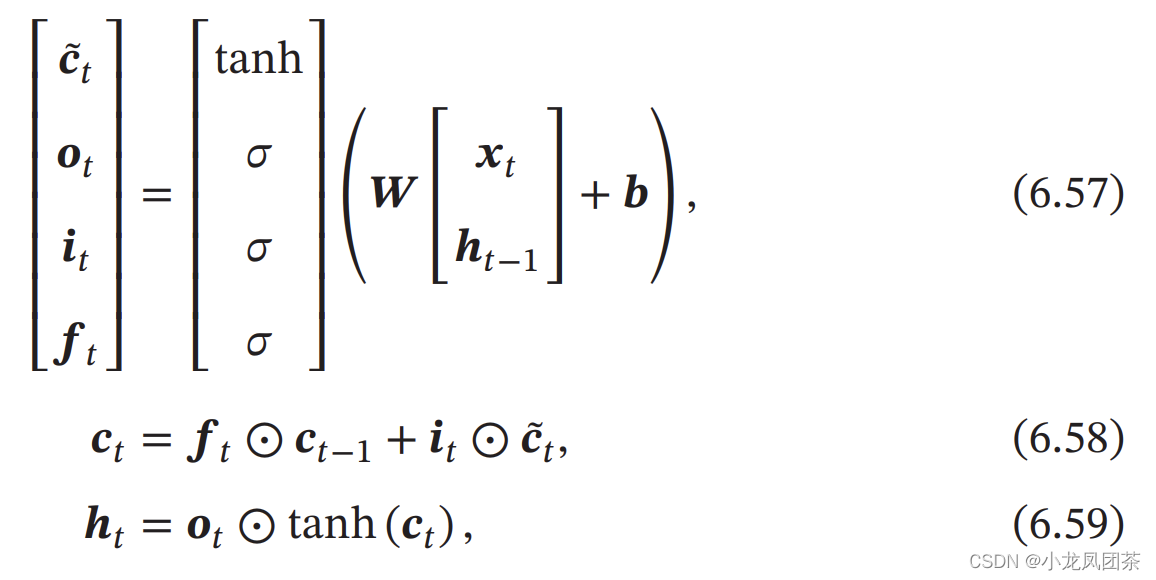深度学习与神经网络阅读笔记(持续更新)
- 机器学习基础
- 绪论
- 人工智能主要领域可分为如下:
- 人工智能的发展史:
- 机器学习
- 表示学习
- 深度学习
- 线性模型
- Logistic回归
- Softmax回归
- 感知器
- 支持向量机
- 总结对比
- 基础模型
- 循环神经网络
- 应用到机器学习
- 序列到类别模式
- 同步的序列到序列模式
- 异步的序列到序列模式
- 基于门控的循环神经网络
- LSTM
本书的知识体系

机器学习基础
绪论
人工智能主要领域可分为如下:
- 感知:模拟人的感知能力,对外部刺激信息(视觉和语音等)进行感知和加工.主要研究领域包括语音信息处理和计算机视觉等.
- 学习:模拟人的学习能力,主要研究如何从样例或从与环境的交互中进行学习.主要研究领域包括监督学习、无监督学习和强化学习等.
- 认知:模拟人的认知能力,主要研究领域包括知识表示、自然语言理解、推理、规划、决策等.
人工智能的发展史:

机器学习
机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。
由于数据的多样性,在实际任务中使用机器学习模型一般会包含以下几个步骤:
- 数据预处理:经过数据的预处理,如去除噪声等.比如在文本分类中,去除停用词等.
- 特征提取:从原始数据中提取一些有效的特征.比如在图像分类中,提取边缘、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征等.
- 特征转换:对特征进行一定的加工,比如降维和升维.降维包括特征抽取(Feature Extraction)和特征选择(Feature Selection)两种途径.常用的特征转换方法有主成分分析(Principal Components Analysis,PCA)、 线性判别分析(Linear Discriminant Analysis,LDA)等.
- 预测:机器学习的核心部分,学习一个函数并进行预测.

机器学习的重要工作量都在前三步的特征处理上,这决定了最终系统的准确性,统称为的特征工程
表示学习
为了提高机器学习系统的准确率,我们就需要将输入信息转换为有效的特征,或者更一般性地称为表示(Representation).如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就可以叫作表示学习(Representation Learning).
语义鸿沟: 表示学习的关键是解决语义鸿沟(Semantic Gap)问题.语义鸿沟问题是指输入数据的底层特征和高层语义信息之间的不一致性和差异性
如果可以有一个好的表示在某种程度上能够反映出数据的高层语义特征,那么我们就能相对容易地构建后续的机器学习模型.
两种方式来表示特征:局部表示(Local-Representation)和分布式表示(Distributed Representation)
局部表示,也称为离散表示或符号表示.局部表示通常可以表示为one-hot 向量的形式,例如要表示不同的颜色:假设所有颜色的名字构成一个词表 v v v ,词表大小为 ∣ v ∣ |v| ∣v∣.我们可以用一个 ∣ v ∣ |v| ∣v∣维的one-hot向量来表示每一种颜色.在第 i i i种颜色对应的one-hot向量中,第 i i i维的值为1,其他都为0.
优点:
- 这种离散的表示方式具有很好的解释性,有利于人工归纳和总结特征,并通过特征组合进行高效的特征工程;
- 通过多种特征组合得到的表示向量通常是稀疏的二值向量,当用于线性模型时计算效率非常
高
缺点:
- one-hot向量的维数很高,且不能扩展.如果有一种新的颜色,我们就需要增加一维来表示;
- 不同颜色之间的相似度都为0,即我们无法知道“红色”和“中国红”的相似度要高于“红色”和“黑色”的相似度.
分布式表示:可以理解为分散式表示,即一种颜色的语义分散到语义空间中的不同基向量上。对于表示不同颜色的例子则为:用RGB值来表示颜色,不同颜色对应到R、G、B三维空间中一个点。
嵌入:嵌入通常指将一个度量空间中的一些对象映射到另一个低维的度量空间中,并尽可保持不同对象之间的拓扑关系.比如自然语言中词的分布式表示,也经常叫作词嵌入。
深度学习
构建具有一定“深度”的模型,并通过学习算法来让模型自动学习出好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测模型的准确率.所谓“深度”是指原始数据进行非线性特征转换的次数.如果把一个表示学习系统看作一个有向图结构,深度也可以看作从输入节点到输出节点所经过的最长路径的长度.

