字符串的哈希值是什么?
在C++,Java等编程语言中,有一种hashmap的数据结构,存储一对key / value,分别是两种对象。
为了加快存取的速度,键值key对象会被转换成一个hash值,一个整数。一般来讲,可以将任何对象转化成一个固定整数值。
比如,key和value都是字符串,那就会将key的字符串转换成整数值,作为索引,这样查找hashmap数据结构就会更快,而不用使用其他遍历方法。
那这里说的将字符串转化或简化成一个数字的方法,就是计算一个字符串的哈希值。
期望的要求如下:
1,要保证同样的字符串,每次生成的都是同一个数值。
2,如果字符串里的字符顺序不同,生成的数值是不同的。
3,不同的字符串产生的哈希值要尽量不要重复,保证其几率非常小。
Java里的string类( java.util.String),有一个hashCode方法,就是用来生成字符串的哈希值(hash code),源码如下:
/**
* Returns a hash code for this string. The hash code for a
* <code>String</code> object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using <code>int</code> arithmetic, where <code>s[i]</code> is the
* <i>i</i>th character of the string, <code>n</code> is the length of
* the string, and <code>^</code> indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
int len = count;
if (h == 0 && len > 0) {
int off = offset;
char val[] = value;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}
根据上面代码,得出Java里计算字符串的哈希值或散列值(hash code)的方法是:
S0 * 31 ^ (n-1) + S1 * 31 ^ (n-2) + .... + S(n-2) * 31 + S(n-1)
这里,n表示的是字符串长度,S0表示字符串第一个字符的ASCII值,S(n-1)就是最后一个字符的ASCII值。“^”是指数运算符(exponential operand)。
举例来说,如果字符串是“Hi”的话:
HashCode = 'H'*31^(2-1) + 'i'*31^(2-2) = 'H'*31 + 'i' = 72 * 31 + 105 * 1 = 2232 + 105 = 2337
如果是空字符串,则哈希值为0。
另外,一些其他的计算散列值(哈希值)的散列函数会以某个大数(如一个大素数,也有以2^n的)为模数的。这就避免了溢出,并使函数返回的数值范围保持在指定的范围内。但这也意味着无限范围的输入值会从有限的可能值(即[0,modulus])中得到一个哈希值,因此会出现哈希碰撞的问题。
举例来说,代码类似下面,这里是用的权重乘数是29:
使用迭代法计算哈希值,从第一个字符开始计算,多一个字符,前面的哈希值乘以权重数再加上新字符的值:
public int hash(String x){
int hashcode=0;
int MOD=10007;
int shift=29;
for(int i=0;i<x.length();i++){
hashcode=(shift*hashcode)+x.charAt(i);
}
return hashcode;
}
在哈希值计算时取模:
public int hash(String x){
int hashcode=0;
int MOD=10007;
int shift=29;
for(int i=0;i<x.length();i++){
hashcode=((shift*hashcode)%MOD+x.charAt(i))%MOD;
}
return hashcode;
}
为什么计算使用31作为基数,用字符偏移作为指数,一起做成字符位置的权重,和字符的ASCII值相乘?
Java里string的hashCode值计算,使用31作为乘数的原因是什么呢。(在计算时,要乘以或左移一个magic number。进行的是multiply或shift操作)
首先,是因为31不是偶数,如果你使用一个偶数,那里面就有2。计算机里一个数值乘以2,就相当于左移一位,那计算乘法时结果溢出的话,就浪费了一位有效信息。
第二,31是一个质数,按照传统一般都会选个质数。假如选择9进制,那100的话就是121,如果是3进制的话,就是10201,就是将121展开(1)(02)(01),9进制和3进制的表示法是有关联的,就像16进制和8进制。选择不同的乘数,就和这个进制表示法类似的,如果不是质数,就会引发一些表达上的不纯粹。
第三,使用31还可以带来计算的方便,可以将乘法转换为位移和减法操作:31 * i =(i << 5) - i; 在很多环境下, 会自动使用这种优化。
第四,这个值不是很大,一般长度的单词,计算的话,不会溢出,而导致信息丢失。也不是太小,太小的话,大多数字符串的哈希值的范围会较集中,而不是分布在更大的整数区间内。
第五,经过碰撞测试,能够较好符合要求。即根据大量的单词测试,发生不同字符串出现相同哈希值的情况,概率很低。
解释一下,为什么选择一个质数(prime number)作为乘数。
因为一般我们使用哈希值,都是作为一个索引(slot)使用,用在hashtable中,而这个索引通常是有范围限定的,比如索引范围是 0 ~ N-1,也就是N个可用索引位置。
