一. 前言
一个网页会有很多数据是不需要经常变动的,比如说首页,变动频率低而访问量大,我们可以把它静态化,这样就不需要每次有请求都要查询数据库再返回,可以减少服务器压力
我们可以使用Django的模板渲染功能完成页面渲染
二. APSchedule/django-apschedule简介
APScheduler的全称是Advanced Python Scheduler。它是一个轻量级的 Python 定时任务调度框架。
APScheduler 支持三种调度任务:
- 固定时间间隔
- 固定时间点(日期)
- Linux 下的 Crontab命令。同时,它还支持异步执行、后台执行调度任务。
特点
1)可以动态添加任务
2)不依赖Linux的crontab系统定时
3)可以对添加的定时任务做持久保存
之前已经介绍过APScheduler的使用,下面介绍的是django-apscheduler的使用
三. 【django-apscheduler】使用
1.安装APScheduler
pip install django-apscheduler
2. 使用Django_apscheduler步骤
1.创建app
python manage.py startapp test
2. 注册使用
在settings.py中注册django-apscheduler和test
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django_apscheduler',
'apps.test' # 注意,我这里是在外层包了一个apps的文件夹,test为业务模块
]
3.在test文件夹中新建urls.py
在子模块apps/test/urls.py中添加如下代码
from django.urls import path
from apps.test import views
urlpatterns = [
]
4. 在项目总路由urls.py中添加test.urls
打开djangoproject中的urls.py,输入如下代码
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('apps.test.urls')),
]
5. 执行迁移
python manage.py makemigrations
python manage.py migrate
没有其他表结构的话不必运行 python manage.py makemigrations
会创建两张表:
- django_apscheduler_djangojob
- django_apscheduler_djangojobexecution
通过进入后台管理能方便管理定时任务。
django_apscheduler_djangojob 表保存注册的任务以及下次执行的时间

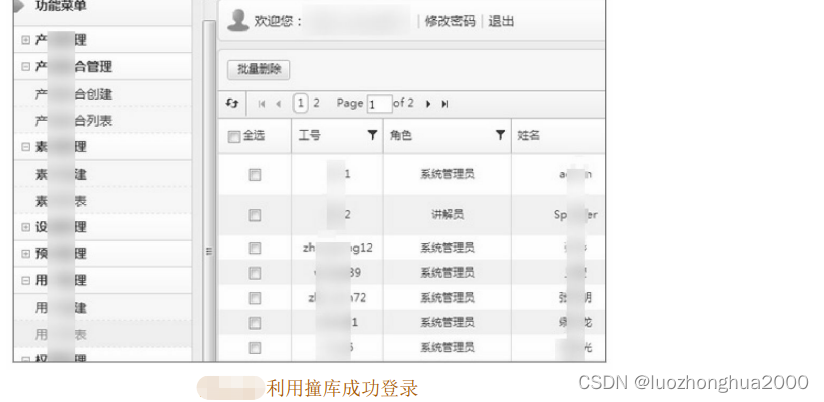
这里注意 status為executed是执行,missed 则是表示撞车的场景, 为避免这种场景需要在 周期的长度以及是否进行强制结束进行选择
6. 在test子应用中的urls.py中输入下面的代码
from django.shortcuts import render
# Create your views here.
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job,DjangoResultStoreMixin
# 实例化调度器
scheduler = BackgroundScheduler()
# 开启定时工作
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 设置定时任务,选择方式为interval,时间间隔为10s
# 另一种方式为每天固定时间执行任务,对应代码为:
# @register_job(scheduler, 'cron', day_of_week='mon-fri', hour='9', minute='30', second='10',id='task_time')
@register_job(scheduler, "interval", seconds=10,id='test_job', replace_existing=True) # replace_existing=解决第二次启动失败的问题
def my_job():
# 这里写你要执行的任务
pass
# register_events(scheduler) 最新的django_apscheduler已经不需要这一步
scheduler.start()
最好為job加上id ,不加也可以
注意: 需要加上replace_existing=True 否則會報以下錯誤,即id重複
raise ConflictingIdError(job.id)
apscheduler.jobstores.base.ConflictingIdError: 'Job identifier (index_html) conflicts with an existing job'
提示:也可以不寫在Django工程目录下的urls.py文件中(主urls.py)或者子應用的urls.py 中,百度說可以寫在view.py 中或其他隨便哪個文件中,但是我沒試成功過
7. 运行django項目
python manage.py runserver 8000
常见的三种调度参数
- date:希望在某个特定时间仅运行一次作业时使用
- interval:要以固定的时间间隔运行作业时使用
- cron:以crontab的方式运行定时任务
3. 示例
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job
scheduler = BackgroundScheduler()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 时间间隔3秒钟打印一次当前的时间
@register_job(scheduler, "interval", seconds=3, id='test_job')
def test_job():
print("我是apscheduler任务")
# per-execution monitoring, call register_events on your scheduler
register_events(scheduler)
scheduler.start()
print("Scheduler started!")
运行结果
Scheduler started!
我是apscheduler任务
我是apscheduler任务
...
APScheduler中两种调度器的区别及使用过程中要注意的问题
APScheduler中有很多种不同类型的调度器,BlockingScheduler与BackgroundScheduler是其中最常用的两种调度器。区别主要在于BlockingScheduler会阻塞主线程的运行,而BackgroundScheduler不会阻塞。所以,我们在不同的情况下,选择不同的调度器:
- BlockingScheduler: 调用start函数后会阻塞当前线程。当调度器是你应用中唯一要运行的东西时(如上例)使用
- BackgroundScheduler: 调用start后主线程不会阻塞。当你不运行任何其他框架时使用,并希望调度器在你应用的后台执行。
BlockingScheduler的示例
from apscheduler.schedulers.blocking import BlockingScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
sched = BlockingScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果
job 3s
job 3s
job 3s
...
可见,BlockingScheduler调用start函数后会阻塞当前线程,导致主程序中while循环不会被执行到。
BackgroundScheduler的例子
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果
main 1s
main 1s
main 1s
job 3s
main 1s
main 1s
main 1s
job 3s
...
可见,BackgroundScheduler调用start函数后并不会阻塞当前线程,所以可以继续执行主程序中while循环的逻辑。
通过这个输出,我们也可以发现,调用start函数后,job()并不会立即开始执行。而是等待3s后,才会被调度执行。
如何让job在start()后就开始运行
其实APScheduler并没有提供很好的方法来解决这个问题,但有一种最简单的方式,就是在调度器start之前,就运行一次job(),如下
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
job()
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
这样虽然没有绝对做到让job在start()后就开始运行,但也能做到不等待调度,而是刚开始就运行job
如果job执行时间过长会怎么样
如果执行job()的时间需要5s,但调度器配置为每隔3s就调用一下job(),会发生什么情况呢?我们写了如下例子
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
time.sleep(5)
if __name__=='__main__':
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)

