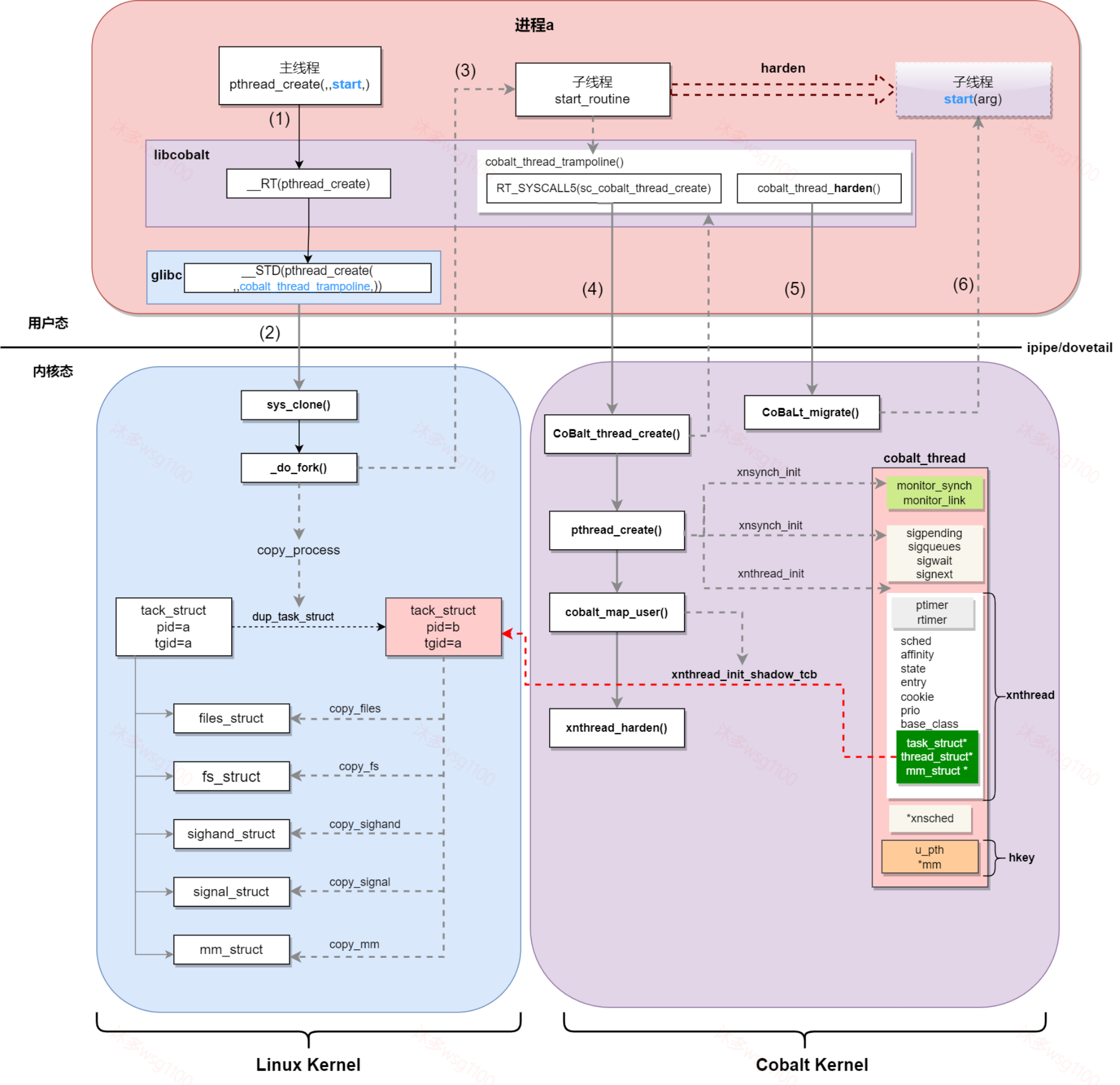
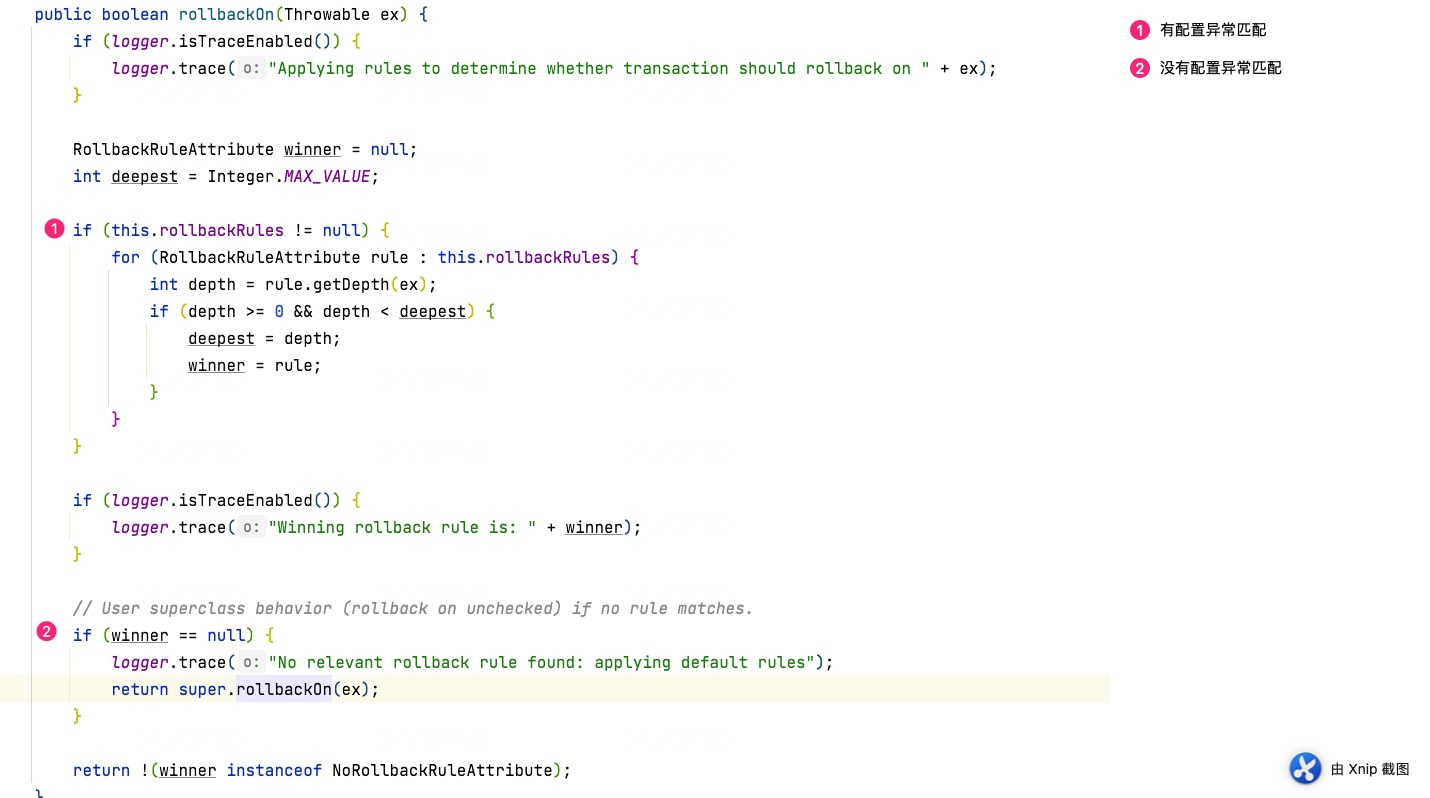
1、Java内存模型JMM (Java Meemory Model)
- JMM规定,所有变量均存储在主内存中
- 每个线程都有自己的工作内存,保存了该线程中用到的变量的主内存副本拷贝
- 线程对变量的所有操作,必须在自己的工作内存中,不可直接读写主内存
- 不同线程无法直接访问对方工作内存中的变量
- 线程间变量的传递,需要自己的工作内存和主内存之间进行数据同步
注:此处的主内存、工作内存,与JVM内存结构中的Java堆、栈、方法区不是同一个层次的内存划分,无法直接对比。若一定要勉强对应起来,那么,主内存主要对应JVM堆中的对象示例数据部分,工作内存主要对应JVM栈中的部分区域。
综上,JMM是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行 等带来的问题。
补充:
- Java提供了一系列和并发处理相关的关键字,如synchronized、volatile、final、concurren包等
其中,Java提供两种内在同步机制:

2、并发编程三个基本属性
- 原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
- 可见性:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
- 有序性:即程序执行的顺序按照代码的先后顺序执行。
补充,锁提供的两种主要特性:

3、synchronized
3.1、代码示例
- 锁方法
public class Test {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
String threadName = "" + (i + 1);
System.out.println("线程序号:" + threadName);
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
test(Thread.currentThread().getName());
}
}, threadName);
thread.start();
}
}
private static synchronized void test(String threadName) {
