文章目录
BACKUP数据备份案例和注意事项
一、BACKUP数据备份案例
1、Doris中创建数据库,以及建表插入数据
2、创建远端仓库
3、全量备份指定 Doris 库下所有表所有分区数据
4、查看 backup 作业执行情况
5、查看远端仓库中已备份结果
二、注意事项
BACKUP数据备份案例和注意事项
一、BACKUP数据备份案例
1、Doris中创建数据库,以及建表插入数据
#Doris创建数据库mydb
mysql> create database mydb;
#使用当前数据库
mysql> use mydb;
#创建两张表tbl1和tbl2,并插入数据
CREATE TABLE IF NOT EXISTS mydb.tbl1
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入时间,精确到秒",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p1` VALUES [("2017-10-01"),("2017-10-02")),
PARTITION `p2` VALUES [("2017-10-02"),("2017-10-03")),
PARTITION `p3` VALUES [("2017-10-03"),("2017-10-04"))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
insert into mydb.tbl1 values
(10000,"2017-10-01","2017-10-01 08:00:05","北京",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","2017-10-01 09:00:05","北京",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","2017-10-01 18:12:10","北京",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","2017-10-02 13:10:00","上海",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","2017-10-02 13:15:00","广州",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","2017-10-01 12:12:48","深圳",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","2017-10-03 12:38:20","深圳",35,0,"2017-10-03 10:20:22",11,6,6);
CREATE TABLE IF NOT EXISTS mydb.tbl2
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入时间,精确到秒",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p1` VALUES [("2017-10-01"),("2017-10-02")),
PARTITION `p2` VALUES [("2017-10-02"),("2017-10-03")),
PARTITION `p3` VALUES [("2017-10-03"),("2017-10-04"))
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
insert into mydb.tbl2 values
(10000,"2017-10-01","2017-10-01 08:00:05","北京",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","2017-10-01 09:00:05","北京",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","2017-10-01 18:12:10","北京",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","2017-10-02 13:10:00","上海",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","2017-10-02 13:15:00","广州",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","2017-10-01 12:12:48","深圳",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","2017-10-03 12:38:20","深圳",35,0,"2017-10-03 10:20:22",11,6,6);
2、创建远端仓库
CREATE REPOSITORY `hdfs_mydb_repo`
WITH BROKER `broker_name`
ON LOCATION "hdfs://mycluster/backup_mydb/"
PROPERTIES
(
"username" = "root",
"dfs.nameservices"="mycluster",
"dfs.ha.namenodes.mycluster"="node1,node2",
"dfs.namenode.rpc-address.mycluster.node1"="node1:8020",
