文章目录
- 概要
- 一、安装
- 二、配置
- 2.1、 通用配置
- 2.2、 分片配置
- 2.3、读写分离
- 三、演练
- 3.1、读写分离
- 3.2、分库分表
- 3.3、分库分表+读写分离
- 4、总结
概要
市面上MySQL分库分表中间件还是很多的,主要分为两大类:应用层依赖类中间件(比如shardingsphere-jdbc)、中间层代理类中间件(比如shardingsphere-proxy)。
- 应用层依赖类中间件
即中间件在数据库连接库基础之上,增加了一层封装。我们使用时,以shardingsphere-jdbc为例,需要先引入一个jar包。中间件接收持久层产生的sql,同样对sql进行分析等操作,然后才落实到具体的库上。
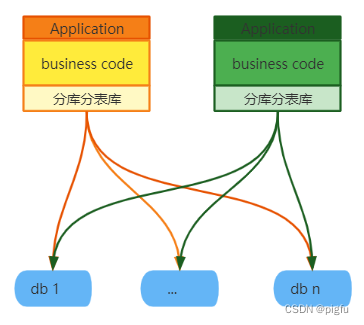
优点:性能损耗低(直连数据库),去中心化(每个Application使用各自的分库分表库)。
缺点:异构语言不是很友好,连接数高(每个Application都要与数据库建立连接)。 - 中间层代理类中间件
即把中间件作为一个独立的服务,它将接收到的SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
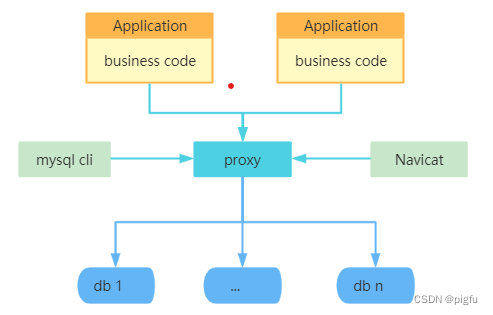
优点:异构语言友好,连接数低(只需proxy与数据库建立连接)。
优点:性能损耗略高(需要proxy转发去连数据库),中心化(proxy需要集群部署,运维难度增加)。
市面上常见的分库分表中间件很多,但是国内主要是mycat和shardingsphere,相较而言,shardingsphere已经是Apache顶级项目,维护稳定,功能齐全,支持云原生,更值得学习。
在上一篇分享了MySQL分库分表的一些理论知识,本文主要是分享shardingsphere的实战内容。
官方文档
本文基于 shardingsphere V5.3.1探索
一、安装
根据官方文档提示,主要有两种方式:二进制安装和docker安装;
本人是使用docker的方式,如下:
- 拉取镜像
docker pull apache/shardingsphere-proxy
- 拷贝配置
起一个临时容器 tmp,把配置模板从tmp中拷贝到本地目录下,然后删除tmp。
mkdir -p /etc/shardingsphere-proxy/conf
docker run -d --name tmp --entrypoint=bash apache/shardingsphere-proxy
docker cp tmp:/opt/shardingsphere-proxy/conf /etc/shardingsphere-proxy/conf
docker rm tmp
- 引入依赖
下载连接mysql的jar包,本人mysql版本是V5.6.28,所以选的jar包版本是V5.1.49
mkdir -p /etc/shardingsphere-proxy/ext-lib
下载jar包后放入到 /etc/shardingsphere-proxy/ext-lib 目录下
- 启动容器
docker run -d \
-v /etc/shardingsphere-proxy/conf:/opt/shardingsphere-proxy/conf \
-v /etc/shardingsphere-proxy/ext-lib:/opt/shardingsphere-proxy/ext-lib \
-e PORT=3305 -p 3305:3305 apache/shardingsphere-proxy:latest
如此shardingsphere-proxy容器就起来了,但是配置文件还没调整,放在下一章讲解。
二、配置
我们ll /etc/shardingsphere-proxy/conf/ 可以看到所有的配置文件,如下:
- config-database-discovery.yaml #高可用。健康检查,db节点没有心跳就不会再转发sql到该节点,保证高可用
- config-encrypt.yaml #数据加密
- config-mask.yaml #数据脱敏
- config-readwrite-splitting.yaml #读写分离
- config-shadow.yaml #影子库配置
- config-sharding.yaml #分片配置(分库分表规则)
- server.yaml #通用配置
2.1、 通用配置
官方文档-模式类型
官方文档-认证和授权
官方文档-属性配置
官方文档-其他配置
######################################################################################################