for (int i = 0; i < 5; i++) {
System.out.println("线程【" + threadName + "】 输出: " + (i + 1));
}
}
}
日志输出
线程序号:1
线程序号:2
线程序号:3
线程【1】 输出: 1
线程【1】 输出: 2
线程【1】 输出: 3
线程【1】 输出: 4
线程【1】 输出: 5
线程【3】 输出: 1
线程【3】 输出: 2
线程【3】 输出: 3
线程【3】 输出: 4
线程【3】 输出: 5
线程【2】 输出: 1
线程【2】 输出: 2
线程【2】 输出: 3
线程【2】 输出: 4
线程【2】 输出: 5
注:所有变量均存储在主内存,每个线程会把自己要用到的变量从主内存复制一份副本存储到自己的工作内存使用
- 锁代码块
public class Test {
public static void main(String[] args) {
Object lock = new Object();
for (int i = 0; i < 3; i++) {
String threadName = "" + (i + 1);
System.out.println("线程序号:" + threadName);
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
for (int i = 0; i < 5; i++) {
System.out.println("线程【" + Thread.currentThread().getName() + "】 输出: " + (i + 1));
}
}
}
}, threadName);
thread.start();
}
}
}
输出日志
线程序号:1
线程序号:2
线程序号:3
线程【1】 输出: 1
线程【1】 输出: 2
线程【1】 输出: 3
线程【1】 输出: 4
线程【1】 输出: 5
线程【3】 输出: 1
线程【3】 输出: 2
线程【3】 输出: 3
线程【3】 输出: 4
线程【3】 输出: 5
线程【2】 输出: 1
线程【2】 输出: 2
线程【2】 输出: 3
线程【2】 输出: 4
线程【2】 输出: 5
3.2、synchronized实现同步机制的原理
- 对于同步方法,JVM采用ACC_SYNCHRONIZED标记符实现同步
- 对于同步代码块,JVM采用monitorenter、monitorexit两个指令实现同步

