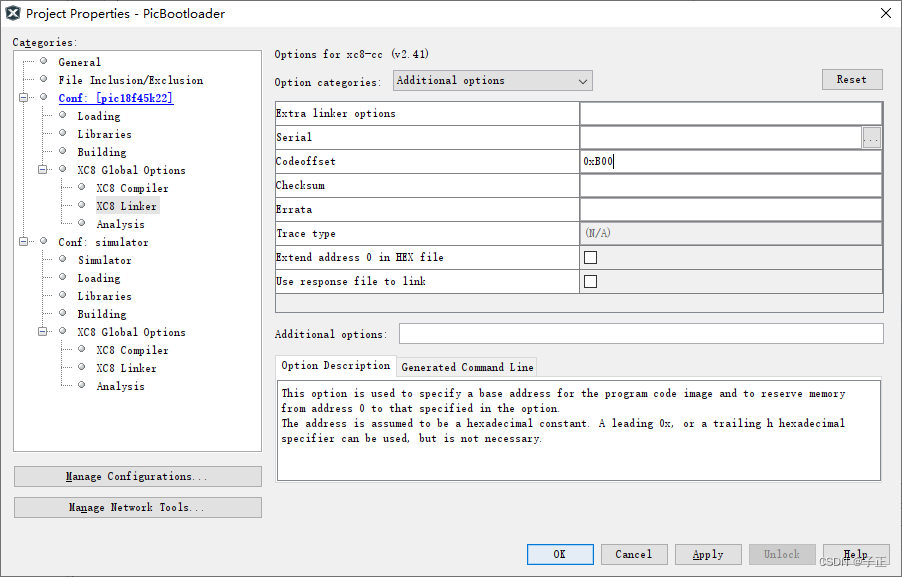
BERT模型蒸馏完全指南(原理/技巧/代码)
小朋友,关于模型蒸馏,你是否有很多问号:
- 蒸馏是什么?怎么蒸BERT?
- BERT蒸馏有什么技巧?如何调参?
- 蒸馏代码怎么写?有现成的吗?
今天rumor就结合Distilled BiLSTM/BERT-PKD/DistillBERT/TinyBERT/MobileBERT/MiniLM六大经典模型,带大家把BERT蒸馏整到明明白白!

注:文末附BERT面试点&相关模型汇总,还有NLP组队学习群的加群方式~
模型蒸馏原理
Hinton在NIPS2014**[1]**提出了知识蒸馏(Knowledge Distillation)的概念,旨在把一个大模型或者多个模型ensemble学到的知识迁移到另一个轻量级单模型上,方便部署。简单的说就是用小模型去学习大模型的预测结果,而不是直接学习训练集中的label。
在蒸馏的过程中,我们将原始大模型称为教师模型(teacher),新的小模型称为学生模型(student),训练集中的标签称为hard label,教师模型预测的概率输出为soft label,temperature(T)是用来调整soft label的超参数。



![NSS [SWPUCTF 2021 新生赛]Do_you_know_http](https://img-blog.csdnimg.cn/img_convert/1fb84350814d09070183136702e234ea.png)