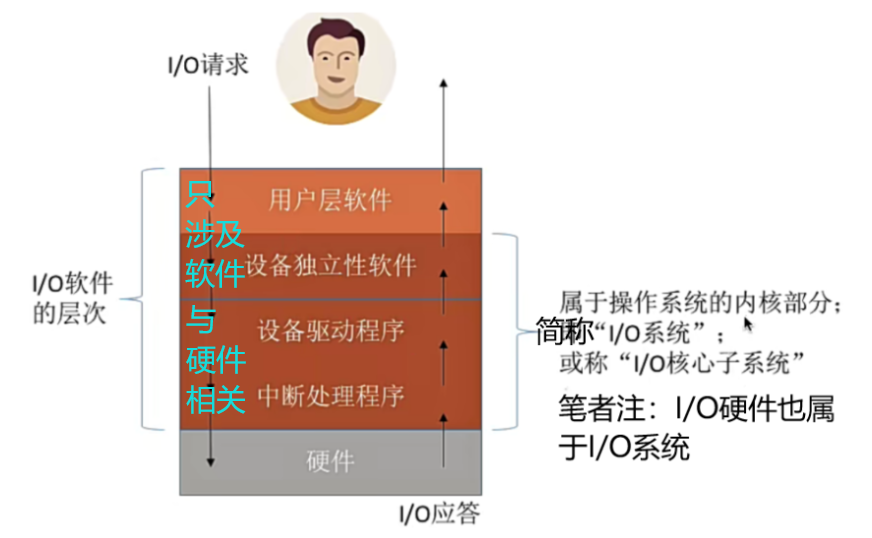
语音识别之Kaldi
kaldi语音识别理论与实践课程学习。
前面的博客介绍了语音识别的基础知识及原理。现在开始学习实战。以Kaldi框架为基础。
Kaldi是一个有全套的语音识别代码的工具,由Dan Povey博士和捷克的BUT大学联合开发,最早发布于2011年,底层代码使用C++编写,接口采用shell和python,覆盖了统计模型和深度学习方法,操作灵活,易于扩展,开发者更为活跃。
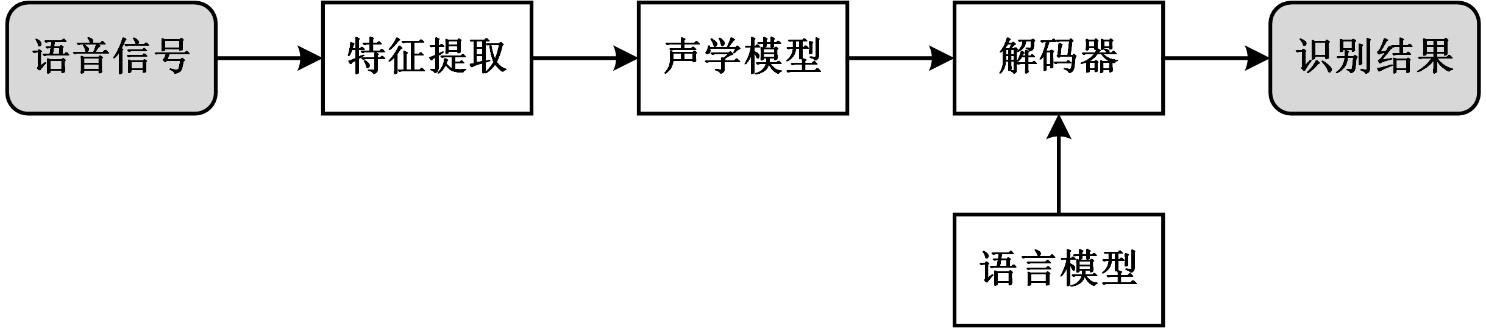
语音识别流程:
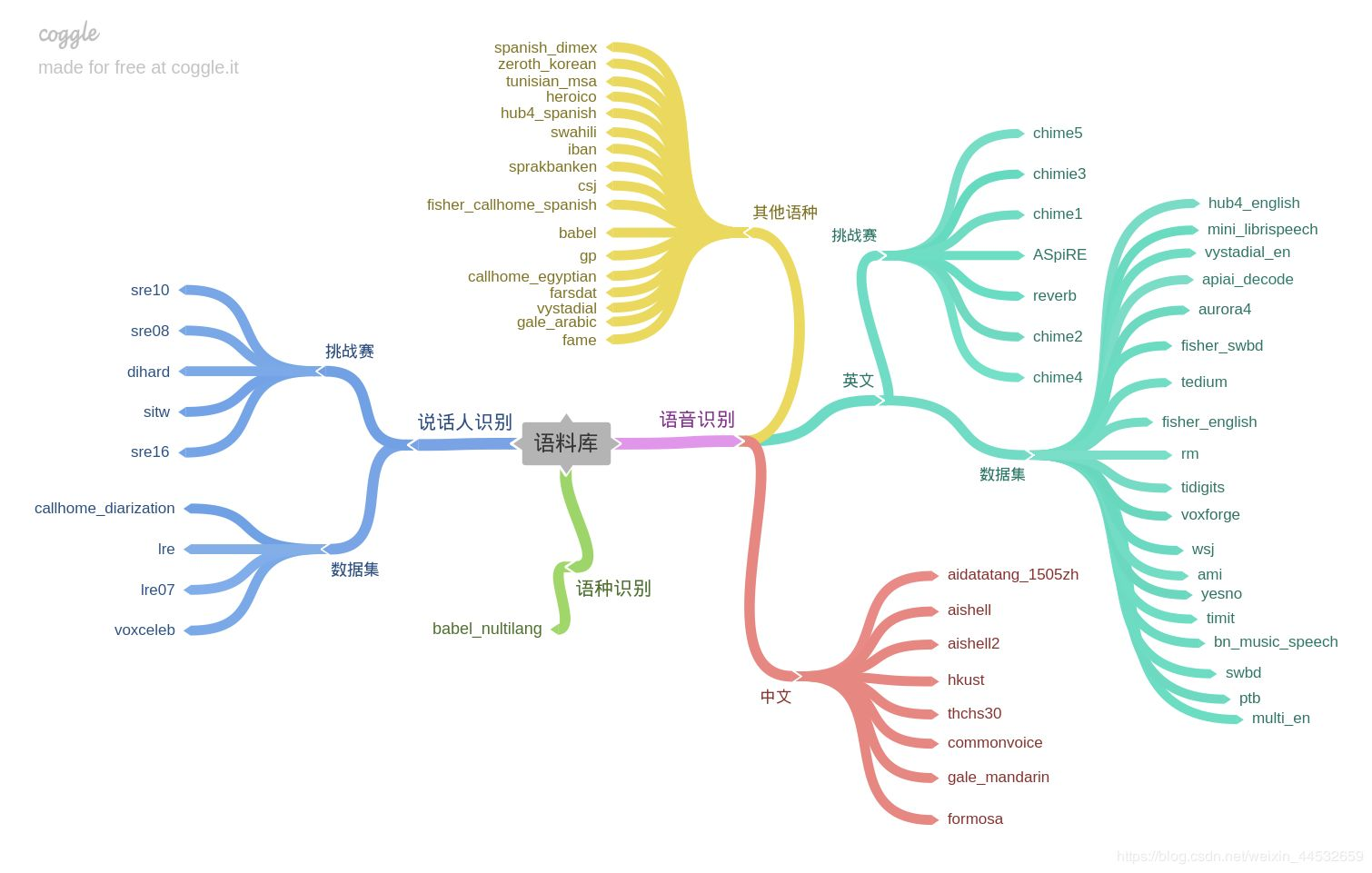
目前开源的语料库有:
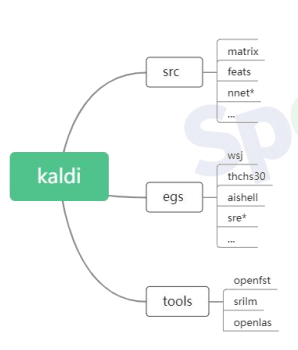
Kaldi实战
Kaldi官网:KALDI
里面有详细的文档。

