前言
今天话有点多,连续发了几篇博客,主要平常忙的话就没时间关注博客这块,今天兴致在,就勤快点哈哈
一般公司除非有钱,他可以购买ip服务器,或者大量高质量ip,但是有的时候,公司经济有限,需求量不大,个人本身做些业务的需求上,那么就可以自己搭建个本地的个人ip池。因此我们可以理清下搭建池的思路与逻辑如何
设计与思考
数据库选择
首先我们要一个存储ip的数据库,他需要满足存储,调度,去重,检验ip可用性的需求,那么我们可以比较下三大数据库对与这一需求的对比,结果如下
- MySQL:可存储,但不能去重,且查询效率低
- MongoDB:可以存储IP,查询效率良好,但它也不能去重
- Redis:可存储,查询效率最高,还有良好的去重的集合(zset)
对比下来,redis是最合适的存储方案了
那么为什么要用zset呢?
zset除了可以去重,还有一个特性,他有一个分值(score),我们可以通过控制分值的高低就可以将稳定性高的IP取出来,从而提高免费IP的可用性,达到检验ip可用性的需求。
可以设置每个IP定一个初始分值(50),然后对每个IP都进行校验,如果这个IP可用那么就将这个IP的分值拉满(100),如果不可用就进行扣分(10),直到IP变成0分,就将这个IP删除。
基本步骤
对此,数据库解决了,然后基本流程梳理下,可分以下三步:
- 采集:写爬虫抓取IP,将IP存储到
- Redis 校验:从Redis中取出IP,用IP简单发送一个请求,如果可以正常返回,证明该IP可用
- 提供:写api接口,将可用的IP提供给用户
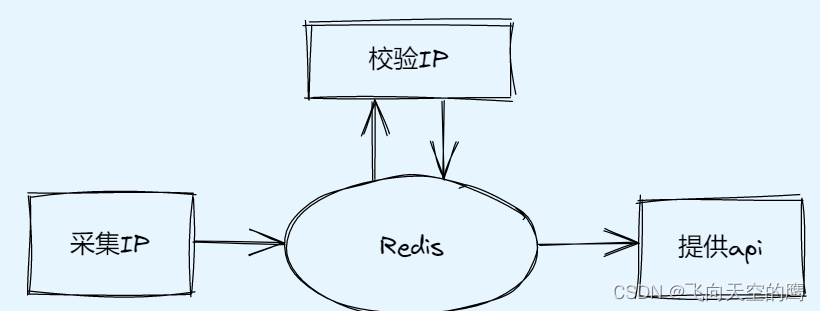
仔细观察上图,三个操作都用到了Redis,所以就先写Redis涉及到的各种操作,再写其他三个功能就可以了
1、Redis的主要操作
- 连接Redis
- zset存储(判断IP存不存在,不存在就新增 )
- 查询所有IP(校验IP时要用到)
- 将分值拉满(IP可用)
- 将分值降低(IP不可用)
- 查询可用的IP(先给满分的,没有满分的给51-99分的)
代码如下:
from redis import Redis
from settings import *
class ProxyRedis:
# 连接redis
def __init__(self):
self.red = Redis(
host=REDIS_HOST,
port=REDIS_PORT,
db=REDIS_DB,
password=REDIS_PASSWORD,
decode_responses=True)
# 存储ip
def add_proxy_ip(self, ip):
# 判断是否有ip
if not self.red.zscore(REDIS_KEY, ip):
self.red.zadd(REDIS_KEY, {ip: DEFAULT_SCORE})
print("采集到了IP地址了", ip)
else:
print("采集到了IP地址了", ip, "但是已经存在")
# 查询所有ip
def get_all_proxy(self):
return self.red.zrange(REDIS_KEY, 0, -1)
# 将分值拉满
def set_max_score(self, ip):
self.red.zadd(REDIS_KEY, {ip: MAX_SCORE})
# 降低分值
def reduce_score(self, ip):
# 查询分值
score = self.red.zscore(REDIS_KEY, ip)