无论是ACC_SYNCHRONIZED还是monitorenter、monitorexit都是基于Monitor实现的,在Java虚拟机(HotSpot)中,Monitor是基于C++实现的,由ObjectMonitor实现。
ObjectMonitor类中提供了几个方法,如enter、exit、wait、notify、notifyAll等。
sychronized加锁的时候,会调用objectMonitor的enter方法,解锁的时候会调用exit方法。
(1)synchronized与原子性
- 在Java中,为了保证原子性,提供了两个高级的字节码指令monitorenter和monitorexit。前面中,介绍过,这两个字节码指令,在Java中对应的关键字就是synchronized。
- 通过monitorenter和monitorexit指令,可以保证被synchronized修饰的代码在同一时间只能被一个线程访问,在锁未释放之前,无法被其他线程访问到。因此,在Java中可以使用synchronized来保证方法和代码块内的操作是原子性的。
- 线程1在执行monitorenter指令的时候,会对Monitor进行加锁,加锁后其他线程无法获得锁,除非线程1主动解锁。即使在执行过程中,由于某种原因,比如CPU时间片用完,线程1放弃了CPU,但是,他并没有进行解锁。而由于synchronized的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码。直到所有代码执行完。这就保证了原子性。
(2)synchronized与可见性
- 被synchronized修饰的代码,在开始执行时会加锁,执行完成后会进行解锁。
- 而为了保证可见性,有一条规则是这样的:对一个变量解锁之前,必须先把此变量同步回主存中。这样解锁后,后续线程就可以访问到被修改后的值。
(3)synchronized与有序性
- 除了引入了时间片以外,由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如load->add->save 有可能被优化成load->save->add 。这就是可能存在有序性问题。
- synchronized是无法禁止指令重排和处理器优化的。也就是说,synchronized无法避免上述提到的问题。
- 那么,为什么还说synchronized也提供了有序性保证呢?