-
下载Kaldi:https://github.com/du-ud/kaldi-cslt.git
注: 安装kaldi前, 已编译好cuda
-
下载数据集:(开源数据集thchs30)
OpenSLR: https://openslr.org/18/
整个流程包括以下几个部分:
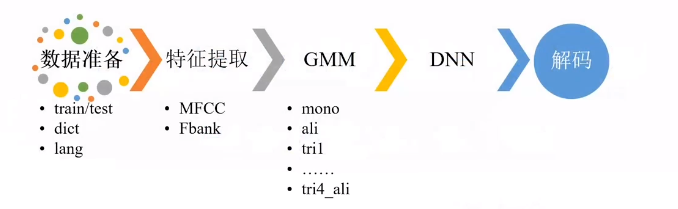
数据准备
数据预处理
1.划分为训练集train和测试集test
输入: 数据存储地址
输出: 在当前目录下新生成的 /data 文件夹,里面如下图。train和test里的文件夹名字一样,但内容不一样,不然就是作弊了。
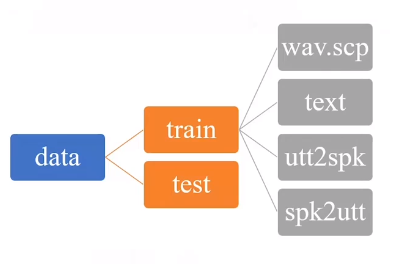
- wav.scp:音频索引地址

- text:音频文件对应的文本内容
这个文本内容中间有一些空格,因为是经过了分词处理

- utt2spk:每个句子是有哪个说话人说的

- spk2utt:每个说话人都说了哪些句子

为什么有后两个文件夹呢?
因为之前的数据比较稀少,说话人对语音识别性能的影响比较大,可能同一套ASR对这个人识别效果好,对另一个人就不行。现在可以通过某种算法,先提取说话人信息,将该信息从说话人模型中去除,就可以较小不同说话人的影响。但后面随着数据的增多,就不用去除了。
2.生成dict文件夹
dict 文件夹里如下:

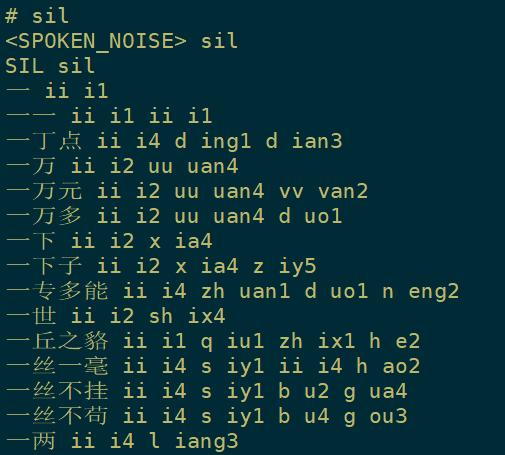
去除了lexion里面的一些特殊符号。首先打开看一下:
cd data/dict/
vim lexicon.txt
lexion是一个发音词典,表示每个字的读音,但它的注音和我们的拼音不太一样但也差不多
再看看lang里面的
cd data/dict/
vim extra_questions.txt
将具有相同还声调的音归为一行,为了有助于GMM训练时决策树的聚类。如果后面训练别的语种,不知道这些信息的话就把这和文件设为空。