可见,3s时间到达后,并不会“重新启动一个job线程”,而是会跳过该次调度,等到下一个周期(再等待3s),又重新调度job()。
为了能让多个job()同时运行,我们也可以配置调度器的参数max_instances,如下例,我们允许2个job()同时运行
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
time.sleep(5)
if __name__=='__main__':
job_defaults = { 'max_instances': 2 }
sched = BackgroundScheduler(timezone='MST', job_defaults=job_defaults)
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
我们可看到如下运行结果

每个job是怎么被调度的
通过上面的例子,我们发现,调度器是定时调度job()函数,来实现调度的。
那job()函数会被以进程的方式调度运行,还是以线程来运行呢?
为了弄清这个问题,我们写了如下程序:
from apscheduler.schedulers.background import BackgroundScheduler
import time,os,threading
def job():
print('job thread_id-{0}, process_id-{1}'.format(threading.get_ident(), os.getpid()))
time.sleep(50)
if __name__=='__main__':
job_defaults = { 'max_instances': 20 }
sched = BackgroundScheduler(timezone='MST', job_defaults=job_defaults)
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
我们可看到如下运行结果

可见,每个job()的进程ID都相同,但线程ID不同。所以,job()最终是以线程的方式被调度执行
BlockingScheduler定时任务及其他方式的实现
#BlockingScheduler定时任务
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
首先看看周一到周五定时执行任务
# 输出时间
def job():
print(datetime.now().strtime("%Y-%m-%d %H:%M:%S"))
# BlockingScheduler
scheduler = BlockingScheduler()
scheduler.add_job(job, "cron", day_of_week="1-5", hour=6, minute=30)
schduler.start()
scheduler.add_job(job, 'cron', hour=1, minute=5)
hour =19 , minute =23 这里表示每天的19:23 分执行任务
hour ='19', minute ='23' 这里可以填写数字,也可以填写字符串
hour ='19-21', minute= '23' 表示 19:23、 20:23、 21:23 各执行一次任务
#每300秒执行一次
scheduler .add_job(job, 'interval', seconds=300)
#在1月,3月,5月,7-9月,每天的下午2点,每一分钟执行一次任务
scheduler .add_job(func=job, trigger='cron', month='1,3,5,7-9', day='*', hour='14', minute='*')
# 当前任务会在 6、7、8、11、12 月的第三个周五的 0、1、2、3 点执行
scheduler .add_job(job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
#从开始时间到结束时间,每隔俩小时运行一次
scheduler .add_job(job, 'interval', hours=2, start_date='2018-01-10 09:30:00', end_date='2018-06-15 11:00:00')
#自制定时器
from datetime import datetime
import time
# 每n秒执行一次
def timer(n):
while True:
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
time.sleep(n)
timer(5)
BackgroundScheduler定时任务及其他方式的实现
启动异步定时任务
import time
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job
try:
# 实例化调度器
scheduler = BackgroundScheduler()
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 'cron'方式循环,周一到周五,每天9:30:10执行,id为工作ID作为标记
# ('scheduler',"interval", seconds=1) #用interval方式循环,每一秒执行一次
@register_job(scheduler, 'cron', day_of_week='mon-fri', hour='9', minute='30', second='10',id='task_time')
def test_job():
t_now = time.localtime()
print(t_now)
# 监控任务
register_events(scheduler)
# 调度器开始
scheduler.start()
except Exception as e:
print(e)
# 报错则调度器停止执行
scheduler.shutdown()
参考链接:https://www.cnblogs.com/guojie-guojie/p/16330165.html
以上就是python- 定时任务框架【APScheduler】基本使用介绍,希望对你有所帮助!