首先我们要掌握 Kubernete 的一些核心概念。 这些核心可以帮助我们更好的理解 Kubernetes 的特性和工作机制。

集群组件
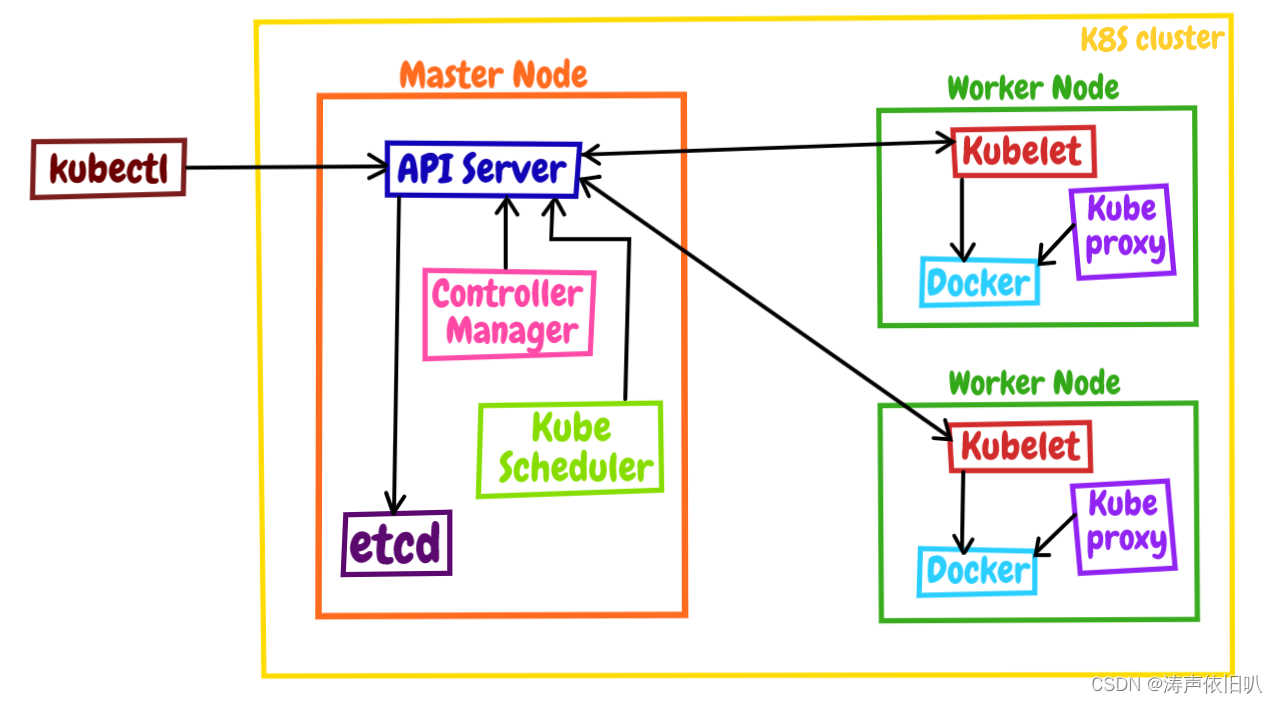
首先,Kubernetes 集群中包含2类节点,分别是:master控制节点和node工作节点。
master 控制节点 负责管理整个集群系统,可以说它是集群的网关和中枢,是Kubernetes 的大脑和心脏。
node 节点是Pod运行的地方,运行用户实际部署的应用。node的数量是很多的,构成了资源池,管理池化的资源就更加得心应手了。
master控制节点的组件
master控制节点中有4个核心组件,分别是kube-apiserver、kube-schedule、kube-controller-manager、ETCD。
- kube-apiserver 是Kubernetes Master节点中最核心的组件之一,它提供了RESTful API接口,用于管理和操作集群中的资源和应用程序。所有的Kubernetes操作都必须通过API Server进行,例如创建Pod、Service、Deployment等对象,以及获取集群的状态信息等。
- ETCD 是Kubernetes一致性和高可用的保证。它是一个分布式键值存储系统,它是Kubernetes集群中最重要的数据存储组件之一。etcd负责存储集群中的所有配置信息、状态信息和事件日志等数据,从而保证了Kubernetes集群的高可用性和可靠性。
- kube-controller-manager是Kubernetes Master节点中的另一个重要组件,它负责管理集群中的控制器对象,例如ReplicationController、Deployment、StatefulSet等。Controller Manager会自动监测集群中的资源状态,并根据预设的规则来执行相应的操作,例如创建新的Pod副本、更新Deployment的版本号等。
- kube-scheduler是Kubernetes Master节点中的第三个组件,它负责将新创建的Pod调度到合适的Node上运行。kube-scheduler会根据Pod的需求和Node的资源情况来选择最佳的调度策略,从而保证了Pod的负载均衡和高可用性。
这四个核心组件运行在集群的Pod里,我们可以通过 kubectl 命令查看这几个组件的运行状态,命令如下:
kubectl get pod -n kube-system
node 工作节点中的组件
node工作节点中有3个核心的组件,分别是:kubelet、kuber-proxy 和 容器运行时。下面我们分别看看他们都是干什么的。
-
kubelet 是Node节点中最核心的组件之一,它负责管理Pod的生命周期,例如创建、启动、停止和删除Pod等操作。kubelet会从API Server获取Pod的配置信息和状态信息,并将这些信息发送给Master节点进行管理和控制。
-
Kube-proxy 是Node节点中的另一个重要组件,它负责为Pod提供网络代理服务,负责管理容器的网络通信,简单来说就是为 Pod 转发 TCP/UDP 数据包。Kube-proxy会监听Node节点上的网络接口,并根据Pod的需求来选择最佳的网络策略,例如负载均衡、故障转移等。
-