cd data/dict/
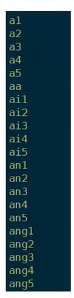
vim nonsilence_phones.txt
去除静音音素之外,所有音素的集合。
3.生成lang文件夹
是在dict基础上生成的。
首先在data文件夹下建一个lang文件夹,调用prepare_lang.sh这个脚本,输入是dict文件,输出在lang文件夹下。
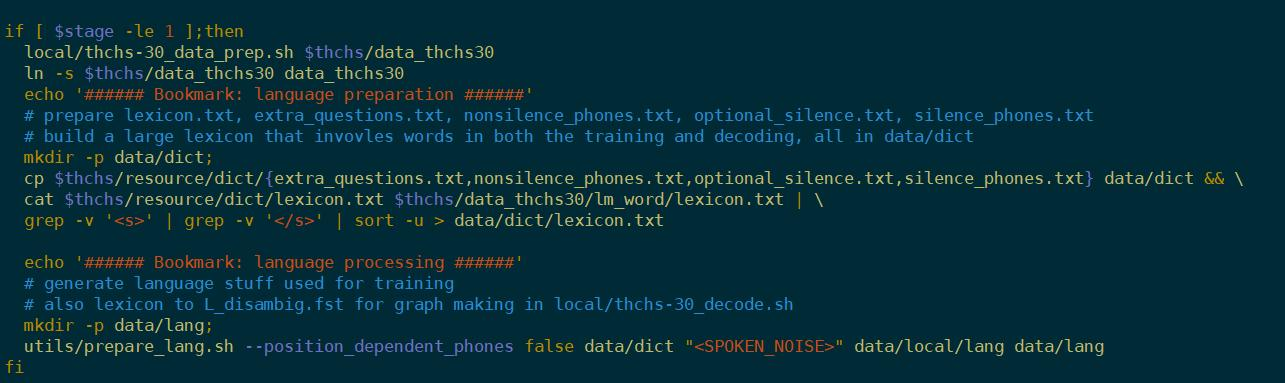
里面的两个参数:
第一个考虑到英文的某个单词是另一个单词的前缀或后缀(位置相关),在数据有限的情况下,考虑位置信息提高性能。数据量大的话不用考虑。
第二个就是系统将不认识的词映射到oov里面。

lang文件夹里如下:

- L.fst:音素到词的映射关系。输入的是音素,输出是词。
cd data/lang
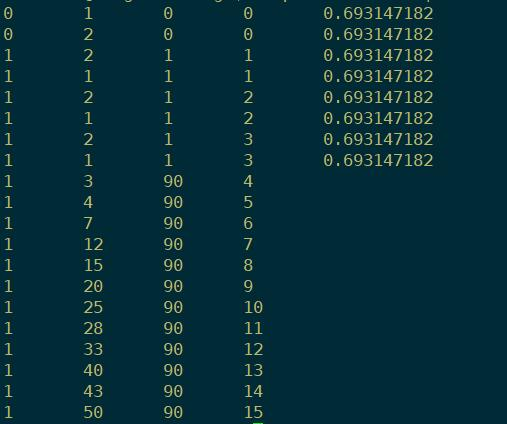
fstprint L.fst | head -n 20
例:第一行
前两个数,表示从0状态跳转到1状态
三四数:输入输出表达的什么东西
第五个数:跳转的概率
加上输入phones和输出words重新打印
cd data/lang
fstprint --osymbols=words.txt --isymbols=phones.txt L.fst | head -n 20
第三列:phone的id
第四列:word的id
第五列:预先赋予的跳转概率(给eps, spokenNoise等这些特殊符号的),下面那些词的概率需要经过声学&语言模型的训练得到的。
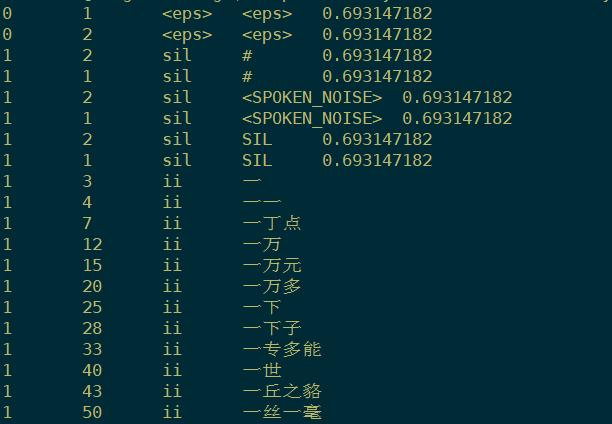
- oov:将不认识的集外词映射到里面去。
- phones.txt:音素映射表,对每个音素进行编号
- phones文件夹:用于决策树聚类
我们看一下里面
cd data/lang
head -n 20 phones.txt
出现下图中间的一个。
数据准备-phone、word与lexicon的关系
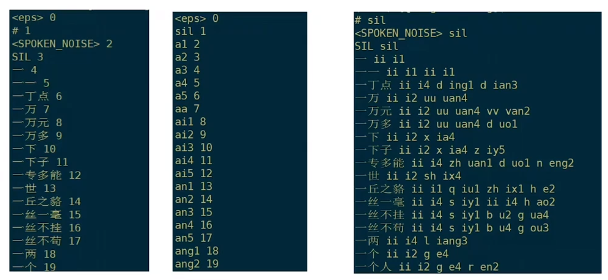
- words.txt:词映射表,对每个词进行编号
里面的词和发音词典的词基本一一对应(发音词典大概有五万多个词,对应的词表只有四万九千多个,近几年的新词还没包含进去)
cd data/lang
head -n 20 words.txt
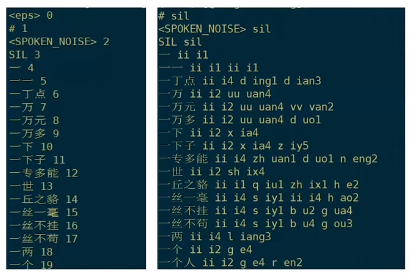
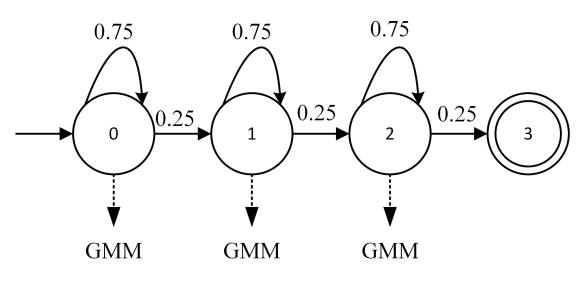
- topo:拓扑图,隐马尔可夫网络HMM
cd data/lang
vim topo
里面有两个HMM网络,一个是普通音素的,一个是静音音素的。
下图从2到218就是phone的id, 然后是HMM的三个跳转状态和一个输出状态。
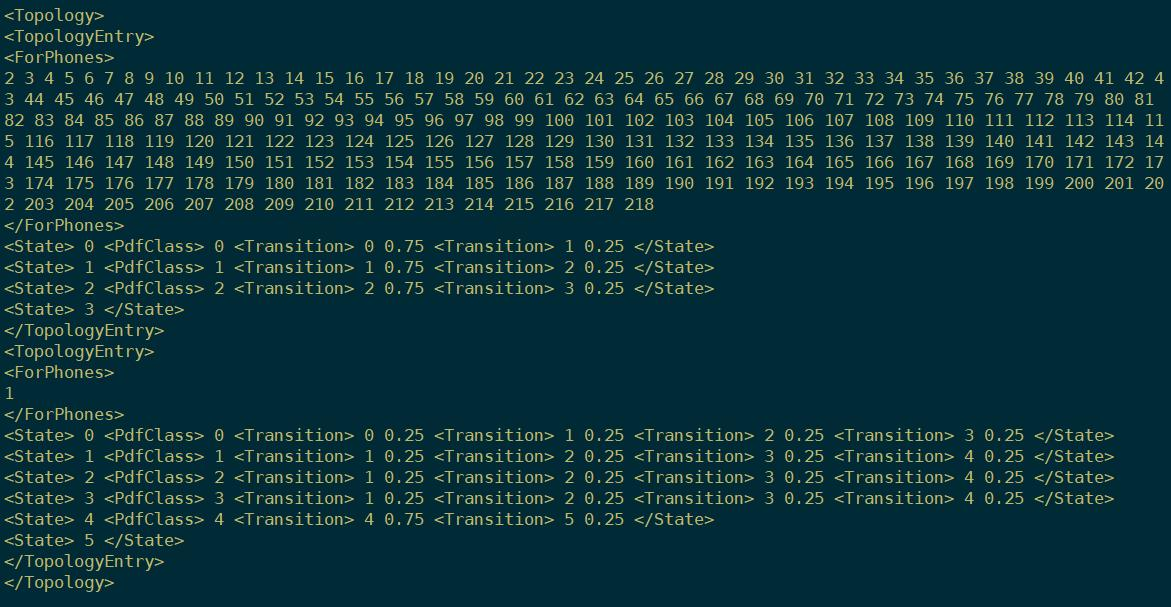
跳转状态图:
特征提取
目前常见的两种特征。一般MFCC特征用于GMM训练,FBANK特征用于DNN训练。
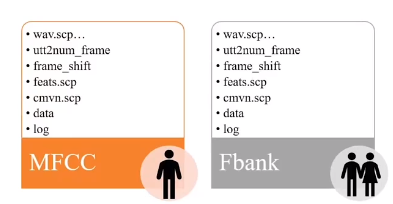
先删除残留文件夹,新建两个目录,将训练集和测试集复制进去。
提取MFCC及FBank特征,并计算其均值和方差。
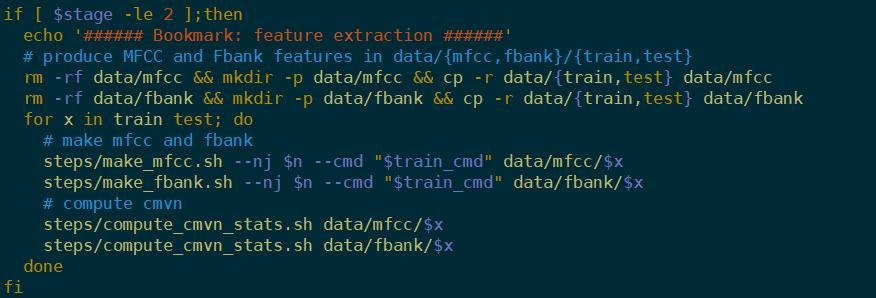
MFCC和FBank特征提取原理:
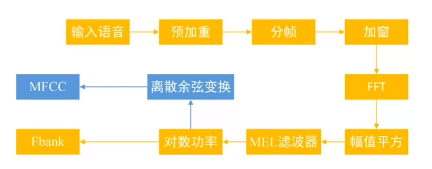

计算MFCC命令
. ./path.sh
compute-mfcc-feats
比如:参数1和2就是降采样和升采样。这些选项可以放到.conf配置文件里面。
生成如下目录:
cd data/mfcc/train
ls

查看MFCC:
. ./path.sh
cd data/mfcc/train/data
copy-feats ark:raw_mfcc_train.1.ark ark,t:train.1.ark.txt
vim train.1.ark.txt
行:帧数,一帧为一行
列:维度,MFCC特征默认13维
以A02_000音频为例:

然后看下均值方差,是按每个说话人提取的
. ./path.sh
cd data/mfcc/train/data
copy-feats ark:cmvn_train.ark ark,t:cmvn_train.ark.txt
copy-feats --binary=false ark:cmvn_train.ark ark:cmvn_train.ark.txtvim train.1.ark.txt
行:均值总和、方差总和