- 这就要再把有序性的概念扩展一下了。Java程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有操作都是天然有序的。如果在一个线程中观察另一个线程,所有操作都是无序的。
- 以上这句话也是《深入理解Java虚拟机》中的原句,但是怎么理解呢?周志明并没有详细的解释。这里我简单扩展一下,这其实和as-if-serial语义有关。
- as-if-serial语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果都不能被改变。编译器和处理器无论如何优化,都必须遵守as-if-serial语义。
- 这里不对as-if-serial语义详细展开了,简单说就是,as-if-serial语义保证了单线程中,指令重排是有一定的限制的,而只要编译器和处理器都遵守了这个语义,那么就可以认为单线程程序是按照顺序执行的。当然,实际上还是有重排的,只不过我们无须关心这种重排的干扰。
- 所以呢,由于synchronized修饰的代码,同一时间只能被同一线程访问。那么也就是单线程执行的。所以,可以保证其有序性。
4、volatile
- volatile的用法比较简单,只需要在声明一个可能被多线程同时访问的变量时,使用volatile修饰就可以了
4.1、volatile 原理
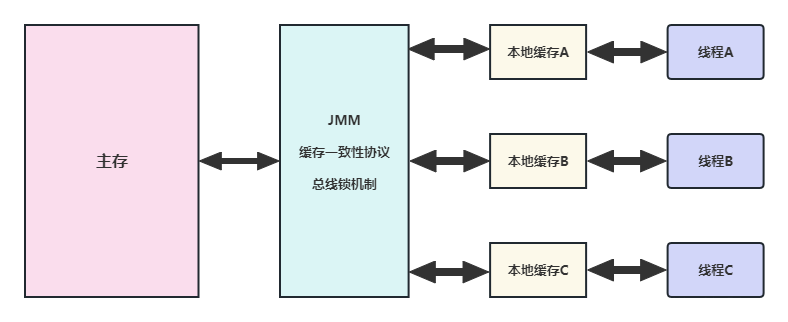
- 如果一个变量被volatile所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个volatile在并发编程中,其值在多个缓存中是可见的。
- 缓存一致性协议:每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
(1)volatile与可见性
- 被volatile修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新
(2)volatile与有序性
- volatile可以禁止指令重排,这就保证了代码的程序会严格按照代码的先后顺序执行
(3)volatile不保证原子性
- 原子性:指一个操作是不可中断的,要全部执行完成,要不就都不执行
public class Test2 {
public volatile int cnt = 0;
public void cntIncrease(String threadName) {
cnt++;
System.out.println("线程【" + threadName + "】:" + cnt);
}
public static void main(String[] args) {
final Test2 t2 = new Test2();
for (int i = 0; i < 10; i++) {
String threadName = "" + (i + 1);
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 1000; j++) {
t2.cntIncrease(Thread.currentThread().getName());
}
}
}, threadName);
thread.start();
}
//获取当前线程活跃数量
int activeThreadNum = Thread.activeCount();
System.out.println("当前线程活跃数量:" + activeThreadNum);
//打印当前活跃线程
Thread.currentThread().getThreadGroup().list();
while (activeThreadNum > 2) {
//yield()让掉当前 CPU 的调度权,等下次获取到再继续执行
// 这样不但能完成自己的重要工作,也能给其他线程一些运行的机会
// 避免一个线程长时间占有 CPU 资源。
Thread.yield();
//获取当前线程活跃数量
activeThreadNum = Thread.activeCount();
System.out.println("当前线程活跃数量:" + activeThreadNum);
//打印当前活跃线程
Thread.currentThread().getThreadGroup().list();
}
System.out.println("最终值:" + t2.cnt);
}
}
日志输出(部分日志)
线程【4】:9970
线程【4】:9971
Thread[#31,9,5,]
线程【5】:9968
线程【5】:9973
线程【5】:9974
线程【5】:9975
线程【5】:9976
线程【5】:9977
线程【5】:9978
线程【4】:9972
线程【4】:9979
线程【4】:9980
线程【4】:9981
线程【4】:9982
Thread[#32,10,5,]