# 如果有分值,扣分
if score > 0:
self.red.zincrby(REDIS_KEY, -10, ip)
else: # 分值没有则删除
self.red.zrem(REDIS_KEY, ip)
# 查询可用ip
def get_avail_proxy(self):
lis = []
ips = self.red.zrangebyscore(REDIS_KEY, MAX_SCORE, MAX_SCORE, 0, -1)
if ips:
lis.append(ips)
return lis
else:
ips = self.red.zrangebyscore(REDIS_KEY, DEFAULT_SCORE + 1, MAX_SCORE - 1, 0, -1)
if ips:
lis.append(ips)
return lis
else:
print("没有可用ip")
return None
2、采集渠道
这里我爬取了三个网站,当然感觉不够用的自己还可以加
快代理:https://www.kuaidaili.com/free/intr/1/
高可用全球免费代理IP库:https://ip.jiangxianli.com/?page=1
66免费代理网:http://www.66ip.cn/areaindex_1/1.html
代码如下:
# 代理IP采集
from proxy_redis import ProxyRedis
import requests
from lxml import etree
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36"
}
# 采集快代理
def get_kuai_ip(red):
url = "https://www.kuaidaili.com/free/intr/1/"
resp = requests.get(url, headers=headers)
tree = etree.HTML(resp.text)
trs = tree.xpath("//table/tbody/tr")
for tr in trs:
ip = tr.xpath("./td[1]/text()") # ip地址
port = tr.xpath("./td[2]/text()") # 端口
if not ip:
continue
ip = ip[0]
port = port[0]
proxy_ip = ip + ":" + port
red.add_proxy_ip(proxy_ip) # 增加ip地址
# 采集66免费代理网
def get_66_ip(red):
url = "http://www.66ip.cn/areaindex_1/1.html"
resp = requests.get(url, headers=headers)
tree = etree.HTML(resp.text)
trs = tree.xpath("//table//tr")[1:]
for tr in trs:
ip = tr.xpath("./td[1]/text()") # ip地址
port = tr.xpath("./td[2]/text()") # 端口
if not ip:
continue
ip = ip[0]
port = port[0]
proxy_ip = ip + ":" + port
red.add_proxy_ip(proxy_ip) # 增加ip地址
# 采集高可用全球免费代理IP库
def get_quan_ip(red):