查看log:
kaldi的log非常全,索引对不上,采样不一致等问题都有。
cd data/mfcc/train/log/
vim make_mfcc_train.1.log
GMM训练
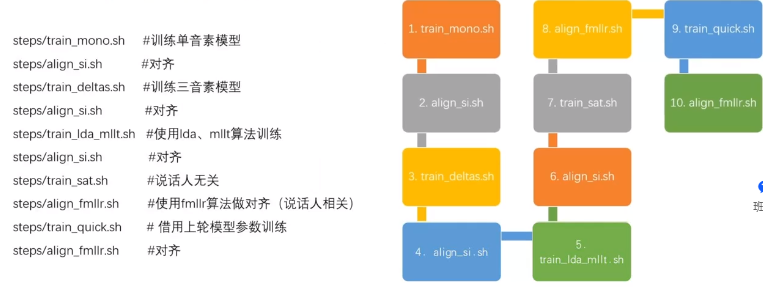
整体过程:
共有5大模块,可分为10小步。每两步一个模块。
1.先训练一个单音素模型;2.对齐
3.再训练一个三音素模型;4.对齐
5.用lda等算法重估GMM模型; 6.对齐
…
mono单音素模型训练
命令如下,
steps/train_mono.sh --boost-silence 1.25 --nj 10 --cmd
"run.pl" data/mfcc/train data/lang exp/mono
参数:
–boost-silence:静音音素权重设置,1.25 一般不用改
–nj 10:就是用10个线程(小于等于训练集中说话人数量)
run.pl:在本机跑
输入1: MFCC数据 ( data/mfcc/train)
输入2: lang (data/lang)
输出: 单音素模型(exp/mono)
具体流程:
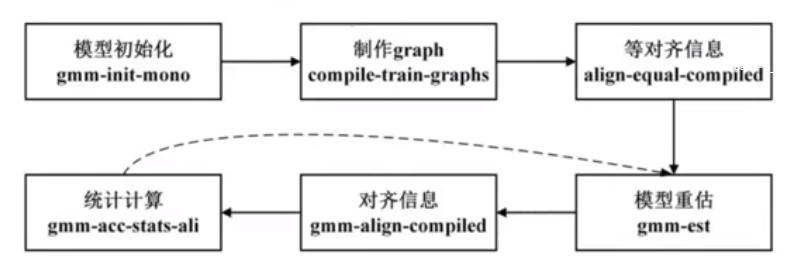
-
模型初始化:有GMM模型的均值、方差,和隐马尔可夫的转移矩阵。随机生成,其实也不是真正随机,用了训练集的部分特征。
-
制作graph:需要输入上一步初始化的模型,lang文件中的L.fst,词表,以及训练集中的标注文本。生成结果是一个从句子到音素的fst压缩包,是训练集中每一个音频对应的文本标签生成的,一个文本标签生成一个fst。(句子-词-字-拼音-音素-HMM中的状态)
-
等对齐:均匀对齐。现在要将MFCC特征和fst对应起来。
黄色是MFCC特征,每条是一帧,一帧是13维。
要与下面的fst对齐。(只画到音素级别)
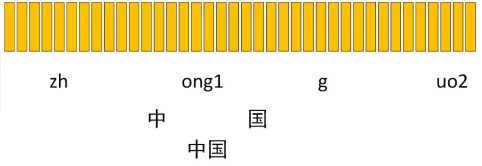
什么是均匀对齐?就是假如现在是4个音素,对应100帧,那就平分,每个音素对100/4=25帧。统计这25帧的均值和方差,就是一个高斯模型了。
后面还有三音素模型(考虑了协调发音):
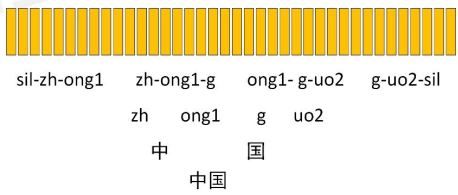
但存在一个问题:本来有两百多个音素,但考虑了前后协同发音,就成了200* 200* 200个了,这个数量太大了。
解决办法:决策树聚类(将具有相近发音的音素归为一类,集中训练) -
模型重估:现在已经统计了全部数据的特征,也通过对齐知道了每帧对应的状态,以及每个状态的跳转概率。基于这些信息对模型进行重估。
-
对齐信息:用重估后的统计量和前面的fst生成新的对齐信息。注意,此时不是均匀对齐了,此时过程可理解为一个模型对训练集的解码过程,把每帧特征放到每个状态对应的GMM里算概率,得到每个状态的后验概率,概率最大的音素作为这一帧对应的音素。
此时可能第一个音素20帧,第二个音素28帧等等。 -
统计计算:计算每个音素跳转的次数占全部跳转次数的比例。得到每个状态的跳转概率,又进行模型重估,重复该过程(重复次数可以自己设置,默认40次)。
跑完代码生成的东西:
在mono文件夹里

