文章目录
- 一、使用场景
- 二、对比有锁优势
- 三、无锁队列实现方式
- 四、循环队列实现
- 1)数据结构设计
- 3)代码实现
- 4)性能测试
- 5)总结
一、使用场景
无锁队列主要适用于高并发场景或者对性能要求较高的场景,主要使用场景有如下几个方面:
- 并发任务处理:当有多个线程或者进程需要并发地向队列中添加或者取出数据时,无锁队列可以提供高吞吐量和低延迟的性能。
- 生产者-消费者模型:在生产者-消费者模型中,生产者将数据放入队列,消费者从队列中取出数据进行处理。无锁队列可以提供高效的数据交换机制,使得生产者和消费者之间能够实现高并发的数据交互。
- 事件驱动系统:在事件驱动的系统中,事件源会将事件放入队列,事件处理器从队列中取出事件并进行处理。无锁队列能够提供高效的事件处理机制,使得系统能够快速响应事件。
- 高性能网络通信:在网络通信中,消息的发送和接收往往需要经过队列进行中转。无锁队列可以提供高吞吐量和低延迟的消息传递机制,使得网络通信能够更高效地进行。
以上场景对于有锁队列和无锁队列都可以使用的,但还如果对性能要求比较高,比如需要达到上万ops,就可以考虑优先使用无锁队列。相反如果性能达不到这么高使用有锁队列和无锁队列性能差别并不大,但是有锁队列实现会更加简单。
二、对比有锁优势
- 并发性能更好:无锁队列通过使用原子操作和CAS(比较并交换)等技术,在并发访问时不需要使用锁,避免了锁竞争和上下文切换的开销,从而能够提供更高的并发性能。
- 延迟更低:由于无锁队列不需要等待锁的释放,可以避免线程阻塞,从而减少了任务等待的时间,提高了任务的响应速度和系统的吞吐量。
- 无死锁风险:有锁队列在并发环境中容易出现死锁问题,而无锁队列没有锁的概念,因此不会出现死锁的风险。
三、无锁队列实现方式
- 链表
- 数组(循环队列—ringBuff)
- 数组 + 链表
本文采用的是循环队列的实现方式。
四、循环队列实现
1)数据结构设计
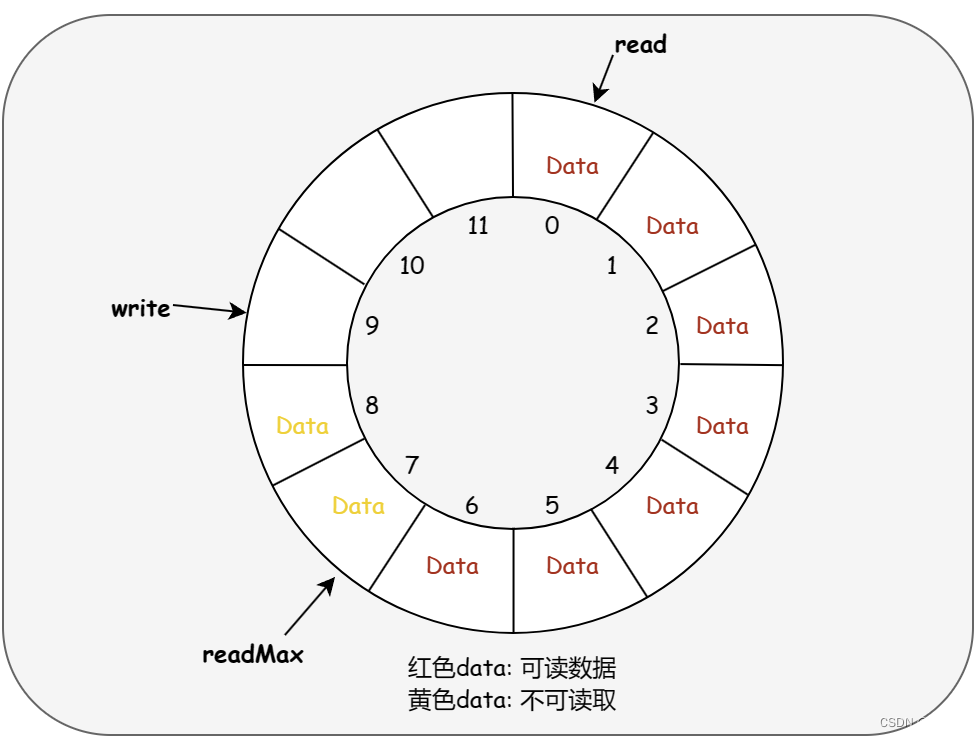
队列维护三个指针,通过这三个指针来实现数据的压入、弹出操作:
- read:指向对头第一个元素, pop位置
- readMax:指向队尾的下一个元素位置
- write:指向当前可以向队列写入数据的位置,push位置
