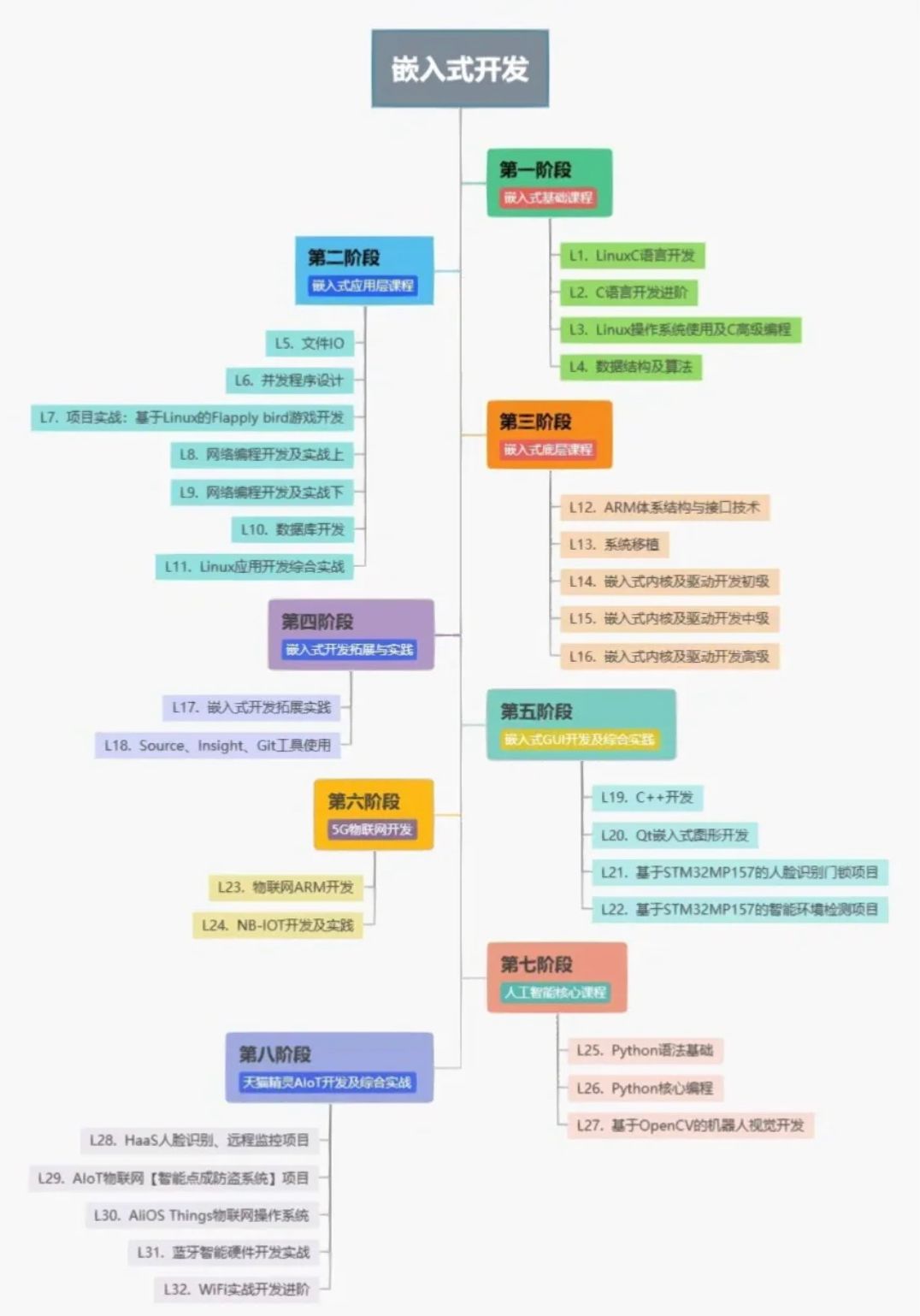
客户端都有哪些不常见但是很高级的功能?