final.occs:简单理解为全局统计量,每个音素对应几个状态的信息
aligz:每迭代一次,对齐信息跟新一次
fst..gz:训练集中每条语音对应的文本信息(句子-词-字-拼音-音素-HMM中的状态)都在这里面
final模型查看
声学模型不能直接代开看,用kaldi自带的命令打开:
gmm-copy --binary=false final.mdl final.mdl.txt
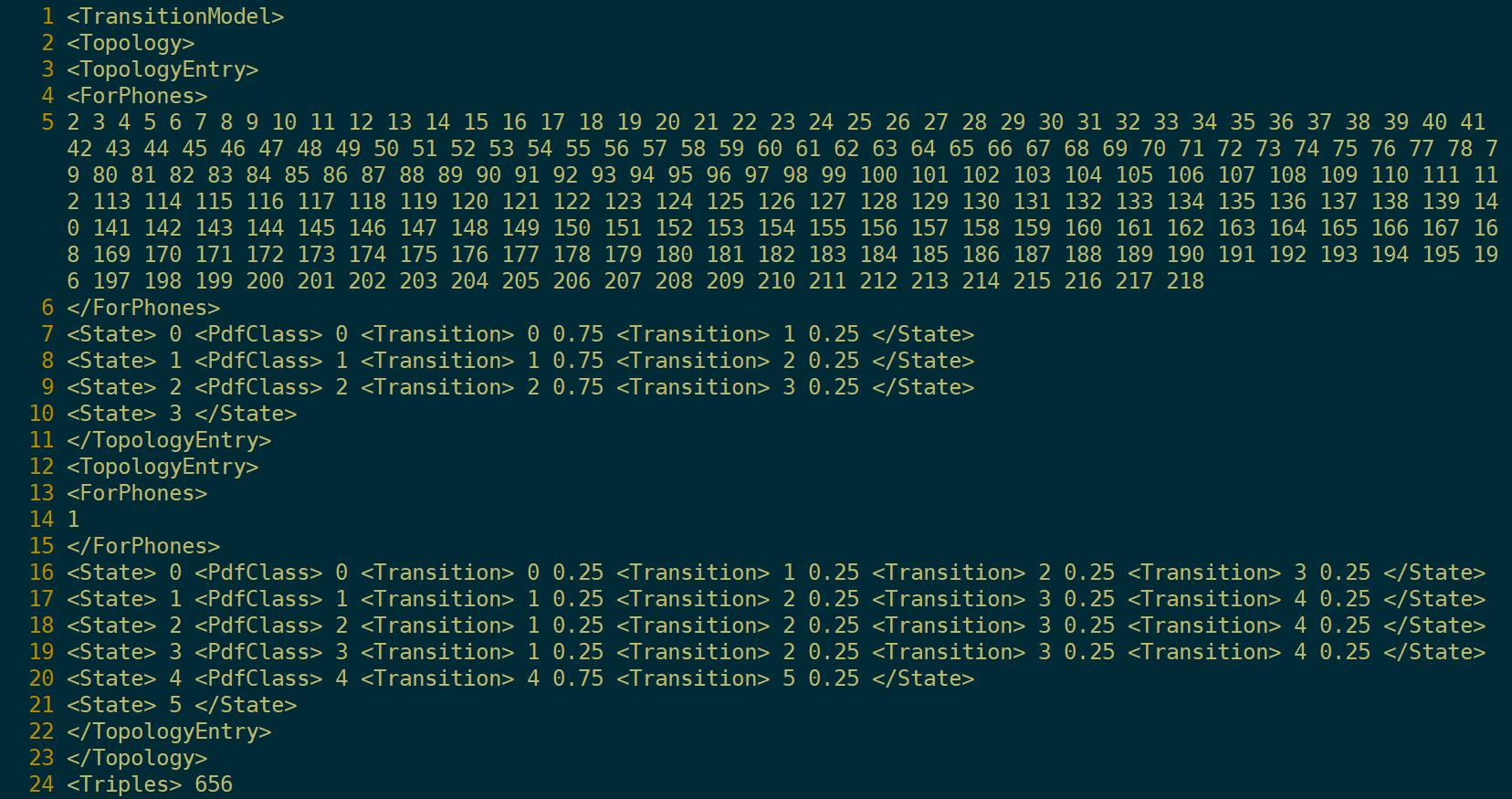
1-23行是HMM的拓扑图。7-10行是音素编号为2-218的HMM,其状态有3个。16-21行是音素编号为1的HMM,其状态有5个,也就是静音音素。24行是决策树聚类数,656类。
为什么是656类呢?
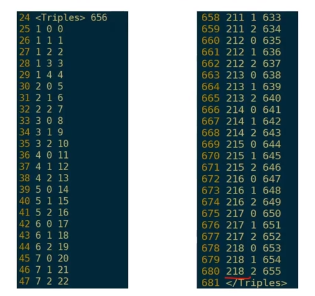
左图:25-29行是中间一列0-4(静音),剩下的都是0,1,2。
右图:第一列共218个音素,第二列状态,第三列决策树聚类数。
静音是5个状态,剩下都是3状态:217* 3+5=656
后面还有如下信息:

