文章目录
- 一 需求
- 二 操作思路
- 1 拿到主页面的源代码,提取链接地址href
- 2 通过href拿到子页面的内容,并找到图片下载地址 img ---> src
- 3 下载图片
- 三 分析步骤
- 1 拿到主页面的源代码,提取链接地址href
- 2 通过href拿到子页面的内容,并找到图片下载地址 img ---> src
- 3 下载图片
- 四 完整代码
一 需求
拿到某网站的动漫图片
二 操作思路
1 拿到主页面的源代码,提取链接地址href
2 通过href拿到子页面的内容,并找到图片下载地址 img —> src
3 下载图片
三 分析步骤
1 拿到主页面的源代码,提取链接地址href
基于get请求,获取网页源代码的步骤分析,此处不作具体说明,可参考笔者的文章。
python-(6-3-1)爬虫—requests入门(基于get请求)
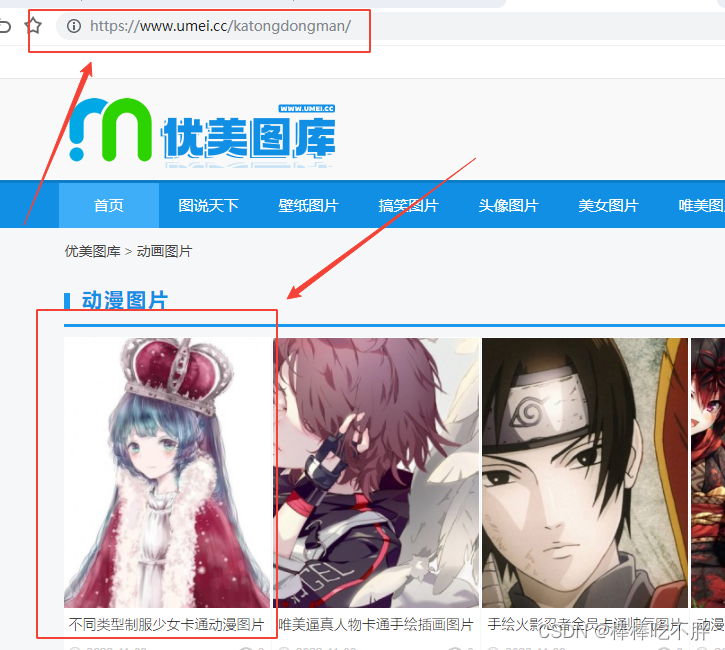
接着打开网页源代码,提取子页面的链接地址。
按住ctrl+F,搜索taotu-main,我们可以定位找到这些子页面的链接地址信息。

然后得到所有"a"标签的信息,将其遍历循环,从而得到每一个"a"标签后面对应的href,也就是子链接。
2 通过href拿到子页面的内容,并找到图片下载地址 img —> src
拿到子页面的源代码,然后从中拿到图片的下载地址
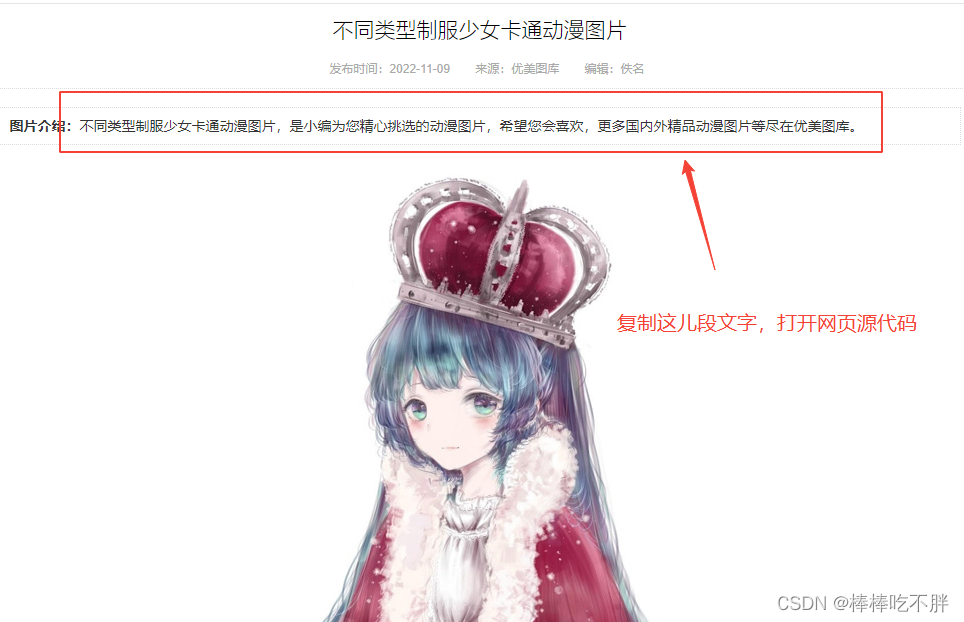
接着在网页源代码中搜索复制的文字,定位到这张图片的位置。