队列中的数据分为两种:
- 写入中(黄色Data):该数据当前还没有完全写入队列,对读不可见,不能读取,位于队列尾部;
- 已写入(红色Data):该数据已经写入完成,可以直接读取;
队列判空条件:read == readMax
队列已满条件:write + 1 == read
readMax到write之间的数据这样设计可以保证并发时未完全插入的数据不会被消费者线程看到。
3)代码实现
github:https://github.com/yangziju/freeLockQueue
4)性能测试
以同样的数据结构(环形队列)实现一个有锁的队列,进行对比测试,两者的区别就在于一个加锁一个无锁,消费者在取出数据后会进行1000 次 empty loop。
测试环境:
系统:Debian x86_64虚拟机,4核4G
测试模型1:
- Producer:1
- Consumer:1
- 数据量:一千万
- 消费者线empty loop:0
测试结果如下:

测试模型2:
- Producer:1
- Consumer:1
- 数据量:一千万
- 消费者线empty loop:1000
测试结果如下:

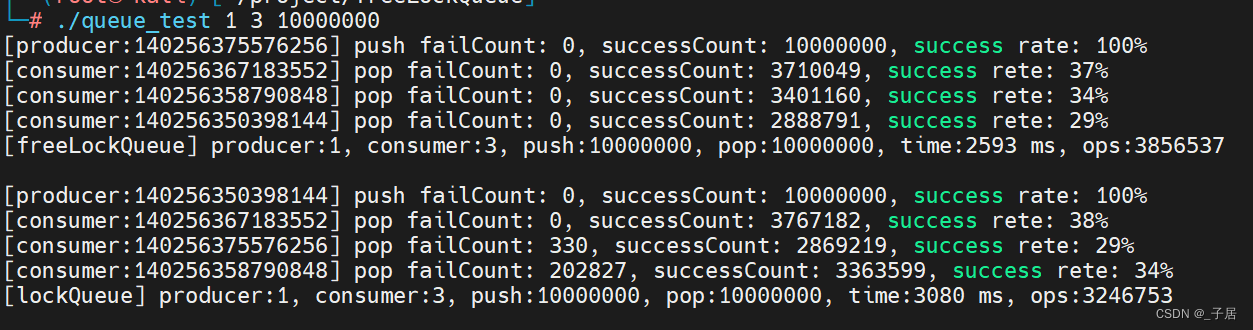
测试模型3:
- Producer:1
- Consumer:3
- 数据量:一千万
- 消费者线empty loop:1000
测试结果如下:
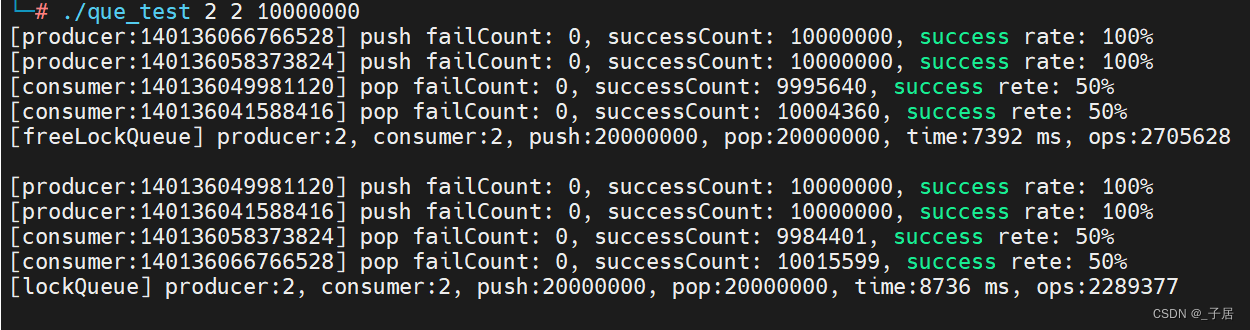
测试模型4:
- Producer:3
- Consumer:1
- 数据量:一千万
- 消费者线empty loop:1000
测试结果如下:
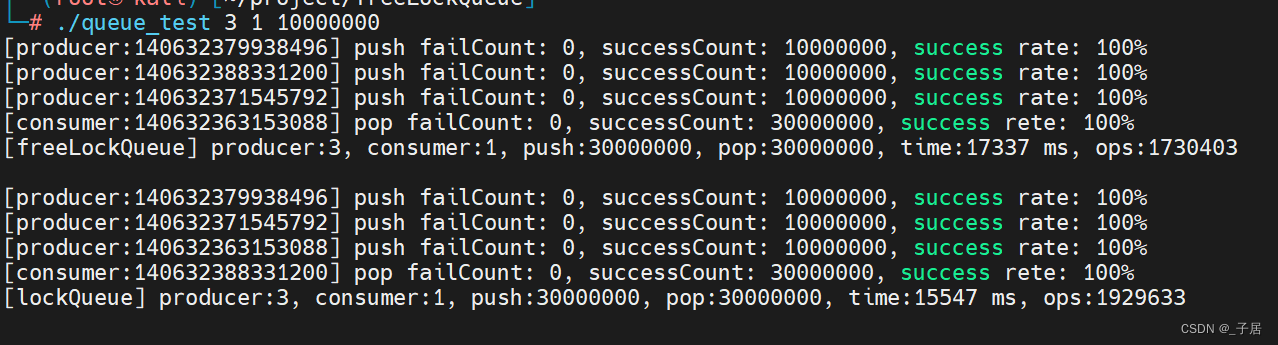
测试模型5:
- Producer:2
- Consumer:2
- 数据量:一千万
- 消费者线empty loop:1000
测试结果如下:
5)总结
测试结果分析可以知道:
- 多写一读:无锁队列性能不入有锁队列。
- 一写多读:随着读(消费者)线程数量增加,无锁和有锁队列性能都会下降,最后无锁队列性能还是不入有锁队列。
- 消费者线程处理数据越久,无锁队列性能更优。