# If you want to configure governance, authorization and proxy properties, please refer to this file.
######################################################################################################
mode:
type: Standalone #运行模式类型。可选配置:Standalone、Cluster,个人测试就选择了单机模式
repository: # 持久化仓库配置
type: JDBC #持久化仓库类型
props: # 持久化仓库所需属性
foo_key: foo_value
bar_key: bar_value
authority: #认证和授权
users: #账号信息
- user: root
password: root
- user: sharding
password: sharding
privilege: #权限
type: ALL_PERMITTED
props: #属性配置
max-connections-size-per-query: 1
kernel-executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
proxy-hint-enabled: true
sql-show: true
check-table-metadata-enabled: false
#其他配置
transaction: #分布式事务
defaultType: XA
providerType: Atomikos
sqlParser: #SQL 解析
sqlCommentParseEnabled: false
sqlStatementCache:
initialCapacity: 2000
maximumSize: 65535
parseTreeCache:
initialCapacity: 128
maximumSize: 1024
2.2、 分片配置
官方文档-数据源配置
官方文档-分片规则
######################################################################################################
# Here you can configure the rules for the proxy. This example is configuration of sharding rule.
######################################################################################################
#数据源配置
databaseName: order #数据源配置(即对外的数据库名称),可配置多个(即分库)
dataSources: #测试就用了一个MySQL实例
ds_0:
url: jdbc:mysql://127.0.0.1:3306/order_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/order_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
minPoolSize: 1
#分片规则(即分表)
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1} #由数据源名 + 表名组成。0..1表示分成两个库or表
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: snowflake
t_order_setting:
actualDataNodes: ds_${0..1}.t_order_setting_${0..1}
tableStrategy:
complex: # 用于多分片键的复合分片场景
shardingColumns: user_id,id
shardingAlgorithmName: t_order_setting_complex_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
#auditStrategy:
#auditorNames:
#- sharding_key_required_auditor
#allowHintDisable: true
#自动分片
autoTables:
t_order_shipping:
actualDataSources: ds_${0..1}
shardingStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: t_order_shipping_mod
#绑定表规则列表
bindingTables:
- t_order,t_order_item
#broadcastTables:
#分库算法
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
#分表算法
defaultTableStrategy:
none:
#defaultAuditStrategy:
# auditorNames:
# - sharding_key_required_auditor
#allowHintDisable: true
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
t_order_setting_complex_inline:
type: COMPLEX_INLINE
props:
sharding-columns: user_id,id
algorithm-expression: t_order_setting_${(user_id / 2 + id / 2) % 2}
t_order_shipping_mod:
type: MOD
props:
sharding-count: 4 #自动分片数量
# 分布式序列算法配置
keyGenerators:
snowflake:
type: SNOWFLAKE
# 分片审计算法配置
auditors:
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
2.3、读写分离
官方文档-读写分离
######################################################################################################
# Here you can configure the rules for the proxy. This example is configuration of readwrite-splitting rule.
######################################################################################################
#数据源配置
databaseName: test_rw_split #数据源配置(即对外的数据库名称),可配置一个主库多个从库,这里只配置了一个从库做测试
dataSources:
ds_write_0:
url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: sangfordb
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
minPoolSize: 1
ds_read_0_0:
url: jdbc:mysql://127.0.0.1:3307/test?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
#读写分离配置
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
staticStrategy:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_read_0_0
loadBalancerName: random
loadBalancers: #从库负载均衡算法,有三种
random:
type: RANDOM #随机
roundRobin:
type: ROUND_ROBIN # 轮询
weight:
type: WEIGHT #权重
props:
ds_read_0_0: 100
三、演练
第二章揭的配置调整好后,就重启容器,然后就可以用mysql cli连shardingspher-proxy实例了。
mysql -h 127.0.0.1 -P 3305 -uroot -p
密码也是 root。
进入后执行show databases:
mysql> show databases;
+--------------------+
| schema_name |
+--------------------+
| information_schema |
| mysql |
| order |
| performance_schema |
| shardingsphere |
| sys |
| test_rw_split |
+--------------------+
7 rows in set (0.01 sec)
可以看到分库分表的库order和读写分离的库test_rw_split 都有了
3.1、读写分离
读写分离测试前首先保证 3306和3307两个MySQL实例 主从复制正常,教程见主从搭建。
3306和3307两个MySQL实例都开启general_log,便于观察是否确实在从节点进行读,在主节点进行写
- 建库
CREATE DATABASE IF NOT EXISTS test DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_general_ci;
- 建表
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(15) NOT NULL,
`pwd` varchar(15) NOT NULL,
`flag` tinyint(3) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ind_flag` (`flag`)