深度学习是将原始的数据特征通过多步的特征转换得到一种特征表示,并进一步输入到预测函数得到最终结果.和“浅层学习”不同,深度学习需要解决的关键问题是贡献度分配问题(Credit Assignment Problem,CAP)[Minsky,1961],即一个系统中不同的组件(component)或其参数对最终系统输出结果的贡献或影响。
(深度学习可以看作一种强化学习(Reinforcement Learning,RL),每个内部组件并不能直接得到监督信息,需要通过整个模型的最终监督信息(奖励)得到,并且有一定的延时性.)
端到端学习(End-to-End Learning):在学习中不划分模块,训练数据为“输入-输出”对的形式,没有其他额外数据。同深度学习一样解决贡献度分配问题,目前,大部分采用神经网络模型的深度学习也可以看作一种端到端的学习
区别于端到端学习,传统机器学习方法需要将一个任务的输入和输出之间人为地切割成很多子模块(或多个阶段),每个子模块分开学习比。如一个自然语言理解任务,一般需要分词、词性标注、句法分析、语义分析、语义推理等步骤.这种学习方式有两个问题:一是每一个模块都需要单独优化,并且其优化目标和任务总体目标并不能保证一致;二是错误传播,即前一步的错误会对后续的模型造成很大的影响.这样就增加了机器学习方法在实际应用中的难度.
线性模型
一个线性分类模型(Linear Classification Model)或线
性分类器(Linear Classifier),是由一个(或多个)线性的判别函数
f
(
x
,
w
)
=
w
T
x
+
b
f(x,w)=w^Tx+b
f(x,w)=wTx+b和非线性的决策函数
g
(
⋅
)
g(⋅)
g(⋅) 组成
这里主要介绍四种线性模型,其区别在于损失函数的不同
Logistic回归
Logistic 回归(Logistic Regression,LR)是一种常用的处理二分类问题的线性模型
Logistic 回归采用交叉熵作为损失函数,并使用梯度下降法来对参数进行优化.
Softmax回归
Softmax 回归(Softmax Regression),也称为多项(Multinomial)或多类(Multi-Class)的Logistic回归,是Logistic回归在多分类问题上的推广.
Softmax回归使用交叉熵损失函数来学习最优的参数矩阵
w
w
w.
W
=
[
w
1
.
.
w
C
]
W = [w_1 .. w_C]
W=[w1..wC]是由
C
C
C个类的权重向量组成的矩阵,
1
C
1_C
1C为C维的全1向量, 第
C
C
C维的值是第
C
C
C类的预测条件概率.
要注意的是,Softmax回归中使用的
C
C
C个权重向量是冗余的,即对所有的权重向量都减去一个同样的向量
v
v
v,不改变其输出结果.因此,Softmax回归往往需要使用正则化来约束其参数.此外,我们还可以利用这个特性来避免计算Softmax函数时在数值计算上溢出问题.
感知器
就是一个单神经元
支持向量机
存在一个超平面能够划分所有数据
支持向量机的目标是寻找一个超平面使得所有样本到分割超平面的最短距离最大。
总结对比


基础模型
循环神经网络
应用到机器学习
序列到类别模式
文本分类
将一个序列的最后一个时刻的隐藏状态
h
t
h_t
ht作为序列的特征表示,输入到分类器
g
(
.
)
g(.)
g(.)中.
其中
g
(
⋅
)
g(⋅)
g(⋅)可以是简单的线性分类器(比如Logistic回归)或复杂的分类器(比如多层前馈神经网络)
除了将最后时刻的状态作为整个序列的表示之外,我们还可以对整个序列的所有状态进行平均,并用这个平均状态来作为整个序列的表示,即
同步的序列到序列模式
同步的序列到序列模式主要用于序列标注(Sequence Labeling)任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同.比如在词性标注(Part-of-Speech Tagging)中,每一个单词都需要标注其对应的词性标签.

异步的序列到序列模式
异步的序列到序列模式也称为编码器-解码器(Encoder-Decoder)模型,即输入序列和输出序列不需要有严格的对应关系,也不需要保持相同的长度.比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列.

基于门控的循环神经网络
LSTM