url = "https://ip.jiangxianli.com/?page=1"
resp = requests.get(url, headers=headers)
tree = etree.HTML(resp.text)
trs = tree.xpath("//table//tr")
for tr in trs:
ip = tr.xpath("./td[1]/text()") # ip地址
port = tr.xpath("./td[2]/text()") # 端口
if not ip:
continue
ip = ip[0]
port = port[0]
proxy_ip = ip + ":" + port
red.add_proxy_ip(proxy_ip) # 增加ip地址
def run():
red = ProxyRedis() # 创建redis存储
while True:
try:
get_kuai_ip(red) # 采集快代理
get_66_ip(red) # 采集66免费代理
get_quan_ip(red) # 采集全球免费ip代理库
except:
print("出错了")
time.sleep(60) # 每分钟跑一次
if __name__ == '__main__':
run()
3、校验IP可用性
- 查询所有的IP
- 每一个IP都发送一个请求,可用分值拉满,不用可扣分
这里如果我们采集的IP比较多的话,用单线程就比较慢了,所以为了提高效率,这里我采用协程
代码如下:
# 代理IP的验证
from proxy_redis import ProxyRedis
from settings import *
import asyncio
import aiohttp
import time
async def verify_one(ip, sem, red):
print(f"开始检测{ip}")
timeout = aiohttp.ClientTimeout(total=10) # 设置超时时间,超过10秒就报错
try:
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get("http://www.baidu.com/", proxy="http://" + ip, timeout=timeout) as resp: # 简单发送一个请求
page_source = await resp.text()
if resp.status in [200, 302]: # 验证状态码
# 将分值拉满
red.set_max_score(ip)
print(f"检测到{ip}是可用的")
else:
red.reduce_score(ip)
print(f"检测到{ip}是不可用的, 扣10分")
except Exception as E:
print("ip检验时出错了", E)
red.reduce_score(ip)
print(f"检测到{ip}是不可用的, 扣10分")
async def main(red):
# 查询全部ip
all_proxy = red.get_all_proxy()
sem = asyncio.Semaphore(SEM_COUNT) # 控制并发量
tasks = []
for ip in all_proxy:
tasks.append(asyncio.create_task(verify_one(ip, sem, red)))
if tasks:
await asyncio.wait(tasks)
def run():