) ENGINE=InnoDB AUTO_INCREMENT=32 DEFAULT CHARSET=utf8mb4
- 写:
mysql> insert into test(name,pwd,flag)values("ers","dft",68);
docker logs -f b58cdf57b50d
可以在shardingspher-proxy日志上看到:
[INFO ] 2023-07-02 10:48:07.261 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Logic SQL: insert into test(name,pwd,flag)values(“ers”,“dft”,100)
[INFO ] 2023-07-02 10:48:07.261 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_0 ::: insert into test(name,pwd,flag)values(“ers”,“dft”,100)
可以确实是在主节点执行,观察主从节点general_log也可以确定。
- 读:
mysql> use test_rw_split;
mysql> select * from test where id=31\G;
*************************** 1. row ***************************
id: 31
name: ers
pwd: dft
flag: 68
可以在shardingspher-proxy日志上看到:
[INFO ] 2023-07-02 10:45:20.021 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Logic SQL: select * from test where id=31
[INFO ] 2023-07-02 10:45:20.022 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_read_0_0 ::: select * from test where id=31
可以看到确实是在从节点执行,观察主从节点general_log也可以确定。
目前支持一主多从的架构,不支持多主多从的架构
3.2、分库分表
- 建库
CREATE DATABASE IF NOT EXISTS order DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_general_ci;
- 建表
CREATE TABLE `t_order` (
`id` bigint(20) NOT NULL,
`order_no` varchar(30) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`amount` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_order_item` (
`id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
`product_id` bigint(20) DEFAULT NULL,
`num` int(11) DEFAULT NULL comment '商品数量',
`price` decimal(10,2) DEFAULT NULL comment '商品单价',
`amount` decimal(10,2) DEFAULT NULL comment '商品总价',
PRIMARY KEY (`id`),
KEY `order_id` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_order_shipping` (
`id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
`from_addr` varchar(120) DEFAULT NULL comment '出发地',
`to_addr` varchar(120) DEFAULT NULL comment '目的地',
PRIMARY KEY (`id`),
KEY `order_id` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_order_setting` (
`id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
`down_order` tinyint DEFAULT NULL comment '开启订单下载权限',
PRIMARY KEY (`id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 结果
以建表t_order为例,到3306 MySQL实例上查看可得到:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| order_0 |
| order_1 |
| performance_schema |
| test |
+--------------------+
mysql> use order_0;
Database changed
mysql> show tables;
+-------------------+
| Tables_in_order_0 |
+-------------------+
| t_order_0 |
| t_order_1 |
| t_order_item_0 |
| t_order_item_1 |
+-------------------+
可以看到建库建表都按照预设的分库分表规则自动在分片库上创建了;
- 写
INSERT INTO `order`.`t_order`(`order_no`, `user_id`, `amount`) VALUES ('OID20230702001', 179468213359476736,22.01);
docker logs -f b58cdf57b50d
可以在shardingspher-proxy日志上看到:
[INFO ] 2023-07-02 10:14:36.788 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Logic SQL: INSERT INTO
order.t_order(order_no,user_id,amount) VALUES (‘OID20230702001’, 179468213359476736,22.01)
[INFO ] 2023-07-02 10:14:36.788 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_0 ::: INSERT INTOt_order_0(order_no,user_id,amount, order_id) VALUES (‘OID20230702001’, 179468213359476736, 22.01, 882206737124294656)
我们预设的分库是user_id % 2,分表是order_id % 2,结果完全符合要求,并且order_id按照雪花算法自动生成了
- 读
1)命中分片键
select * from t_order where user_id=179468213359476736 and order_id=779468213359476736\G;
shardingspher-proxy日志:
[INFO ] 2023-07-02 10:21:39.323 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Logic SQL: select * from t_order where user_id=179468213359476736 and order_id=779468213359476736
[INFO ] 2023-07-02 10:21:39.324 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_0 ::: select * from t_order_0 where user_id=179468213359476736 and order_id=779468213359476736
命中分片键 user_id+order_id,只查询了ds_0的t_order_0表。
2)没有命中分片键
select * from t_order where order_no="OID20230702001"\G;
shardingspher-proxy日志:
[INFO ] 2023-07-02 10:25:49.429 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Logic SQL: select * from t_order where order_no=“OID20230702001”
[INFO ] 2023-07-02 10:25:49.430 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_0 ::: select * from t_order_0 where order_no=“OID20230702001” UNION ALL select * from t_order_1 where order_no=“OID20230702001”
[INFO ] 2023-07-02 10:25:49.430 [Connection-2-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_1 ::: select * from t_order_0 where order_no=“OID20230702001” UNION ALL select * from t_order_1 where order_no=“OID20230702001”
没有命中分片键 user_id+order_id,需要到所有的分片查询。
3.3、分库分表+读写分离
官方文档-混合规则
只需将2.2小节和2.3小节的配置合在一起即可,如下:
######################################################################################################