线程【4】:9983
线程【4】:9984
线程【4】:9985
线程【4】:9986
当前线程活跃数量:3
线程【4】:9987
线程【4】:9988
线程【4】:9989
线程【4】:9990
线程【4】:9991
线程【4】:9992
线程【4】:9993
线程【4】:9994
线程【4】:9995
线程【4】:9996
线程【4】:9997
线程【4】:9998
线程【4】:9999
java.lang.ThreadGroup[name=main,maxpri=10]
Thread[#1,main,5,main]
Thread[#20,Monitor Ctrl-Break,5,main]
Thread[#26,4,5,]
当前线程活跃数量:2
java.lang.ThreadGroup[name=main,maxpri=10]
Thread[#1,main,5,main]
Thread[#20,Monitor Ctrl-Break,5,main]
最终值:9999
我们希望最终值是1w,但实际小于1w。原因就是volatile不支持原子性,即cnt++不具有原子性。比如,由于volatile支持可见性,所以Thread【1】和Thread【2】都可以看到cnt的当前值(假设cnt=520),那么Thead【1】执行了520+1=521,Thread【2】也执行了520+1=521,那么就无法达到1w
4.2、补充点
(1)Thread.activeCount()
- 用于返回当前线程的线程组中活动线程的数量
- 返回的值只是一个估计值,因为当此方法遍历内部数据结构时,线程数可能会动态更改
(2)IntelliJ IDEA 编译器中,最终Thread.activeCount() == 2原因
当前线程活跃数量:2
java.lang.ThreadGroup[name=main,maxpri=10]
Thread[#1,main,5,main]
Thread[#20,Monitor Ctrl-Break,5,main]
- 除了main以外,还多了一个预期外的 Monitor Ctrl-Break 线程
- IntelliJ IDEA执行用户代码的时候,实际是通过反射方式去调用,而与此同时会创建一个Monitor Ctrl-Break 用于监控目的
(3)Thread.yield()
- yield 方法可以很好的控制多线程,如执行某项复杂的任务时,如果担心占用资源过多,可以在完成某个重要的工作后使用 yield 方法让掉当前 CPU 的调度权,等下次获取到再继续执行,这样不但能完成自己的重要工作,也能给其他线程一些运行的机会,避免一个线程长时间占有 CPU 资源。
yield 和 sleep 的异同
- yield, sleep 都能暂停当前线程,sleep 可以指定具体休眠的时间,而 yield 则依赖 CPU 的时间片划分
- yield, sleep 两个在暂停过程中,如已经持有锁,则都不会释放锁资源
- yield 不能被中断,而 sleep 则可以接受中断
public class Test3 {
/**
* 当是10的倍数时,当前线程便让出自己的CPU时间片
*/
public static void main(String[] args) {
Runnable runnable = () -> {
for (int i = 0; i < 10000; i++) {
System.out.println(Thread.currentThread().getName() + ":" + (i + 1));
if (i % 10 == 0) {
Thread.yield();
}
}
};
new Thread(runnable, "鸣人").start();
new Thread(runnable, "佐助").start();
}
}
最终有两种结果
- 鸣人先跑完
佐助:9994
佐助:9995
佐助:9996
佐助:9997
佐助:9998
佐助:9999
佐助:10000
- 佐助先跑完
鸣人:9996
鸣人:9997
佐助:9999
佐助:10000
鸣人:9998
鸣人:9999
鸣人:10000
如果给线程加上优先级,则结果也会不同
Thread threadNaruto = new Thread(runnable, "鸣人");
Thread threadSasuke = new Thread(runnable, "佐助");
threadNaruto.setPriority(Thread.MAX_PRIORITY);
threadSasuke.setPriority(Thread.MIN_PRIORITY);
threadSasuke.start();
threadNaruto.start();
给鸣人最大优先级,给佐助最小优先级,则即使佐助先跑,也大概率是鸣人先跑完
内存模型
synchronized
volatile 1
volatile 2
volatile 3