深度学习是一种强大的机器学习方法,它在各个领域都有广泛应用。如果你是一个新手,想要入门深度学习,下面是一些步骤和资源,可以帮助你开始学习和实践深度学习。
1. 学习基本概念
在开始深度学习之前,你需要对一些基本概念有所了解。以下是一些你需要学习的重要概念:
- 神经网络: 它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。神经网络是一种运算模型,由大量神经元之间相互联接构成。学习如何构建和训练神经网络是入门的重要一步。
- 神经元: 神经元模型是一个包含输入,输出与计算功能的模型。
- 前向传播和反向传播: 它是神经网络的基本运行方式,前向传播用于计算输出,反向传播用于更新网络参数。
- 激活函数: 激活函数决定神经元的输出。学习不同的激活函数以及它们的作用。
- 损失函数: 损失函数用于衡量模型的预测与实际结果之间的差异。了解不同的损失函数和它们的适用场景。
- 优化算法: 优化算法用于更新神经网络的参数以最小化损失函数。了解常用的优化算法,如随机梯度下降法(SGD)和Adam。
2. 学习编程和数学基础
深度学习需要一些编程和数学基础。以下是你应该学习的基本内容:
- 编程语言: Python 是深度学习的主要编程语言。学习 Python 的基本语法和常用库,如 NumPy、Pandas与Matplotlib。
- 线性代数: 深度学习中使用矩阵和向量进行计算,因此了解线性代数的基本概念是必要的,但是要求不高,一般本科及以上理工科学生已具备基础。
- 概率与统计: 深度学习中的一些概念和技术涉及概率和统计。了解基本的概率和统计概念将有助于你理解深度学习模型的工作原理。要求也不高,一般本科及以上理工科学生已具备基础。
3. 学习深度学习框架
深度学习框架可以帮助你更轻松地构建、训练和部署深度学习模型。以下是一些常见的深度学习框架:
- TensorFlow2:由 Google 开发的开源框架,简单,模块封装比较好,容易上手,对新手比较友好。在工业界最重要的是模型落地,目前国内的大部分企业支持TensorFlow模型在线部署,不支持Pytorch。
- PyTorch:由 Facebook 开发的开源框架,前沿算法多为PyTorch版本,如果是你高校学生or研究人员,建议学这个。相对于TensorFlow,Pytorch在易用性上更有优势,更加方便调试。