那使用的计算公式可以理解成hash(X) % N,也就是对X求出一个哈希值,然后对N取余,求得的余数就是索引位置。
N就是我们限定了哈希值的有效范围,通过取余来实现。
那如果我们使用的乘数不是质数,那就有可能和N有公约数(share divisor),这样取余的话,公约数消掉以后,就改变了取余结果的范围。
那哈希值的计算结果就不能随机的散落在 0 ~ (N-1)的范围内,这不符合我们的使用需求和期望,我们希望求得的哈希值,在整个有效范围内,是固定的、不易重复的,所以更希望在整个值域内是随机分布的,有公约数会影响所求结果的分布范围,显然不好。
虽然字符串的散列值计算时,最后一个字符乘以1,而不是用这个乘数,但一个字符对结果的影响是有限的,尤其是N比较大时,对最终取值的范围影响有限。
另外一般来说 ,我们N的取值是2的n次方,取余操作可以直接转换为移位操作。这样一个奇数就不会和N有公约数,但通用一些的话,还是用质数比较好。
在很多的处理器上,执行乘以31的操作会的代价较小,比如在ARM上,只需一条指令:
RSB r1, r0, r0, ASL #5 ; r1 := - r0 + (r0<<5)
大多数其他处理器都需要单独的移位和减法指令。然而,如果你的乘法器很慢,这就有很大帮助。现代的处理器往往有快速的乘法器,所以有时没有太大的区别。
测试结果对比
在JDK的bug base里的JDK-4045622条目中的说明:
Bug ID: JDK-4045622 java.lang.String.hashCode spec incorrectly describes the hash algorithm
首先,最开始的hashcode版本是:
public int hashCode() {
int h = 0;
int off = offset;
char val[] = value;
int len = count;
if (len < 16) {
for (int i = len ; i > 0; i--) {
h = (h * 37) + val[off++];
}
} else {
// only sample some characters
int skip = len / 8;
for (int i = len ; i > 0; i -= skip, off += skip) {
h = (h * 39) + val[off];
}
}
return h;
}
这个哈希计算函数,在字符串较长时,做了一个过滤,不是每个字符都参与计算,而是间隔几个,这样的目的应该是加快计算速度。
这里说明了一个对比测试结果,那java的使用37作为乘数的函数和其他的相比较:
使用的数据类型,
1,Merriam-Webster's 2nd Int'l Unabridged Dictionary里的所有单词和短语(words and phrases),大约311, 141隔字符串,平均长度为10.
2,这些文件系统路径下用到的字符串,/bin/, /usr/bin/, /usr/lib/, /usr/ucb/ 和 /usr/openwin/bin/*,66304个字符串,平均长度21个字符。
3,使用web-crawler网络爬虫收集到的URL地址列表,抓取几个小时,得到28373个字符串,平均长度49个字符。
不同内容使用不同的哈希计算函数对比的性能结果, 以从hashtable访问元素的性能来比较:(performance metric)
表中显示的性能指标是哈希表中所有元素的 "average chain size"(即查找一个元素所需的键数比较的预期值)。
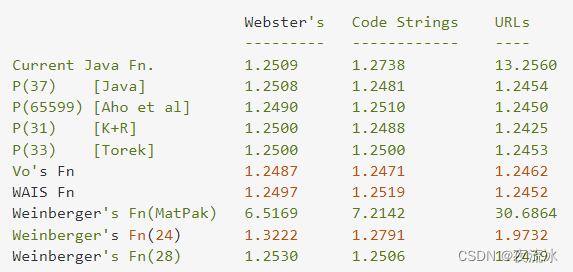
从这个对比结果来看,用31生成的hashtable,结果还是可以的。
这不是一个伟大的哈希算法,但已经足够好了。
使用其他的质数作为乘数的话
使用其他的质数,也可以将乘法转化为更快的移位和加减操作。
比如:
x*37 = ((x+8*x)*4)+x ( y = x+8*x, 4*y + x = x*37)
x*73 = ((x+8*x)*8)+x ( y = x+8*x, 8*y + x = x*73)
先计算括号以内的公式,左移三位,然后加上x,再左移两位或三位,然后再加x。
参考:
https://www.youtube.com/watch?v=6JoXp1e8jAQ
java - How to calculate the hash code of a string by hand? - Stack Overflow
How String Hashcode value is calculated? - GeeksforGeeks
How the Java String hash function works (2)
Why does Java's hashCode() in String use 31 as a multiplier? - Stack Overflow
编程参考 - 如何计算字符串的哈希值
![[附源码]Python计算机毕业设计SSM计算机学院科研信息管理系统(程序+LW)](https://img-blog.csdnimg.cn/fa8b5ff81ffe4e58ae14a28eaac49cdf.png)
![[附源码]计算机毕业设计JAVA志愿者管理系统论文2022](https://img-blog.csdnimg.cn/ef3a8405f511407ba1608a3549e42f61.png)
![[附源码]Python计算机毕业设计SSM基于中职学校的校医务室管理系统(程序+LW)](https://img-blog.csdnimg.cn/2a97b9e6b57b4da2a5c128b0fe47d7fc.png)