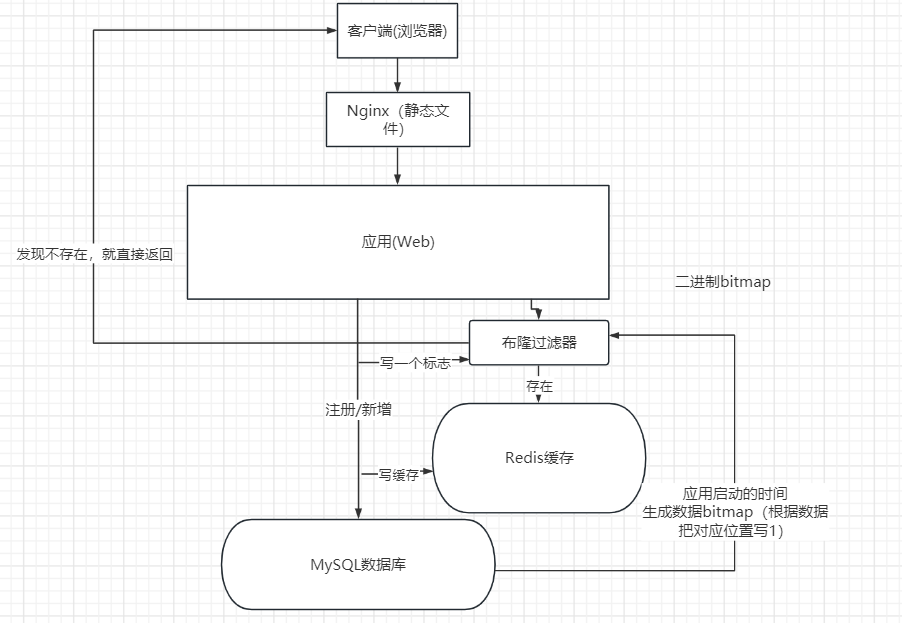
什么是 Kafka 拦截器?
- 拦截器基本思想就是允许应用程序在不修改逻辑的情况下,动态地实现一组可插拔的事件处理逻辑链。
- 它能够在主业务操作的前后多个时间点上插入对应的“拦截”逻辑。
- Spring MVC 拦截器的工作原理:
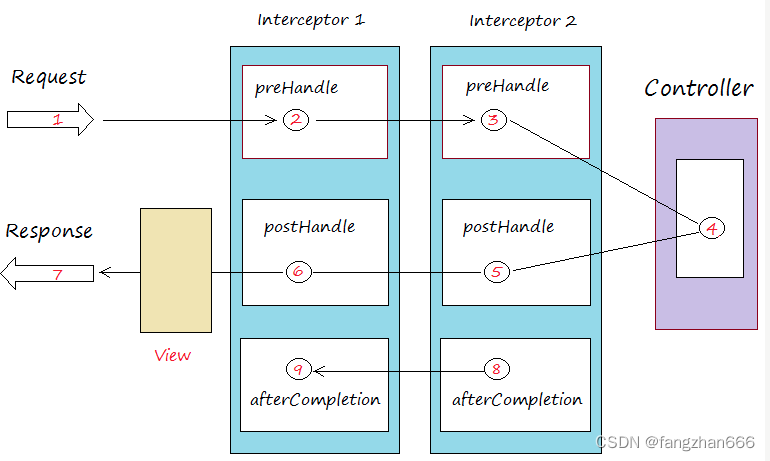
- Kafka 拦截器借鉴了这样的设计思路:可以在消息处理的前后多个时点动态植入不同的处理逻辑,比如在消息发送前或者在消息被消费后。
Kafka 拦截器
- Kafka 拦截器分为生产者拦截器和消费者拦截器。
- 生产者拦截器允许你在发送消息前以及消息提交成功后植入你的拦截器逻辑;
- 消费者拦截器支持在消费消息前以及提交位移后编写特定逻辑。
- 这两种拦截器都支持链的方式,即你可以将一组拦截器串连成一个大的拦截器,Kafka 会按照添加顺序依次执行拦截器逻辑。
- 当前 Kafka 拦截器的设置方法是通过参数配置完成的。
- 生产者和消费者两端有一个相同的参数,名字叫 interceptor.classes,它指定的是一组类的列表,每个类就是特定逻辑的拦截器实现类。
- 指定拦截器类时要指定它们的全限定名,也就是要把完整包名也加上,不要只有一个类名,并且还要保证 Producer 程序能够正确加载拦截器类。
典型使用场景
- Kafka 拦截器可以应用于包括客户端监控、端到端系统性能检测、消息审计等多种功能在内的场景。
- Kafka 默认提供的监控指标都是针对单个客户端或 Broker 的,你很难从具体的消息维度去追踪集群间消息的流转路径。同时,如何监控一条消息从生产到最后消费的端到端延时也是很多 Kafka 用户迫切需要解决的问题。
- 通过实现拦截器的逻辑以及可插拔的机制,我们能够快速地观测、验证以及监控集群间的客户端性能指标,特别是能够从具体的消息层面上去收集这些数据。这就是 Kafka 拦截器的一个非常典型的使用场景。