选择一个深度学习框架并学习其基本用法和特性。框架的官方文档和在线教程是学习的好资源。
4. 学习经典模型和案例
学习一些经典的深度学习模型和案例将帮助你更好地理解深度学习的应用和工作原理。以下是一些你可以开始学习的模型和案例:
-
卷积神经网络(Convolutional Neural Networks,CNN):常用于图像识别和计算机视觉任务的常用模型,是一种专门用来处理具有类似网格结构的数据的神经网络。卷积网络在图像识别,自然语言处理,灾难性气候预测、围棋人工智能等诸多应用领域都表现优异。卷积神经网络通常由3个部分构成:
卷积层,池化层,全连接层。简单来说,卷积层负责提取图像中的局部及全局特征;池化层用来大幅降低参数量级(降维);全连接层用于处理“压缩的图像信息”并输出结果。 -
循环神经网络(Recurrent Neural Networks,RNN):用于序列数据建模和自然语言处理任务的常用模型,传统神经网络的结构比较简单,通常为:输入层 – 隐藏层 – 输出层。
-
生成对抗网络(Generative Adversarial Networks,GAN):用于生成新的数据样本的模型。是近年来深度学习领域的一个热点方向。GAN并不指代某一个具体的神经网络,而是指一类基于博弈思想而设计的神经网络。GAN由两个分别被称为生成器(Generator)和判别器(Discriminator)的神经网络组成。其中,生成器从某种噪声分布中随机采样作为输入,输出与训练集中真实样本非常相似的人工样本;判别器的输入则为真实样本或人工样本,其目的是将人工样本与真实样本尽可能地区分出来。生成器和判别器交替运行,相互博弈,各自的能力都得到升。理想情况下,经过足够次数的博弈之后,判别器无法判断给定样本的真实性,即对于所有样本都输出50%真,50%假的判断。此时,生成器输出的人工样本已经逼真到使判别器无法分辨真假,停止博弈。这样就可以得到一个具有“伪造”真实样本能力的生成器。
-
