTTP)
【Python爬虫开发基础⑦】urllib库的基本使用
【Python爬虫开发基础⑧】XPath库及其基本用法
【Python爬虫开发基础⑨】jsonpath和BeautifulSoup库概述及其对比
⭐️在本文章之前,上一篇实战的文章:
【Python爬虫开发实战①】使用urllib以及XPath爬取可爱小猫图片
大家可以复制代码感受一下爬虫的魅力~
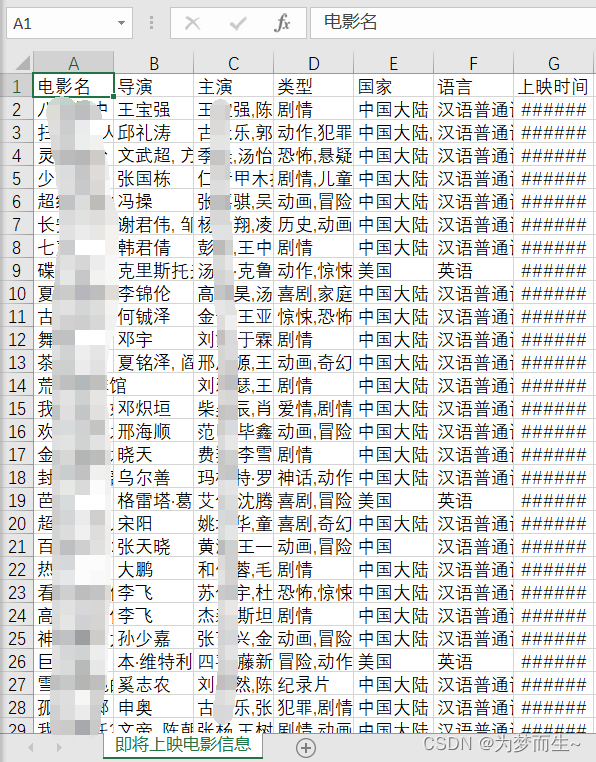
💡本期内容:我们来接着上次的解析库jsonpath,以及前面的urllib,进行一个比较有趣的实战:获取即将上映的电影信息
跟上期一样,我们先来看一下效果:
文章目录
- 1 需要使用的库
- 2 寻找接口并创建请求
- 3 发送请求并获取响应
- 4 使用jsonpath解析得到的json数据
1 需要使用的库
- urllib
urllib是Python的一个标准库,用于处理URL(统一资源定位符)的模块。它提供了一些常用的功能,包括发送请求、处理响应、解析URL等。
- 可以点击之前文章链接学习基础知识【Python爬虫开发基础⑦】urllib库的基本使用
- json
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它以易于阅读和编写的文本格式来表示结构化数据。JSON数据格式广泛用于互联网应用之间的数据传输,并且被各种编程语言支持。
- 使用python对json格式数据进行操作,可参考【Python爬虫开发基础③】Python基础(文件操作方法汇总)这篇文章
- jsonpath
JSONPath是一种用于从JSON数据中提取或查询数据的表达式语言。它最初由史蒂芬·摩根(Stephen Morgan)在2007年创建,并在2014年成为了IETF(互联网工程任务组)的标准。
- 大家可以通过上一篇文章了解一下jsonpath解析 【Python爬虫开发基础⑨】jsonpath和BeautifulSoup库概述及其对比
- csv
Python的csv是一个用于读取、写入和操作CSV(逗号分隔值)文件的模块。CSV文件是一种常见的用于存储和交换数据的文件格式,它将数据按照逗号进行分隔,并可使用文本编辑器进行查看和编辑。
在Python中,使用csv模块可以轻松地读取和写入CSV文件。它提供了一些用于处理CSV数据的函数和类,包括Reader、Writer和DictReader等。
- 大家同样可以通过这篇文章了解一下csv【Python爬虫开发基础③】Python基础(文件操作方法汇总)
2 寻找接口并创建请求
首先打开首页,我们究竟从哪里能得到想要的数据呢?有两种方法,一、通过定位得到HTML代码,通过解析代码得到想要的内容;二、通过抓包,得到主要的接口,通过对这个接口发送请求,就可以得到数据。
在这里,我们通过第二种方法,也就是抓包获取。
-
首先打开相应的网页,按F12打开开发者工具点击网络,并清除所有内容。
-
刷新页面,抓取到响应的数据,找到json格式数据,该接口就是我们需要的

3 发送请求并获取响应
下面我们开始写代码:
- 导入需要的库
import urllib.request
import json
import jsonpath
import csv
- 请求对象的定制
# 请求对象的定制
def create_request():
url = '(自己复制过来)'
headers = {
'Cookie':'(自己复制过来)',
'Referer':'(自己复制过来)',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url = url, headers = headers)
return request
- 获取网页源码
# 获取网页的源码
def get_content(request):
# 发送请求获取响应
response = urllib.request.urlopen(request)
# 对响应进行解码
content = response.read().decode('utf-8')
# print(content)
# 返回
return content
在这里得到的content就是获取到的响应数据
4 使用jsonpath解析得到的json数据
def analyze(content):
content = content.split('(')[1].split(')')[0]
with open('tpp.json', 'w', encoding='utf-8') as fp:
fp.write(content)
obj = json.load(open('tpp.json', 'r', encoding='utf-8'))
return obj
- 最后将获得的数据写入到csv文件中
def down_load(obj):
showName_list = jsonpath.jsonpath(obj, '$..showName')
director_list = jsonpath.jsonpath(obj, '$..director') # 95
leadingRole_list = jsonpath.jsonpath(obj, '$..leadingRole') # 90
type_list = jsonpath.jsonpath(obj, '$..type')
country_list = jsonpath.jsonpath(obj, '$..country')
language_list = jsonpath.jsonpath(obj, '$..language')
# duration_list = jsonpath.jsonpath(obj, '$..duration') # 57
openDay_list = jsonpath.jsonpath(obj, '$..openDay')
with open('./即将上映电影信息.csv', 'a', encoding='gbk', newline='') as f:
a = csv.writer(f)
field = ['电影名', '导演', '主演', '类型', '国家', '语言', '上映时间']
a.writerow(field)
print(['电影名', '导演', '主演', '类型', '国家', '语言', '上映时间'])
for i in range(len(leadingRole_list)):
list_data = [showName_list[i], director_list[i], leadingRole_list[i], type_list[i], country_list[i], language_list[i], openDay_list[i]]
a.writerow(list_data)
print(list_data)
- 最后,我们按顺序调用以上函数就可以实现了
# (1) 请求对象的定制
request = create_request()
# (2) 获取网页的源码
content = get_content(request)
# (3) 解析
obj = analyze(content)
# (4) 下载
down_load(obj)



![【数据结构与算法】将含有n个元素的整数数组A[0…n-1]的元素循环右移1≤m<n)位。要求算法的空间复杂度为O(1)。](https://img-blog.csdnimg.cn/0e4a9c7a3f7d4325a3fcbe145698b6d8.png)
![[MySQL]MySQL数据库基础](https://img-blog.csdnimg.cn/img_convert/fae5bf1d4fe0bd9963e7449f831c7aa8.png)