容器运行时 是Node节点中的第三个组件,它负责运行容器化应用程序。Kubernetes支持多种容器运行时,例如Docker、CRI-O、containerd等。容器运行时 在kubelet的指挥下与kubelet协同工作,管理Pod的生命周期,确保Pod能够正确地运行和调度。
从Master 和 Node节点看Kubernetes的大致工作流程
-
用户提交应用程序:用户可以通过命令行工具、API或者Web界面等方式提交应用程序,例如创建Pod、Service、Deployment等对象。
-
API Server接收请求:当用户提交应用程序时,API Server会接收到相关的请求,并将这些请求转发给相应的控制器对象进行处理。
-
Controller Manager处理请求:Controller Manager是Kubernetes中的一个控制器对象,它负责管理集群中的控制器,例如ReplicationController、Deployment、StatefulSet等。当API Server接收到请求时,Controller Manager会自动监测集群中的资源状态,并根据预设的规则来执行相应的操作。
-
etcd存储数据:Controller Manager会将处理结果存储到etcd中,以便其他组件进行访问和查询。
-
kubelet管理Pod:当Controller Manager处理完请求后,kubelet会根据请求的内容来创建、启动、停止和删除Pod等操作。
-
Kube-proxy提供网络代理服务:Kube-proxy会监听Node节点上的网络接口,并根据Pod的需求来选择最佳的网络策略,例如负载均衡、故障转移等。
-
Container Runtime运行容器化应用程序:当kubelet创建Pod时,Container Runtime会与kubelet协同工作,确保Pod能够正确地运行和调度。
Kubernetes的工作流程是一个复杂的过程,需要多个组件协同工作才能完成。从Master和Node节点的角度来看,Kubernetes的工作流程主要包括用户提交应用程序、API Server接收请求、Controller Manager处理请求、etcd存储数据、kubelet管理Pod、Kube-proxy提供网络代理服务以及Container Runtime运行容器化应用程序等步骤。
操作对象
Pod 的理解
Pod是Kubernetes中最小的可部署单元,它包含了一个或多个紧密关联的容器。Pod可以共享网络和存储资源,并且可以在集群中进行调度和管理。
Pod的设计使得应用程序可以在同一个物理主机上运行,从而提高了应用程序的性能和可靠性。在Kubernetes中,Pod是最基本的调度单位,所有的服务都必须被打包成Pod才能被调度到集群中。
Pod的主要特点包括:
-
隔离性:每个Pod都是独立的运行环境,它们之间相互隔离,不会互相干扰。这意味着在一个Pod中的容器崩溃或者出现问题时,不会影响到其他Pod中的容器。
-
可扩展性:Pod可以通过水平扩展来增加计算资源,从而提高应用程序的性能和可用性。当需要增加计算资源时,只需要创建更多的Pod即可。
-
轻量级:Pod比虚拟机更轻量级,因为它们不需要完整的操作系统和内核支持。这意味着Pod可以在更少的硬件资源上运行,从而降低了成本和复杂度。
-
可移植性:Pod可以在不同的节点上运行,从而提高了应用程序的可用性和容错性。如果一个节点出现故障,Kubernetes会自动将Pod迁移到其他节点上运行。