Transformer:用于自然语言处理任务,如机器翻译和文本生成。Transformer模型在2017年被google提出,直接基于 Self-Attention 结构,取代了之前NLP任务中常用的RNN神经网络结构,并在WMT2014 Englishto-German和WMT2014 English-to-French两个机器翻译任务上都取得了当时的SOTA。与RNN这类神经网络结构相比,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。与seq2seq模型类似,Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder)。
学习这些模型的基本原理和实现方法,并尝试在实际问题中应用它们。
下面将通过深度学习在 MNIST 手写数字的识别上的应用带大家入门深度学习
一、深度学习是什么
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。–引自百度百科
深度学习(deep learning)是机器学习的分支,是一种以人工神经网络为架构,对资料进行表征学习的算法。–引自维基百科
“深度学习”这四个字拆解成两个词就是“深度”和“学习”。“学习”大概是我们学生时代接触最频繁的词,那时候的学习就是上课、做题,最终通过考试。如果更抽象一点描述,学习就是认知的过程,从未知到已知的探索与思考过程。最早的学习,1+1=2,想想我们是怎么学习的?伸出一只手指,再伸出一只手指,数一数,两只手指那就是2。

这里定义一个概念,输入和输出,输入就是已知的信息,输出就是由输入获得的认知的结果。我们将一个从已有的信息,通过计算、判断和推理得到结果的认知过程统称为“学习”。

如何让机器也可以进行学习呢?学术界为此提出了“神经网络”的概念。人脑中负责活动的基本单元是神经元,这些神经元互相连接成一个被称为神经网络的庞大结构。由此,学术界模仿人脑“神经网络“建立一个人工神经网络(ANN),我们通常也简称为神经网络。
将1+1=2用神经网络可以表示为如下结构。
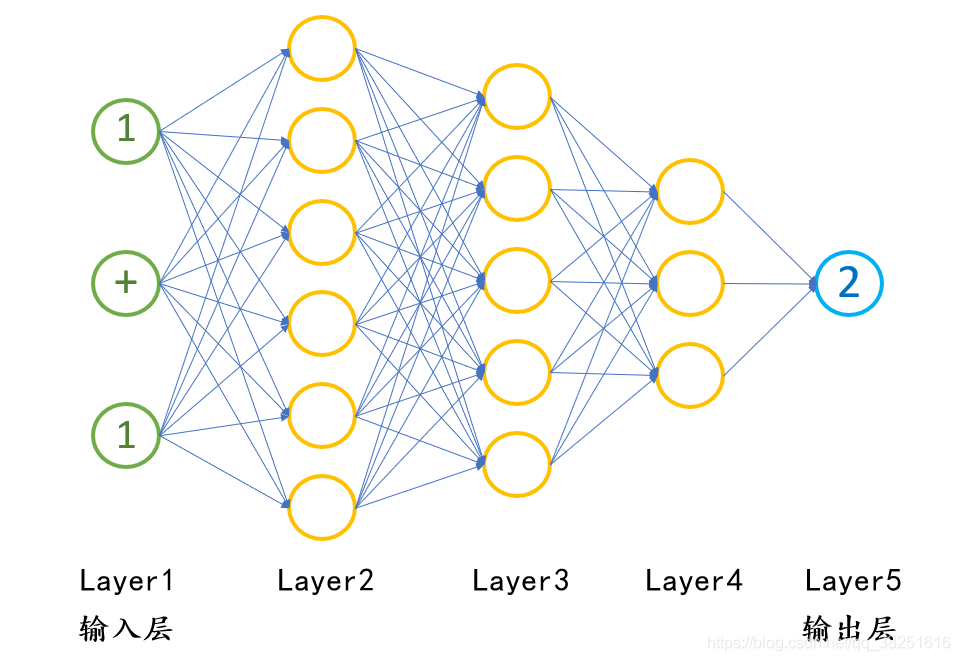
我们将“1”、“+”、“1”与“2”同时作为输入不断训练神经网络(不断告诉机器1+1=2),在训练若干次后,神经网络将会学会“1+1=2”。同样的,我们将1+2=3放入神经网络中去,不断进行训练,若干次后神经网络也将学会1+2=3。如此循环往复,我们可以教会神经网络进行加法运算,进而可以让神经网络学会算术运算,我们把这个过程称为深度学习。