"dfs.namenode.rpc-address.mycluster.node2"="node2:8020",
"dfs.client.failover.proxy.provider.mycluster" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
3、全量备份指定 Doris 库下所有表所有分区数据
BACKUP SNAPSHOT mydb.snapshot_label1
TO hdfs_mydb_repo
ON (tbl1,tbl2)
PROPERTIES ("type" = "full");
4、查看 backup 作业执行情况
可以通过Show BACKUP 命令来查看最近执行的backup语句:
mysql> show BACKUP\G;
*************************** 1. row ***************************
JobId: 46611
SnapshotName: snapshot_label1
DbName: mydb
State: FINISHED
BackupObjs: [default_cluster:mydb.tbl1], [default_cluster:mydb.tbl2]
CreateTime: 2023-06-30 20:29:25
SnapshotFinishedTime: 2023-06-30 20:29:29
UploadFinishedTime: 2023-06-30 20:29:38
FinishedTime: 2023-06-30 20:29:45
UnfinishedTasks:
Progress:
TaskErrMsg:
Status: [OK]
Timeout: 86400
1 row in set (0.01 sec)
5、查看远端仓库中已备份结果
mysql> SHOW SNAPSHOT ON hdfs_mydb_repo WHERE SNAPSHOT = "snapshot_label1";
+-----------------+---------------------+--------+
| Snapshot | Timestamp | Status |
+-----------------+---------------------+--------+
| snapshot_label1 | 2023-06-30-20-29-25 | OK |
+-----------------+---------------------+--------+
以上备份命令完成后,也可以对应的HDFS路径查看到对应的备份数据:
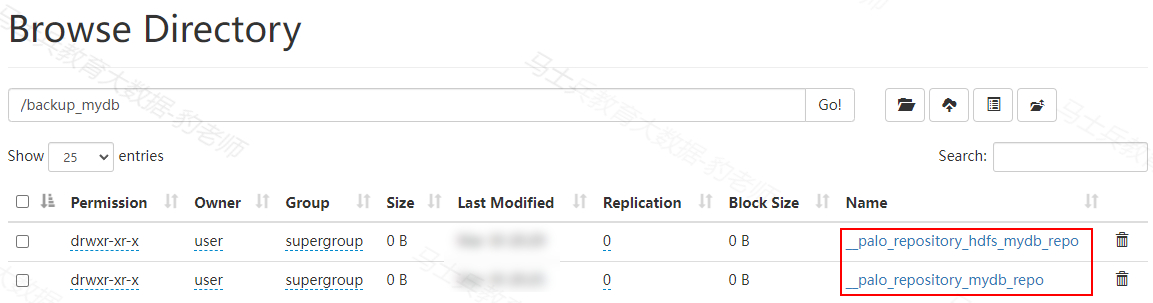
注意:如果想要删除备份,那么只需要删除对应的远端仓库,对应该仓库下的备份映射信息也会被删除,但是备份到远端的数据不会自动删除,需要手动清除。删除远端仓库命令如下:
DROP REPOSITORY hdfs_mydb_repo;二、注意事项
1、关于动态分区表说明
如果表是动态分区表,BACKUP备份之后会自动禁用动态分区属性,在做恢复的时候需要手动将该表的动态分区属性启用,命令如下:
ALTER TABLE tbl1 SET ("dynamic_partition.enable"="true")注意:关于动态分区内容,参照动态分区部分。
2、备份和恢复操作都不会保留表的 colocate_with 属性,colocate_with参考表join部分。
3、备份操作会备份指定表或分区的基础表及 物化视图,并且仅备份一副本。
4、备份操作的效率
备份操作的效率取决于数据量、Compute Node 节点数量以及文件数量。备份数据分片所在的每个 Compute Node 都会参与备份操作的上传阶段。节点数量越多,上传的效率越高。
文件数据量只涉及到的分片数,以及每个分片中文件的数量。如果分片非常多,或者分片内的小文件较多,都可能增加备份操作的时间。
5、备份恢复相关的操作目前只允许拥有 ADMIN 权限的用户执行。
6、一个 Database 内,只允许有一个正在执行的备份或恢复作业。
7、备份和恢复都支持最小分区(Partition)级别的操作,当表的数据量很大时,建议按分区分别执行,以降低失败重试的代价。
8、因为备份恢复操作,操作的都是实际的数据文件。所以当一个表的分片过多,或者一个分片有过多的小版本时,可能即使总数据量很小,依然需要备份或恢复很长时间。用户可以通过 SHOW PARTITIONS FROM table_name; 和 SHOW TABLETS FROM table_name; 来查看各个分区的分片数量,以及各个分片的文件版本数量,来预估作业执行时间。文件数量对作业执行的时间影响非常大,所以建议在建表时,合理规划分区分桶,以避免过多的分片。
9、当通过 SHOW BACKUP 或者 SHOW RESTORE 命令查看作业状态时。有可能会在 TaskErrMsg 一列中看到错误信息。但只要 State 列不为 CANCELLED,则说明作业依然在继续。这些 Task 有可能会重试成功。当然,有些 Task 错误,也会直接导致作业失败。
10、关于BACKUP 相关命令参照官网:
https://doris.apache.org/zh-CN/docs/dev/admin-manual/data-admin/backup/
通过官网链接查看相关命令
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨

![[探地雷达]利用Faster RCNN对B-SCAN探地雷达数据进行目标检测](https://img-blog.csdnimg.cn/491979c290f04b53b67f55132951093d.png)