MFCC维度39:因为作了一阶二阶差分(13+13+13)
Weigh两个:说明是两个单高斯组成的GMM
均值39列,方差39列
GCONSTS的超参是什么呢?
W权重,后面是标准的高斯。取出了与x无关的项,提前计算好,这样后面就可以减少计算量。
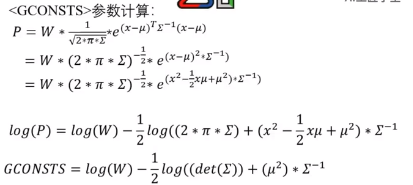
final.occs查看
show-transitions phones.txt final.mdl final.occs > final.occs.txt
对每个HMM的描述
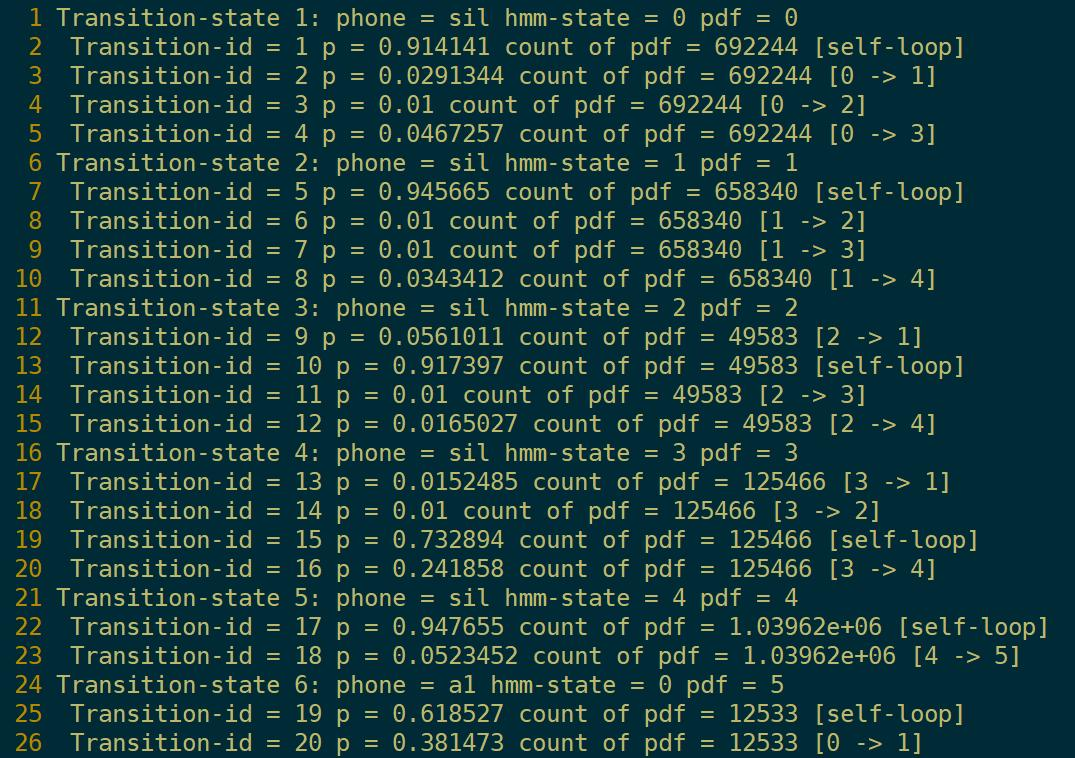
以前5行为例,描述状态1到1(自环),2,3,4的过程。
提特征按帧级别提的,
训练也是按帧级别训练的,
训练的结果是什么?
对齐信息查看
. ./path.sh
ali-to-phones
里面是每个phone的对齐信息
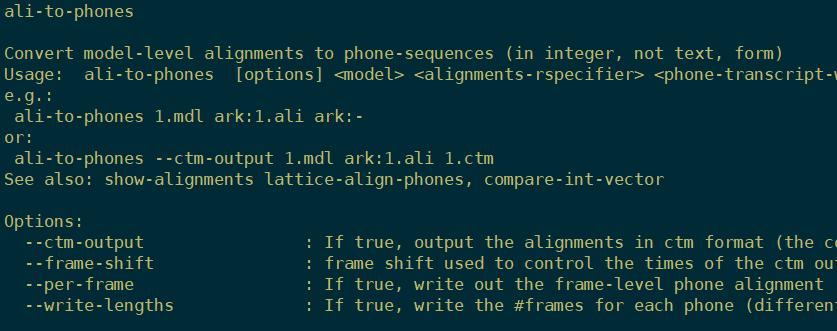
每个phone-id对应的音素是什么?
cd exp/mono
gunzip -c ali.1.gz | ali-to-phones --per-frame=true final.mdl ark:- ark,t:- | ../../utils/int2sym.pl -f 2- phones.txt
每帧特征对应的音素,
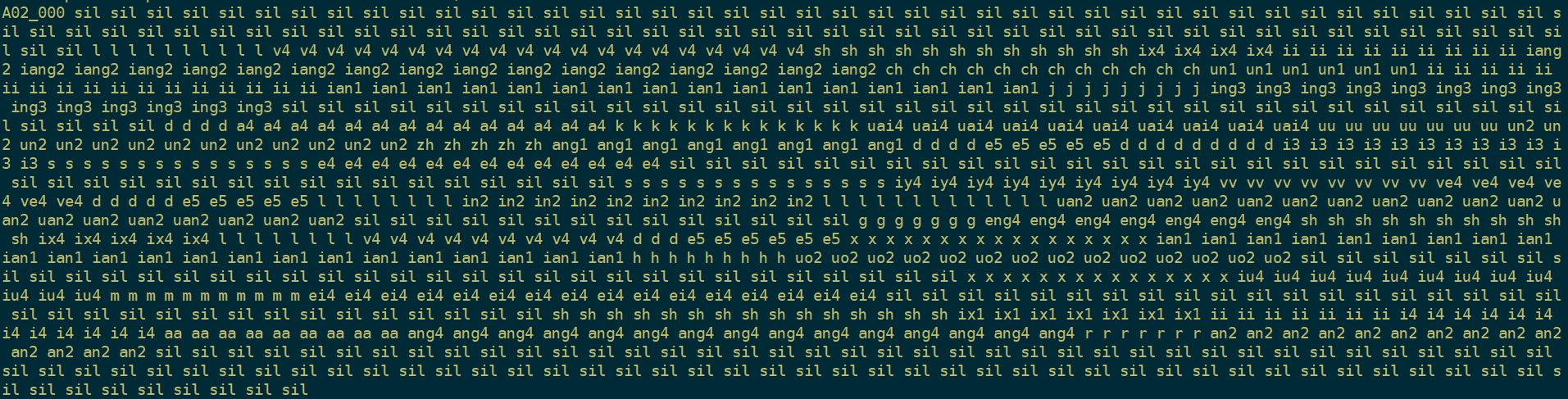
每个音素持续的时间是多久?
gunzip -c ali.1.gz | ali-to-phones --ctm-output=true final.mdl ark:- -| ../../utils/int2sym.pl -f 5 phones.txt
以A02_000为例:
文本内容:
绿 是 阳春 烟 景 大块 文章 的 底色 四月 的 林 峦 更是 绿 得 鲜活 秀媚 诗意 盎然
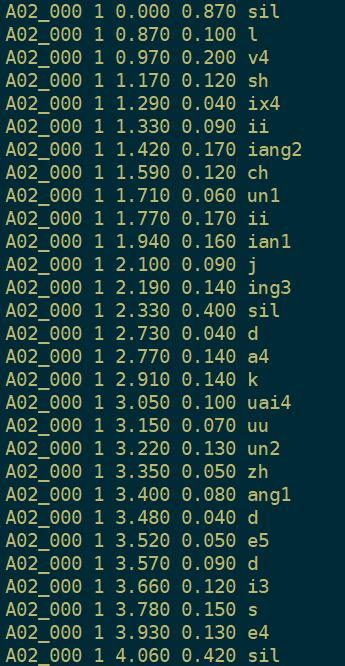
比如:前0.87s都是静音段,绿这个字lv4,从0.87s到0.1s,持续了0.1+0.2s=0.3s。可以用音频播放软件看看对的准不准。
网格信息查看
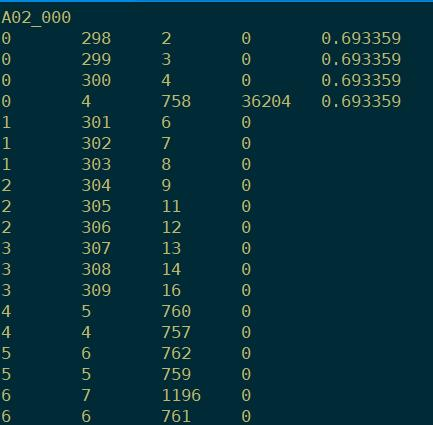
cd exp/mono
gunzip fsts.1.gz
fstcopy ark:fsts.1 ark,t:fsts.1.txt
存的词、字、音素、状态之间的映射关系,跳转关系
决策树
cd exp/mono
tree-info tree
里面有三行信息:

context-width:单音素模型就是1,三音素就是3
central-position:单音素就是0,三音素就是1(0,1,2,看到1就是中间位置)
画出决策树:
cd exp/mono
draw-tree phones.txt tree | dot -Gsize=8,10.5 -Tps | ps2pdf - tree.pdf
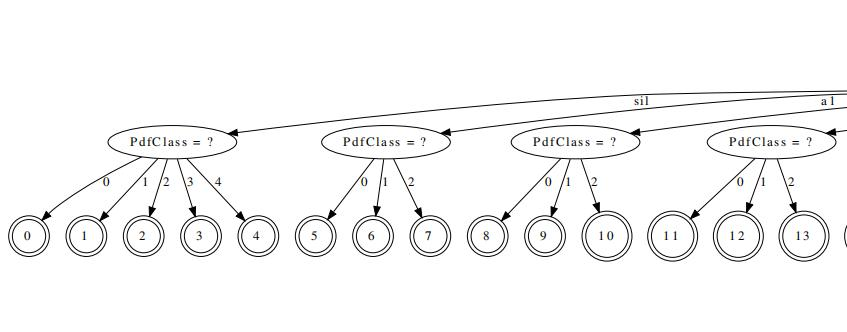
静音的HMM有5个状态,其他都是3个。
log分析:
用于检查错误
init.log:模型初始化时产生的
compile.log:fst时产生的
align.log:对齐时产生的
这样,就完成了下图流程中的第1,2,3步。
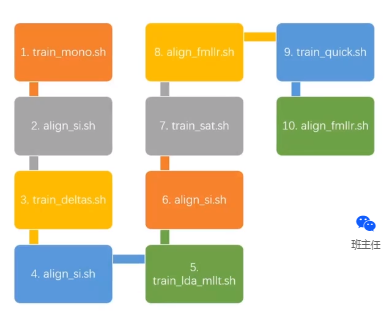
同样的方法,进行第4步:
训练aligh_si.sh
steps/align_si.sh --boost-silence 1.25 --nj 10 --cmd "run.pl"
data/mfcc/train data/lang exp/mono exp/mono_ali
此时:

查看mono_ali.sh生成内容:
cd mono_ali
gunzip -c ali.1.gz | ali-to-phones --ctm-output=true final.mdl
ark:- -| ../../utils/int2sym.pl -f 5 phones.txt
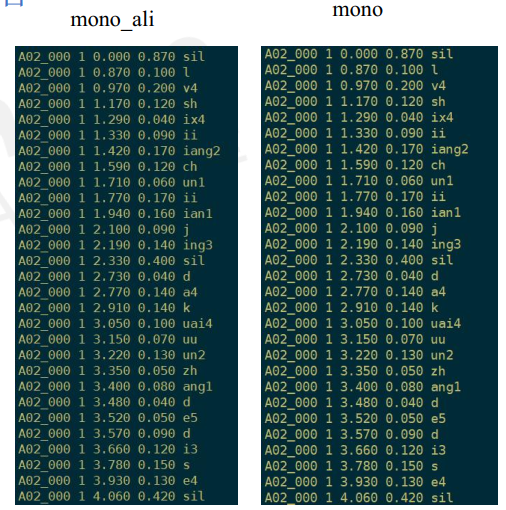
对齐信息和之前一样,说明单音素模型迭代没有效果,就这样了,需要新的算法来提升模型对齐能力。
GMM训练-对比mono_ali、 tri4b_ali对齐信息
A02_000文本:
绿 是 阳春 烟 景 大块 文章 的 底色 四月 的 林 峦 更
mono tri4b 是 绿 得 鲜活 秀媚 诗意 盎然
mono_ali: sox A2_0.wav part.wav trim 0.87 0.3
tri4b_ali : sox A2_0.wav part.wav trim 0.86 0.29
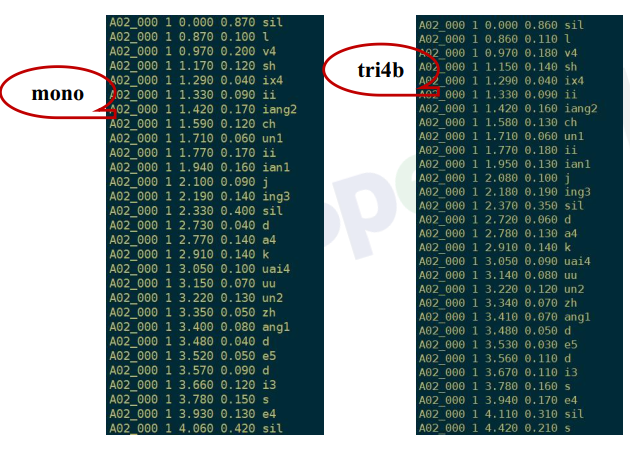
此时对齐的时间不一样了。








![[附源码]计算机毕业设计酒店物联网平台系统Springboot程序](https://img-blog.csdnimg.cn/30b74a78aced4c44af21865dc0a7ce0a.png)