然后通过代码,就可以实现对下载地址的获取。
3 下载图片
如果想要将图片存储在某一文件夹下,需要提前创建好文件目录。
在下载较多的图片时,为了防止高频的网站请求被服务器挂掉,我们可以导入time模块,通过sleep程序,让程序等待几秒钟,然后再进行新的页面访问请求。
另外,在执行代码时,pycharm会对当前加载的文件夹中的所有内容做一个索引,以便快速查找数据。而我们下载的图片尽管是新增的文件,但pycharm也会对其建立索引。当下载的图片很多时,会占用系统资源,让pycharm很卡,所以图片文件的索引便没有构建的必要。
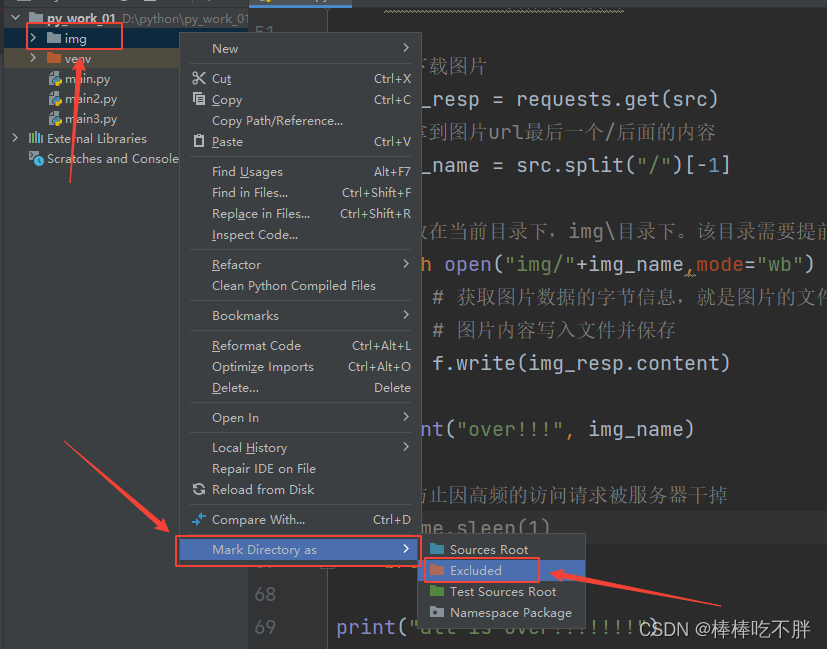
如上图操作,便可以取消对其文件夹建立索引。
四 完整代码
import requests
import sys
import io
from bs4 import BeautifulSoup
import time
# 改变标准输出的默认编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
domain = 'https://www.umei.cc/katongdongman/'
headers = {
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36"
}
resp = requests.get(url=domain,headers=headers)
# 与网页源代码上的字符集对应
resp.encoding = "utf-8"
#print(resp.text)
# 把源代码交给bs
main_page = BeautifulSoup(resp.text,"html.parser")
# 把范围缩小,找到"taotu_main"下面的所有的"a"标签
a_list = main_page.find("div", class_= "taotu-main").find_all("a")
# 网站url
url_pre = "https://www.umei.cc"
# 遍历每一个a标签
for a in a_list:
# 通过get拿到每个a标签中href属性的值
href = a.get("href")
url = url_pre + href
# 拿到子页面的源代码
child_page_resp = requests.get(url)
child_page_resp.encoding = 'utf-8'
child_page_text = child_page_resp.text
# 从子页面中拿到图片的下载链接
child_page = BeautifulSoup(child_page_text, "html.parser")
# 找到div标签
div = child_page.find("div", class_="big-pic")
# 找到div下面的img
img = div.find("img")
# 找到img下面的src图片下载地址
src = img.get("src")
print(src)
#break # 仅作测试使用
# 下载图片
img_resp = requests.get(src)
# 拿到图片url最后一个/后面的内容
img_name = src.split("/")[-1]
# 放在当前目录下,img\目录下。该目录需要提前创建好
with open("img/"+img_name,mode="wb") as f:
# 获取图片数据的字节信息,就是图片的文件
# 图片内容写入文件并保存
f.write(img_resp.content)
print("over!!!", img_name)
# 每次遍历后程序休息1秒钟,防止因高频的访问请求被服务器干掉
time.sleep(1)
#break #测试需要
print("all is over!!!!!!!")
# 关闭访问请求的连接
resp.close()










![[附源码]计算机毕业设计酒店物联网平台系统Springboot程序](https://img-blog.csdnimg.cn/30b74a78aced4c44af21865dc0a7ce0a.png)