文章目录
- 导读
- Embedding的维度问题
- Embedding的输入输出
- 比较容易踩的坑
- input_shape与input_length的对应关系
- built属性
导读
这是填曲线拟合第一篇的坑,有关Embedding层的问题。
Embedding的维度问题
首先是上次我们提到的Embedding层,他确实能够做到将数据一一对应着输出的功能。但是实际上,在曲线拟合中还是存在一个严重的问题:降维问题。
在自然语言中,Embedding层的目的就是为了把高维的、稀疏的矩阵,变为低维的、稠密的矩阵。
Embedding Layer可以被认为是one-hot编码和降维的替代方法。
——摘自Understanding Embedding Layer in Keras
这也就意味着Embedding能够在我们拟合的过程中将已经整成维度为
(
TRAIN
_
SIZE
,
COL
_
SIZE
,
ROW
_
SIZE
)
(\text{TRAIN}\_\text{SIZE}, \text{COL}\_\text{SIZE}, \text{ROW}\_\text{SIZE})
(TRAIN_SIZE,COL_SIZE,ROW_SIZE)的数据集,直接降低一个维度,从而直接导致在训练的过程中丢失一个维度,进而造成曲线峰值不会变化的bug。
只是我们所使用的案例刚好采用的是峰值不会变化的三角函数曲线,如果产生这个bug大概就是这种样子:
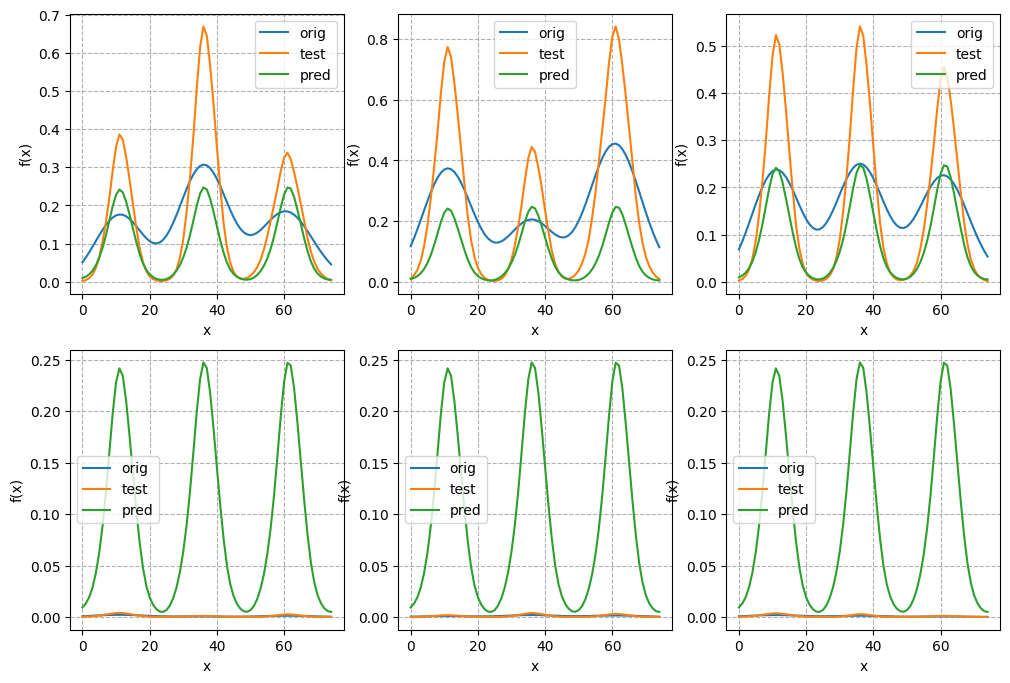
可以看到无论测试集长什么花样,预测值都是不会变动的。这就完全不正确了。
Embedding的输入输出
我们不妨再看看官方GitHub中会不会有什么提示。
P.S.:GitHub这里有个比较方便的就是,在最末尾加上【#L382-L890】,就会把这个代码文件中第 382 382 382行到第 890 890 890行中间的所有代码高亮显示。这个链接点进去就是
LSTM整个类给高亮显示的链接。
我们先按照官方教程构建一个简单的Embedding Layer:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim = 1000, output_dim = 64, input_length = 10)
])
model.summary()
这个Embedding Layer给了一个input_dim作为输入维度,output_dim作为输出维度,input_length作为输出长度,这也就为输入的数据基本确定了一个样本。
其中,input_dim本身实际上是一个限制,也就是说输入最多不能超过
999
999
999,如果是自然语言的话那就是句子长度最高不能超过
999
999
999个字词。
在官方GitHub源码中也有这方面的逻辑:
if "input_shape" not in kwargs:
if input_length:
kwargs["input_shape"] = (input_length,)
else:
kwargs["input_shape"] = (None,)
也就是说,当input_shape没有指定的时候,就默认按照input_length创建input_shape。如果连input_length也没有的话,那就是规定这一个维度没东西。举个例子,我们所构建的这个网络将形成输入为
(
10
,
)
(10,)
(10,)的数据。同时由于转型为Tensor的过程中又会再增加一个维度,也就构成了
(
None
,
10
,
)
(\text{None},10,)
(None,10,)的输入。
None
\text{None}
None是
batch
_
size
\text{batch}\_\text{size}
batch_size的一种取值,取
None
\text{None}
None表示每次开始使用之前可以根据当前数据量自定义,但每次开始使用之后必须一直使用到测试结束都不能有变化。
同样的,输入变成了
(
None
,
10
,
)
(\text{None},10,)
(None,10,),那么输出也就是在后面再加上一个output_dim,也就是
(
None
,
10
,
64
)
(\text{None},10,64)
(None,10,64)。
于是,我们尝试一下:
import numpy as np
input_array = np.random.randint(1000, size=(32, 10))
model.compile(optimizer = 'rmsprop', loss = 'mse')