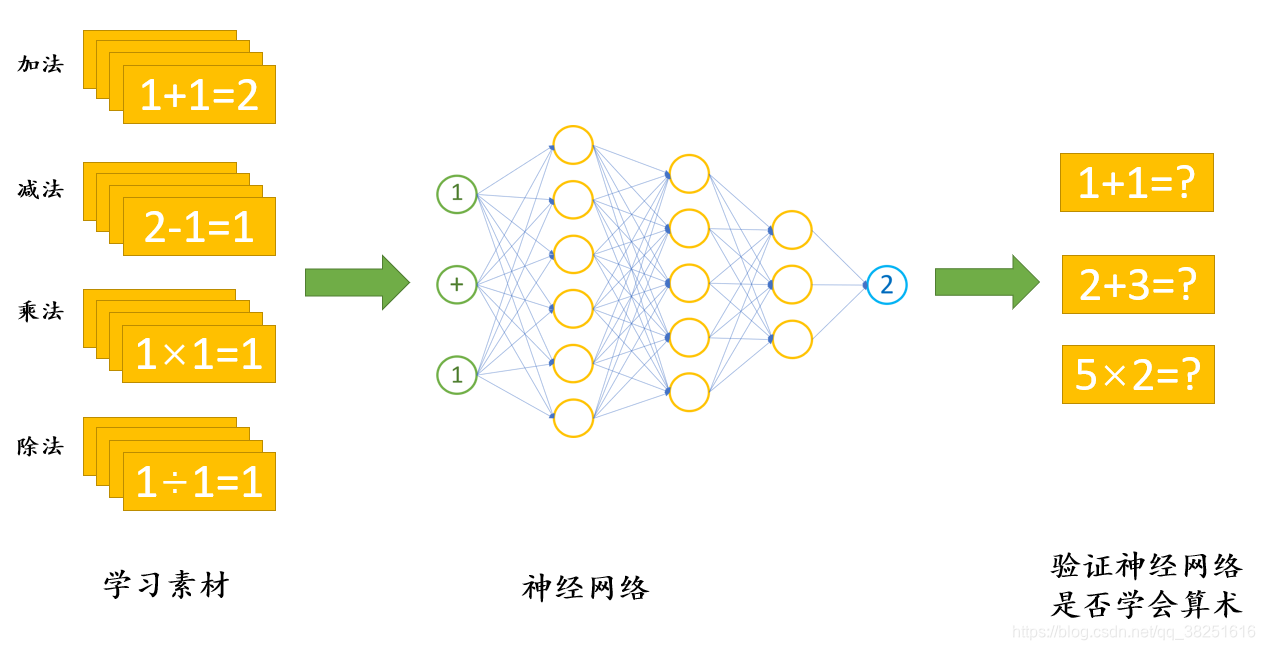
深度学习在生活中的应用不仅仅局限于此,在自动驾驶、语音识别、自动机器翻译、即时视觉翻译(拍照翻译)、目标识别等等领域也都有重要应用,例如:手机上的小爱同学、地铁口的人脸识别…
下面我将通过对 MNIST 手写数字的识别进一步讲解深度学习,带领大家体验一次完整的深度学习实现的全过程。
假设现在我们手上很多张手写的数字图片,需要通过深度学习让机器“认识”这些图片上的数字,然后告诉我们每一张图片上的数字是多少。
那么我们应该如何实现呢?总体的思路如下:
- 我们先拿出 6 万张图片给机器进行学习(需要告诉机器每一个图片上写的是哪一个数字)。
- 在学习后,再拿出1万张机器没“见过”的图片给它进行识别,让它告诉我们,图片上写的是哪一个数字。
- 重复上面的过程,直到机器可以认识手写的数字。
至此,完成便可实现手写数字识别这一效果。
二、实现过程
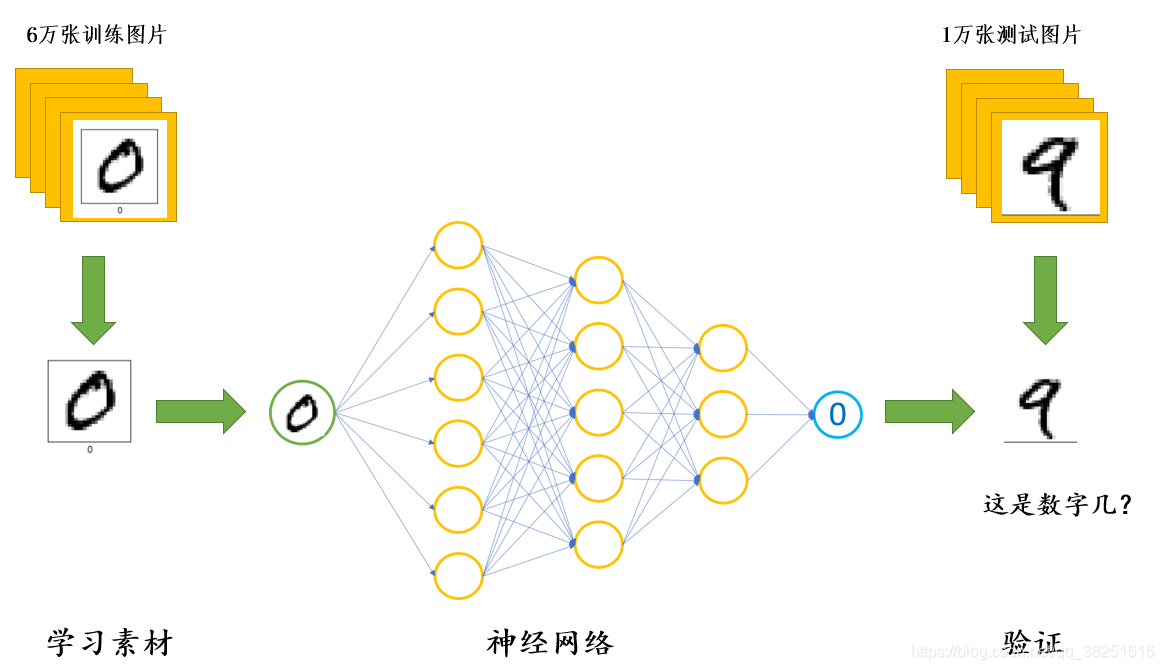
程序执行步骤:
- ① 学习6万张图片上的数字
- ② 用1万张图片测试机器的学习效果(这1万张不参与①的训练)
- ③ 重复①、②
使用的编译器为Jupyter Notebook,如果你不太熟,可以先看看前面的文章:【小白入门深度学习 | 第二篇:编译器的使用-Jupyter Notebook】
如果你对下面的代码不是很理解,没有关系的,后面的文章中我会对每个部分展开更详细的解释。现在你需要做的是:了解每一个模块实现的功能,从整体上把握整份代码。
🏡 我的环境:
- 语言环境:Python3.10.11
- 编译器:Jupyter Notebook
- 深度学习框架:TensorFlow 2.4.1
- 显卡(GPU):NVIDIA GeForce RTX 4070
🥂 相关教程:
- 深度学习环境配置教程:【新手入门深度学习 | 1-1:配置深度学习环境】
- 一个深度学习小白需要的所有资料我都放这里了:【新手入门深度学习 | 目录】
建议你学习本文之前先看看下面这篇入门文章,以便你可以更好的理解本文:🍨 新手入门深度学习 | 2-1:图像数据建模流程示例
强烈建议大家使用Jupyter Notebook编译器打开源码,你接下来的操作将会非常便捷的!