Pod的生命周期包括创建、启动、停止和删除等操作。当用户提交应用程序时,Kubernetes会根据应用程序的要求创建一个新的Pod,并将其调度到合适的节点上运行。当应用程序需要更新或者扩容时,Kubernetes会自动调整Pod的数量和配置,以满足应用程序的需求。
Service的理解
Service是Kubernetes中最常用的抽象概念之一,它定义了一个逻辑集合,其中包含了一组Pod。Service提供了一个稳定的IP地址和DNS名称,使得应用程序可以通过这个地址来访问Pod,而不需要关心Pod的具体位置和网络配置。
Service的主要特点包括:
-
负载均衡:Service可以将请求分发到多个Pod上,从而实现负载均衡。当有多个Pod运行相同的应用程序时,Service可以自动将请求分发到不同的Pod上,从而提高应用程序的可用性和性能。
-
高可用性:Service可以提供高可用性,因为它可以在集群中自动检测Pod的状态变化,并将请求路由到健康的Pod上。如果一个Pod出现故障或者不可用,Kubernetes会自动将请求路由到其他健康的Pod上,从而保证了服务的可用性。
-
灵活性:Service可以根据应用程序的需求进行配置,例如可以选择使用负载均衡算法、设置超时时间等。这使得Service非常灵活,可以根据应用程序的需求进行定制化。
-
可扩展性:Service可以通过水平扩展来增加计算资源,从而提高应用程序的性能和可用性。当需要增加计算资源时,只需要创建更多的Service即可。
Service的生命周期包括创建、更新和删除等操作。当用户提交应用程序时,Kubernetes会根据应用程序的要求创建一个新的Service,并将其绑定到对应的Pod上。当应用程序需要更新或者扩容时,Kubernetes会自动调整Service的数量和配置,以满足应用程序的需求。
Volume 的理解
Volume是Kubernetes中的一种抽象概念,它用于管理存储资源。在Kubernetes中,Volume可以分为多种类型,例如Persistent Volume(PV)、Persistent Volume Claim(PVC)和EmptyDir等。
- Persistent Volume(PV)是一种持久化的存储资源,它可以在集群中被多个Pod共享。当一个Pod需要使用存储资源时,它可以通过PVC来请求PV。一旦PVC被创建,Kubernetes会自动创建一个PV,并将其挂载到Pod上。PV通常由管理员手动创建和管理,但也可以使用动态存储卷(Dynamic Provisioning)功能来自动创建和管理PV。
- Persistent Volume Claim(PVC)是一种请求存储资源的抽象概念,它允许用户向集群中的PV发出请求。当一个Pod需要使用存储资源时,它可以通过PVC来请求PV。一旦PVC被创建,Kubernetes会自动创建一个PV,并将其挂载到Pod上。PVC通常由用户手动创建和管理,但也可以使用动态存储卷(Dynamic Provisioning)功能来自动创建和管理PVC。
- EmptyDir是一种临时性的存储资源,它可以在Pod之间共享。当一个Pod需要使用存储资源时,它可以通过EmptyDir来请求存储资源。一旦请求被接受,Kubernetes会自动创建一个EmptyDir实例,并将其挂载到Pod上。EmptyDir通常用于短暂的存储需求,例如缓存数据或者临时文件等。
Namespace的理解
