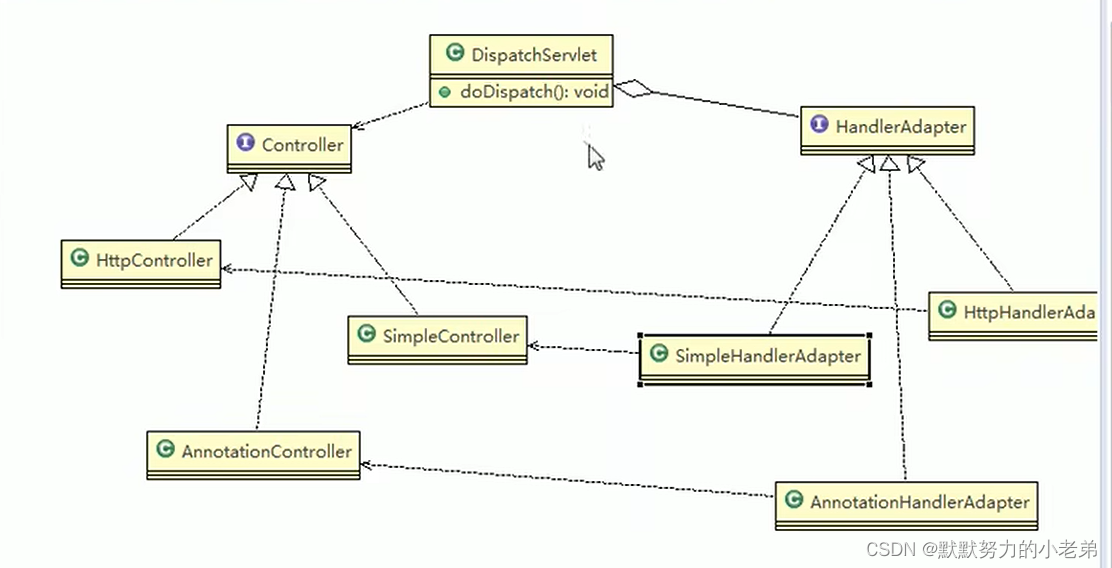
PSM倾向性匹配得分
定义
就是一个用户属于实验组的倾向性,也就是在特定特征的情况下属于实验组的概率(条件概率)
其他定义:
PSM 通过统计学模型计算每个观测的每个协变量的综合倾向性得分,再按照倾向性得分是否接近进⾏匹配。
用直白的话来讲就是:由于变量太多,如果坚持各个变量一一精确匹配,那估计匹配下来没几个样本能一一匹配得上了。那不如直接用倾向得分,根据影响是否接受培训的各个元素,将每个用户计算出一个是否接受培训得分,从而将多维向量的信息压缩到一维,最后根据倾向得分进行匹配。

PSM倾向得分匹配法即通过对实验组样本建模,通过预测概率,为控制组每个用户拟合⼀个概率,每⼀个处理组样本在控制组找到⼀个和⾃⼰最接近的样本。
满足的假设
条件独立假设
直白地说即在接受实验之前,处理组和控制组之间没有差异,处理组产生的效应完全来自实验处理。拿上面的例子来说,即为员工是否接受培训与其工资水平相互独立。
共同⽀撑假设
直白地说即在理想情况下,出现在处理组的个体,也能在控制组中找到对应的个体。但实际中可能出现处理组的个体在控制组找不到对应的个体。拿上面的例子来说,就是可能会出现处理组全是初中毕业,控制组全是博士毕业。即在下图中,共同取值范围较少,那PSM可能就不适合了。

这里感觉可以用机器学习方法或者深度学习拓展一下,指预测部分
理解
理解PSM的来历
举个例子:
要研究X对Y的影响, 这时候有一个样本A,恰好A有一个孪生兄弟A’,对A和A’施加不同的X效果,即可发现X对Y的影响。
但是在显示生活中,这样的样本不好找,再加上A有不同的属性(变量),使得匹配难上加难。
那么,可不可以用一种方法给一个样本打个分,按照分数来匹配(好像田忌赛马,但是是上等对上等,中等对中等,下等对下等),这就实现了从而将多维向量的信息压缩到一维,最后根据倾向得分进行匹配。
stata实现
【代码参见】