- 如果你是一名深度学习小白可以先看看我这个专门为你写的专栏: 📖《新手入门深度学习》
- 如果你有一定基础,但是
缺乏实战经验,可通过 📖《深度学习100例》 补齐基础 - 另外,我们正在通过 🔥365天深度学习训练营🔥 抱团学习,营内为大家提供系统的学习教案与专业的指导、非常良好的学习氛围,欢迎你的加入
1. 准备数据
导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 输出数据形状
train_images.shape, test_images.shape
((60000, 28, 28), (10000, 28, 28))
准备好 6 万张带有标签的训练图片让机器进行学习。1 万张测试图片让机器进行识别,测试其是否学会了。(60000, 28, 28) 表示为:60000 张 28*28 像素的图片。
可视化
这里我们用第三方库 matplotlib 输出手写数字图片,看看我们的手写数字(数据集)是什么样子的。
import matplotlib.pyplot as plt
# 设置窗口大小为 20*12 单位英寸
plt.figure(figsize=(20,12))
for i in range(20):
# 设置子图行数为5,列数为10,i+1表示第几个子图
plt.subplot(5,10,i+1)
# 去掉坐标轴刻度
plt.xticks([])
plt.yticks([])
# 显示图片
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 显示标签
plt.xlabel(train_labels[i])
plt.show()

调整图片格式
需要将图片调整为特定格式程序才可以进行学习
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# 输出数据sahpe
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
(60000, 28, 28, 1):表示为:60000张 28*28 的灰度图片,最后一个数字为1时,代表灰度图片;为3时代表彩色图片。
2. 构建神经网络模型
我们将图片输入到网络,图片首先会将其数字化,紧接着通过卷积层提取图片上这个数字的特征,最后通过数字的特征判断这个数字是哪一个。结构图如下:
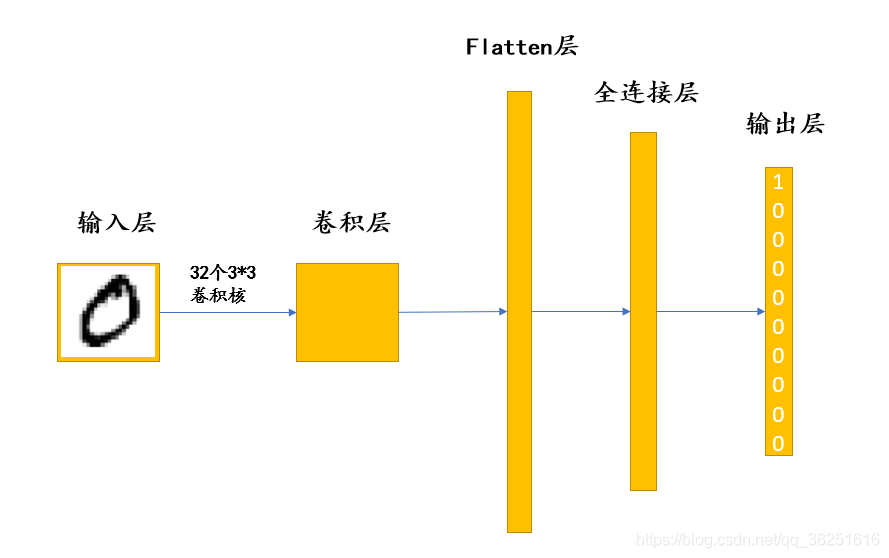
上面的结构图中,向我们展示了五层结构,那么每一层具体是用来做什么的呢?