# Here you can configure the rules for the proxy. This example is configuration of sharding rule.
######################################################################################################
#数据源配置
databaseName: order
dataSources:
ds_0:
url: jdbc:mysql://200.200.107.241:3306/order_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: sangfordb
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
minPoolSize: 1
ds_read_0_0:
url: jdbc:mysql://200.200.107.241:3307/order_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://200.200.107.241:3306/order_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: sangfordb
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
minPoolSize: 1
ds_read_1_0:
url: jdbc:mysql://200.200.107.241:3307/order_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_rw_${0..1}.t_order_${0..1} #读写分离
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_rw_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_order_setting:
actualDataNodes: ds_rw_${0..1}.t_order_setting_${0..1}
tableStrategy:
complex:
shardingColumns: user_id,id
shardingAlgorithmName: t_order_setting_complex_inline
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
#auditStrategy:
#auditorNames:
#- sharding_key_required_auditor
#allowHintDisable: true
autoTables:
t_order_shipping:
actualDataSources: ds_rw_${0..1}
shardingStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: t_order_shipping_mod
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
#broadcastTables:
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
#defaultAuditStrategy:
# auditorNames:
# - sharding_key_required_auditor
#allowHintDisable: true
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_rw_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
t_order_setting_complex_inline:
type: COMPLEX_INLINE
props:
sharding-columns: user_id,id
algorithm-expression: t_order_setting_${(user_id / 2 + id / 2) % 2}
t_order_shipping_mod:
type: MOD
props:
sharding-count: 4
keyGenerators:
snowflake:
type: SNOWFLAKE
auditors:
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
- !READWRITE_SPLITTING
dataSources:
ds_rw_0:
staticStrategy:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_read_0_0
loadBalancerName: random
ds_rw_1:
staticStrategy:
writeDataSourceName: ds_1
readDataSourceNames:
- ds_read_1_0
loadBalancerName: random
loadBalancers:
random:
type: RANDOM
- 读
select * from t_order_shipping\G;
shardingspher-proxy日志:
[INFO ] 2023-07-02 11:36:44.740 [Connection-1-ThreadExecutor] ShardingSphere-SQL - Logic SQL: select * from t_order_shipping
[INFO ] 2023-07-02 11:36:44.740 [Connection-1-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_read_0_0 ::: select * from t_order_shipping_0 UNION ALL select * from t_order_shipping_2
[INFO ] 2023-07-02 11:36:44.740 [Connection-1-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_read_1_0 ::: select * from t_order_shipping_1 UNION ALL select * from t_order_shipping_3
可以看到是从两个从节点读取数据的。
- 写
insert into t_order_shipping(id,order_id,from_addr,to_addr)values(882206737124294651,882206737124294656,'北京','南京');
#or
insert into t_order_shipping(order_id,from_addr,to_addr)values(882206737124294656,"北京","南京");
shardingspher-proxy日志:
[INFO ] 2023-07-02 11:53:18.101 [Connection-1-ThreadExecutor] ShardingSphere-SQL - Logic SQL: insert into t_order_shipping(id,order_id,from_addr,to_addr)values(882206737124294651,882206737124294656,“北京”,“南京”)
[INFO ] 2023-07-02 11:53:18.101 [Connection-1-ThreadExecutor] ShardingSphere-SQL - Actual SQL: ds_1 ::: insert into t_order_shipping_3(id,order_id,from_addr,to_addr)values(882206737124294651, 882206737124294656, ‘北京’, ‘南京’)
可以看到是从主节点ds-1写入数据的。
4、总结
官方文档-分片算法
从官方文档可以看到有许多分片算法,主要可以概括为哈希分片和范围分片。
从上一篇我们知道了二者的缺陷,为何没有引入一致性哈希算法?
或者像MongoDB那样先对分片键哈希再按其哈希值进行范围分片呢?