| htmlq能够对 HTML 数据进行 sed 或 grep 操作。我们可以使用 htmlq 搜索、切片和过滤 HTML 数据。让我们看看如何在 Linux 或 Unix 上安装和使用这个方便的工具并处理 HTML 数据。 |
什么是htmlq?
htmlq类似于 jq,但用于 HTML。使用 CSS 选择器从 HTML 文件中提取部分内容。在 CSS 中,选择器用于定位我们想要设置样式的网页上的 HTML 元素。例如,我们可以使用此工具轻松提取图像或其他 URL。
安装htmlq
首先需要在系统中安装cargo然后使用cargo来安装htmlq:
[root@localhost ~]# yum -y install cargo [root@localhost ~]# cargo install htmlq
设置可执行的路径
确保将 $HOME/.cargo/bin 添加到 PATH 变量中,以便能够使用 export 命令运行已安装的二进制文件:
[root@localhost ~]# echo 'export PATH="$PATH:$HOME/.cargo/bin"' >> ~/.bash_profile [root@localhost ~]# . ~/.bash_profile
如何使用 htmlq 从 HTML 文件中提取内容?
下面是使用curl和htmlq的用法:
curl -s url | htmlq '#css-selector' curl -s url2 | htmlq '.css-selector' curl -s https://www.linuxprobe.com | htmlq --pretty '#content' | more
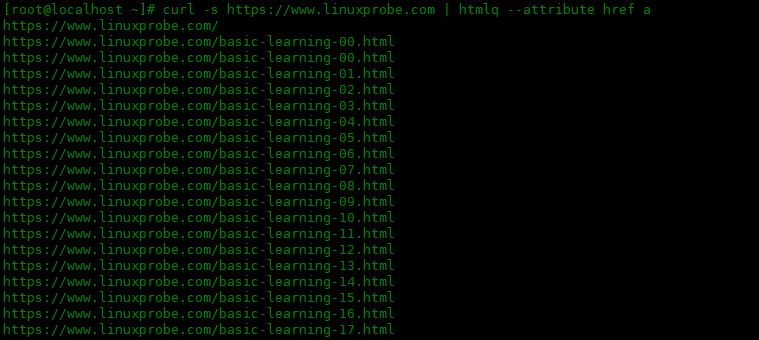
让我们找到页面中的所有链接。例如:
[root@localhost ~]# curl -s https://www.linuxprobe.com | htmlq --attribute href a
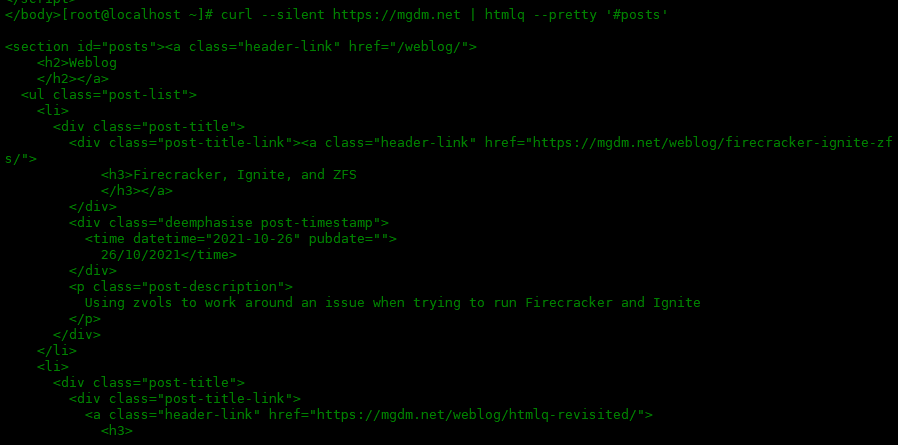
人性化显示HTML:
[root@localhost ~]# curl --silent https://mgdm.net | htmlq --pretty '#posts'
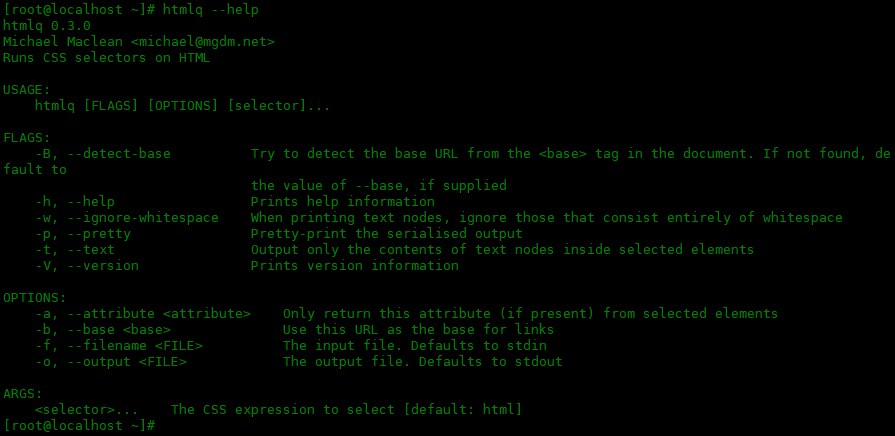
帮助手册
使用下面命令查看帮助页面:
[root@localhost ~]# htmlq --help
htmlq 0.3.0
Michael Maclean <michael@mgdm.net>
Runs CSS selectors on HTML
USAGE:
htmlq [FLAGS] [OPTIONS] [selector]...
FLAGS:
-B, --detect-base Try to detect the base URL from the <base> tag in the document. If not found, default to
the value of --base, if supplied
-h, --help Prints help information
-w, --ignore-whitespace When printing text nodes, ignore those that consist entirely of whitespace
-p, --pretty Pretty-print the serialised output
-t, --text Output only the contents of text nodes inside selected elements
-V, --version Prints version information
OPTIONS:
-a, --attribute <attribute> Only return this attribute (if present) from selected elements
-b, --base <base> Use this URL as the base for links
-f, --filename <FILE> The input file. Defaults to stdin
-o, --output <FILE> The output file. Defaults to stdout
ARGS:
<selector>... The CSS expression to select [default: html]
总结
htmlq能够对 HTML 数据进行 sed 或 grep 操作。我们可以使用 htmlq 搜索、切片和过滤 HTML 数据。
![[安装] HIVE搭建环境](https://img-blog.csdnimg.cn/img_convert/2adc1ff23d4870c9df29f488d7610241.png)
![[rsync] 基于rsync的同步](https://img-blog.csdnimg.cn/e4476499a5df447b80521f4cb78d1912.png)



![[附源码]计算机毕业设计快转二手品牌包在线交易系统Springboot程序](https://img-blog.csdnimg.cn/ac654804a52042d282dfd81f1dbdf63d.png)