output_array = model.predict(input_array)
首先,我们使用numpy的random库随机生成一组数据,这组数据是
0
∼
1000
0\sim1000
0∼1000之间的随机数,一共有
32
32
32行、
10
10
10列。
然后确定模型的优化器与需要优化的损失函数,这里选取均方差mean squard error作为损失函数,也就是我们所熟悉的MSE
l ( x ) = ∑ i = 1 N ( x i − x ˉ ) 2 N l(x)=\frac{\sum_{i=1}^N(x_i-\bar{x})^2}{N} l(x)=N∑i=1N(xi−xˉ)2
优化器则是RMSprop,特点就是类似强化学习中DDPG里的软更新一样,是从一个随机起始位置逐步逼近目标,然后每次更新都只接收更新的一部分,而不是彻底覆盖。也就是
θ ′ = τ θ + ( 1 − τ ) θ ′ \theta'=\tau\theta+(1-\tau)\theta' θ′=τθ+(1−τ)θ′
从而使得 f ( x ) f(x) f(x)能够产生下列变化
f 0 ( x ) = g 0 ( x ) f 1 ( x ) = g 0 ( x ) + g 1 ( x ) f 2 ( x ) = g 0 ( x ) + g 1 ( x ) + g 2 ( x ) … \begin{matrix}f_0(x)&=&g_0(x)\\f_1(x)&=&g_0(x)&+&g_1(x)\\f_2(x)&=&g_0(x)&+&g_1(x)&+&g_2(x)\\\ldots\end{matrix} f0(x)f1(x)f2(x)…===g0(x)g0(x)g0(x)++g1(x)g1(x)+g2(x)
最终,我们的output_array最终输出的shape也是
(
32
,
10
,
64
)
(32,10,64)
(32,10,64)。
所以,对于Embedding层,输入设置了input_length,输入数据的时候只需要保证第
2
2
2个维度为input_length,最终输出的时候就会输出
(
batch
_
size
,
input
_
length
,
output
_
dim
)
(\text{batch}\_\text{size},\text{input}\_\text{length},\text{output}\_\text{dim})
(batch_size,input_length,output_dim)。
在官方GitHub源码中当然也有这个逻辑:
@tf_utils.shape_type_conversion
def compute_output_shape(self, input_shape):
if self.input_length is None:
return input_shape + (self.output_dim,)
else:
# input_length can be tuple if input is 3D or higher
if isinstance(self.input_length, (list, tuple)):
in_lens = list(self.input_length)
else:
in_lens = [self.input_length]
if len(in_lens) != len(input_shape) - 1:
raise ValueError(
f'"input_length" is {self.input_length}, but received '
f"input has shape {input_shape}"
)
else:
for i, (s1, s2) in enumerate(zip(in_lens, input_shape[1:])):
if s1 is not None and s2 is not None and s1 != s2:
raise ValueError(
f'"input_length" is {self.input_length}, but '
f"received input has shape {input_shape}"
)
elif s1 is None:
in_lens[i] = s2
return (input_shape[0],) + tuple(in_lens) + (self.output_dim,)
这段代码包含以下几个关键分支:
- 当
input_length不存在的时候,就把output_dim拼在input_shape后面,形成一个三元组 - 当