- 输入层:用于将数据输入到神经网络
- 卷积层:使用卷积核提取图片特征,卷积核相当于一个小型的“特征提取器”
- Flatten层:将多维的输入一维化,常用在卷积层到全连接层的过渡
- 全连接层:起到“特征提取器”的作用
- 输出层:输出结果
卷积核与全连接层从某些方面上讲都有提取特征的作用,但是所采用的方法是不同的。
这部分为深度学习的核心内容,我将在第四部分(构建模型)重点向大家进行更详细深入的讲解,现在我们主要任务是跑通整个程序,从整体上了解一下深度学习是什么。
model = models.Sequential([ #
layers.Conv2D(32, (3, 3), input_shape=(28, 28, 1)), # 卷积层:提取图片特征
layers.Flatten(), # Flatten层:将二维图片压缩为一维形式
layers.Dense(100), # 全连接层:将特征进行进一步压缩
layers.Dense(10) # 输出层:输出结果
])
# 打印网络结构
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
flatten (Flatten) (None, 21632) 0
_________________________________________________________________
dense (Dense) (None, 100) 2163300
_________________________________________________________________
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 2,164,630
Trainable params: 2,164,630
Non-trainable params: 0
_________________________________________________________________
3. 编译模型
在这一步,我们需要设置模型的优化器,损失函数、评价函数:
- 优化器:帮助模型更好的训练
- 损失函数:用于估量预测值与真实值的不一致程度
- 评价函数:评价模型的质量
model.compile(optimizer='adam', # adam是优化器的一种
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 损失函数的一种计算方法
metrics=['accuracy']) #采用准确率来评价模型
4. 训练模型
将数据传入模型进行训练,传入的数据分为训练数据、验证数据两部分。训练数据(训练集)用于训练模型,验证数据(验证集)用于监测模型的效果。epochs 表示模型的学习轮数(次数)。
"""
train_images :训练数据的图片
train_labels :训练图片对应的标签
epochs :训练轮数
validation_data:验证数据
"""
history = model.fit(train_images, train_labels, epochs=3,
validation_data=(test_images, test_labels))
Epoch 1/3
1875/1875 [==============================] - 39s 20ms/step - loss: 32.1691 - accuracy: 0.8110 - val_loss: 1.1053 - val_accuracy: 0.8700
Epoch 2/3
1875/1875 [==============================] - 42s 22ms/step - loss: 0.8161 - accuracy: 0.8832 - val_loss: 0.5099 - val_accuracy: 0.8955
Epoch 3/3
1875/1875 [==============================] - 36s 19ms/step - loss: 0.4562 - accuracy: 0.8920 - val_loss: 0.4225 - val_accuracy: 0.8843
5. 预测
# 打印我们想要进行预测的图片
plt.imshow(test_images[1])
<matplotlib.image.AxesImage at 0x14695a3cfd0>

输出测试集中第一张图片的预测数组
pre = model.predict(test_images)
pre[1]
array([ 12.474585 , 1.1173537, 21.654232 , 16.206923 , -10.989567 ,
17.235504 , 19.404213 , -22.553476 , 13.221286 , -10.19972 ],
dtype=float32)
这组浮点数对应着0~9,最大的浮点数对应着的数字就是神经网络的预测结果。
import numpy as np
# 输出预测结果
pre_num = np.argmax(pre[1])
print("模型的预测结果为:",pre_num)
模型的预测结果为: 2
三、总结
我们通过算术学习、MNIST手写数字识别了解了什么是深度学习,也用TensorFlow2实现了MNIST手写数字识别,从整体上了解了一个深度学习程序是什么样子的,应该有哪些步骤