Namespace是Kubernetes中的一种抽象概念,它用于将集群中的资源隔离开来。在Kubernetes中,每个Namespace都拥有自己的一组资源,例如Pod、Service、ConfigMap等。这些资源只能在所属的Namespace中被访问和操作,而不能跨Namespace进行访问和操作。
Namespace的主要特点包括:
-
隔离性:Namespace可以将集群中的资源隔离开来,使得不同的应用程序可以在同一集群中运行,而不会相互干扰。这有助于提高集群的安全性和管理效率。
-
可扩展性:Namespace可以方便地进行扩展和收缩,从而满足不同应用程序的需求。当需要增加计算资源时,只需要创建更多的Namespace即可;当不需要更多的计算资源时,只需要删除多余的Namespace即可。
-
灵活性:Namespace可以根据应用程序的需求进行配置,例如可以选择使用不同的命名规则、设置标签等。这使得Namespace非常灵活,可以根据应用程序的需求进行定制化。
-
可重用性:Namespace可以被多个应用程序共享,从而提高了资源的利用率和可重用性。当一个应用程序需要使用相同的资源时,它可以通过共享同一个Namespace来实现。
在实际应用中,Namespace通常用于以下场景:
-
多租户环境:在多租户环境中,不同的租户可能需要使用相同的资源,但是又需要保持隔离。这时可以使用Namespace来实现资源的隔离和共享。
-
微服务架构:在微服务架构中,不同的服务可能需要使用相同的资源,但是又需要保持隔离。这时可以使用Namespace来实现资源的隔离和共享。
-
容器编排:在容器编排中,不同的容器可能需要使用相同的资源,但是又需要保持隔离。这时可以使用Namespace来实现资源的隔离和共享。
其他抽象
ReplicaSet的理解
ReplicaSet是Kubernetes中的一种控制器,它用于确保指定数量的Pod副本在集群中运行。ReplicaSet提供了自动扩展和收缩、高可用性、可配置性和可重用性等特点,是Kubernetes中最基本和最重要的控制器之一。在实际应用中,ReplicaSet通常用于确保应用程序的高可用性和可靠性,例如Web服务器、数据库服务器等。
当一个Pod被创建时,ReplicaSet会自动创建一个或多个Pod副本,并监控它们的状态。如果有任何一个Pod副本失败或者不可用,ReplicaSet会自动重启该Pod副本,以确保指定数量的Pod副本始终处于运行状态。
ReplicaSet的主要特点包括:
-
自动扩展和收缩:ReplicaSet可以根据需要自动扩展或收缩Pod副本的数量,从而满足应用程序的需求。当需要增加计算资源时,只需要创建更多的ReplicaSet即可;当不需要更多的计算资源时,只需要删除多余的ReplicaSet即可。
-
高可用性:ReplicaSet可以确保指定数量的Pod副本始终处于运行状态,从而提高了应用程序的可用性和可靠性。如果有任何一个Pod副本失败或者不可用,ReplicaSet会自动重启该Pod副本,从而保证了服务的可用性。
-
可配置性:ReplicaSet可以根据应用程序的需求进行配置,例如可以选择使用不同的标签、选择不同的调度器等。这使得ReplicaSet非常灵活,可以根据应用程序的需求进行定制化。
-
可重用性:ReplicaSet可以被多个Pod共享,从而提高了资源的利用率和可重用性。当一个Pod需要使用相同的资源时,它可以通过共享同一个ReplicaSet来实现。
🎉 如果喜欢这篇文章,点赞👍 收藏⭐ 关注 ✅ 哦,创作不易,感谢!😀