input_length存在的时候,需要保证input_length是比input_shape少一个维度,从而保证自定义的input_shape与input_length能够有可能存在对应关系。 - 然后在
input_shape中,需要检查input_length与input_shape中除开第一个元素以外的元素是否存在对应关系,如果对应不上,那就需要返回去重新检查;如果input_length为空,那么就是按照input_shape去完善input_length。 - 最后就是元组拼接,首先是
input_shape的第一个元素,也就是刚刚所说的 None \text{None} None或者指定的 batch _ size \text{batch}\_\text{size} batch_size,再就是input_length,最后是output_dim,最终输出也就是 ( None , 10 , 64 ) (\text{None},10,64) (None,10,64)。而如果我们不管这个 None \text{None} None,就只在最后输入数据的时候给入一个确定维度的数据,这个时候神经网络也会自己进行适配。
比较容易踩的坑
input_shape与input_length的对应关系
而如果我指定input_shape呢?这个时候如果没有阅读源码的话反而很容易乱掉。
一般情况下,在构建Tensor的时候,往往需要三维数据,这个时候极大可能就会采用三维数据作为输入:input_shape=(None,10,64)。
这个时候就会因为上面的一系列操作,最终输出 ( None , None , None , 10 , 64 ) (\text{None},\text{None},\text{None},10,64) (None,None,None,10,64)。
反而不如不指定input_shape了。
built属性
在官方GitHub源码中有这么一段:
@tf_utils.shape_type_conversion
def build(self, input_shape=None):
self.embeddings = self.add_weight(
shape=(self.input_dim, self.output_dim),
initializer=self.embeddings_initializer,
name="embeddings",
regularizer=self.embeddings_regularizer,
constraint=self.embeddings_constraint,
experimental_autocast=False,
)
self.built = True
最后一句话有个self.built = True,也就是说调用这个,整个模型就是【已构建】的状态,不需要再显式调用Sequential的build方法保证模型的构建完成。
当然,并不是所有的layer都有这个属性。目前已知的就包括LSTM、GRU等模型,都是不会自动调用build方法,而是需要自行显式调用。
显式调用的目的也很明确,就是为了给网络一个相当确切的输入。因为包括LSTM、GRU等模型的参数只有一个最关键的units,而不包含input_length、input_shape等属性,所以需要额外使用build方法显式声明:
import tensorflow as tf
HIDDEN_OUTPUT = int(SEQUE_SIZE / 10) + 1
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(units = 10, activation = 'relu'),
])
model.compile(optimizer = 'adam', loss = tf.keras.losses.mean_squared_error)
model.build(input_shape = (1000, 64))
model.summary()
其中,build方法中所包含的input_shape属性需要使用
(
input
_
dim
,
output
_
dim
)
(\text{input}\_\text{dim}, \text{output}\_\text{dim})
(input_dim,output_dim)输入。
同样的,input_dim并不重要。这里不是说输入的维度不重要,而是input_shape本身第一个值就是不重要,可以用
None
\text{None}
None代替,也就是input_shape = (None, 64)。