目录
联邦聚合算法对比(FedAvg、FedProx、SCAFFOLD)
解决问题
FedAvg
FedProx
SCAFFOLD
实验结果
联邦聚合算法对比(FedAvg、FedProx、SCAFFOLD)
论文链接:
FedAvg:Communication-Efficient Learning of Deep Networks
from Decentralized Data
FedProx: Federated Optimization in Heterogeneous Networks
SCAFFOLD: SCAFFOLD: Stochastic Controlled Averaging for Federated Learning
解决问题
联邦学习存在四个典型问题:
- server端以及device端的网络连接是有限的,在任何时刻,可能都只有部分节点参与训练。
- 数据是massively分布的,所以参与联邦学习的devices非常多
- 数据是异构的
- 数据分布是不均匀的
这几篇论文的重点都试图在解决上面四个问题,研究的重心是,如何在2、3、4的条件下, 提出一种communication rounds最少的方法。
FedAvg
假设一共有 K K K个clients,每个clients都有固定容量的数据。在每轮训练开始的时候,随机 C C C( C C C 表示占比)个clients参与训练。即考虑有clients掉线的实际情况。

其中 f i ( w ) = ℓ ( x i , y i ; w ) f_i(w) = \ell(x_i, y_i;w) fi(w)=ℓ(xi,yi;w) 表示clients端的损失函数。
FedAvg算法就是在clients端进行多轮训练,然后server端对各个clients端的 w根据数据量占比进行聚合。算法流程如下:

FedProx
FedProx对clients端的Loss加了修正项,使得模型效果更好收敛更快:

其中clients端的Loss为:

所以每轮下降的梯度为:

SCAFFOLD

FedProx 与 SCAFFOLD都是用了一个全局模型去修正本地训练方向。
实验结果

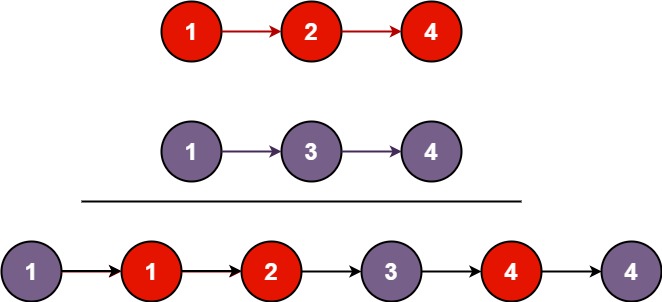
上图展示了达到0.5的test accuracy,各方法所需要的迭代轮数,SCAFFOLD是最快的。这是SCAFFOLD论文中做的对比实验,看起来FedProx没有达到宣称的效果。
需要的迭代轮数,SCAFFOLD是最快的。这是SCAFFOLD论文中做的对比实验,看起来FedProx没有达到宣称的效果。