red = ProxyRedis()
time.sleep(10)
while True:
try:
asyncio.run(main(red))
time.sleep(100)
except Exception as e:
print("校验时报错了", e)
time.sleep(100)
if __name__ == '__main__':
run()
4、提供api
- 给用户提供一个http接口,用户通过访问http://xxx.xxx.xxx.xxx:xxxx/get_proxy就可获取到IP
安装提供api接口的模块
pip install sanic
pip install sanic_cors # 防止出现跨域的模块
代码如下:
# 代理的IP的api接口
from proxy_redis import ProxyRedis
from sanic import Sanic, json
from sanic_cors import CORS
app = Sanic("ip") # 1. 创建app
CORS(app) # 2. 解决跨域
red = ProxyRedis()
# 3. 准备处理http请求的函数
@app.route("/get_proxy") # 路由配置
def dispose(rep):
ip_list = red.get_avail_proxy()
return json({"ip": ip_list}) # 返回给客户端
def run():
app.run(host="127.0.0.1", port=5800)
if __name__ == '__main__':
run()
4、启动采集IP、校验IP、提供api
- 将三个功能串在一起,每一个功能开一个进程,命名 runner.py
from ip_api import run as api_run
from ip_collection import run as col_run
from ip_verify import run as ver_run
from multiprocessing import Process
def run():
# 启动三个进程
p1 = Process(target=api_run)
p2 = Process(target=col_run)
p3 = Process(target=ver_run)
p1.start()
p2.start()
p3.start()
if __name__ == '__main__':
run()
5、配置文件
做个代理IP池的配置文件,对于想要修改参数的直接修改配置文件就行
# 配置文件
# proxy_redis
# redis主机ip地址
REDIS_HOST = "127.0.0.1"
# redis端口号
REDIS_PORT = 6379
# redis数据库编号
REDIS_DB = 2
# redis的密码
REDIS_PASSWORD = "123456"
# redis的key
REDIS_KEY = "proxy_ip"
# 默认的ip分值
DEFAULT_SCORE = 50
# 满分
MAX_SCORE = 100
# ip_verify
# 一次检测ip的数量
SEM_COUNT = 30
6、运行效果与检验
最后就是运行启动程序,效果图如下:
采集界面:
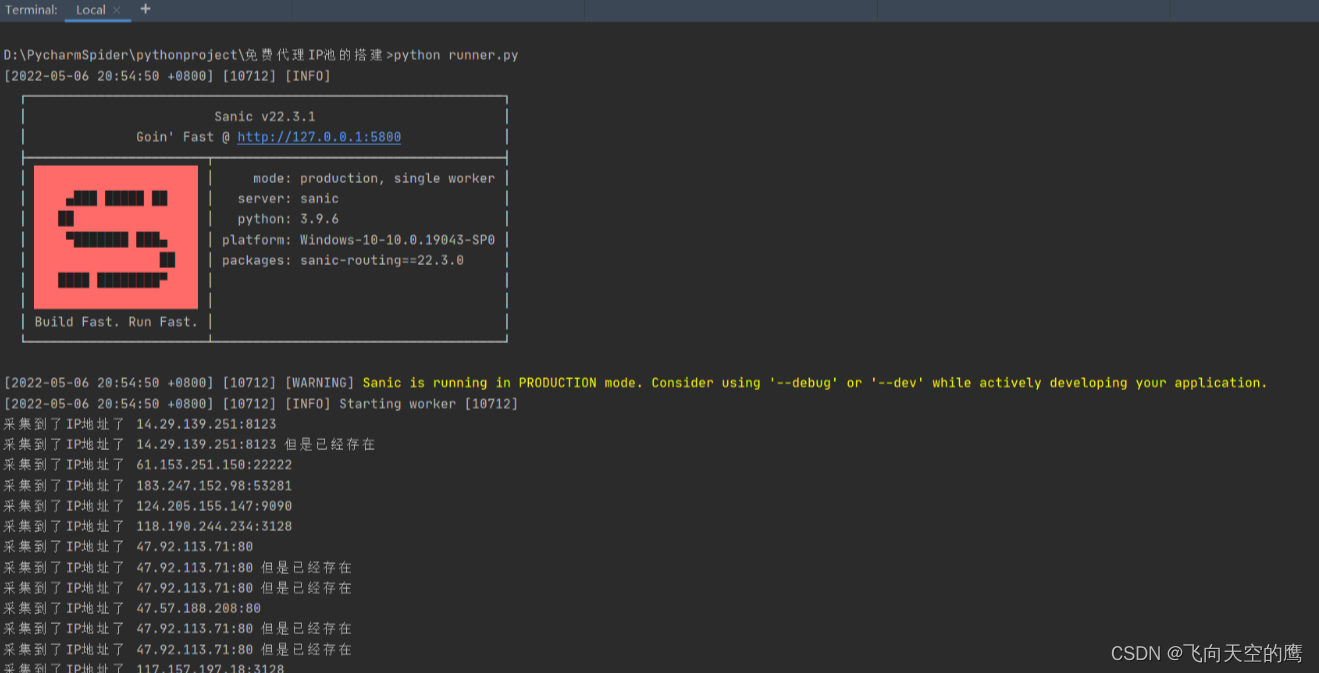
校验界面:
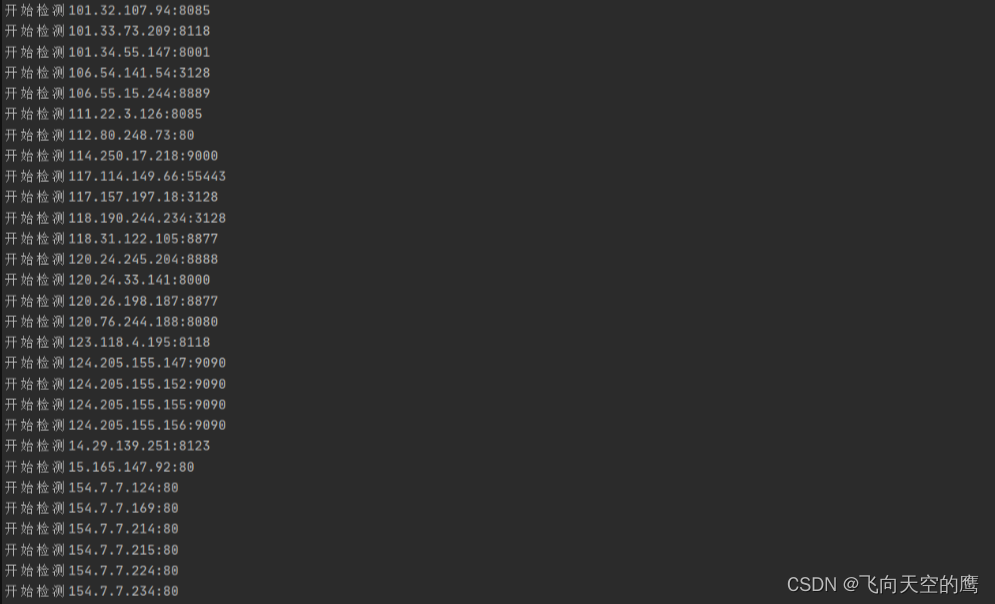
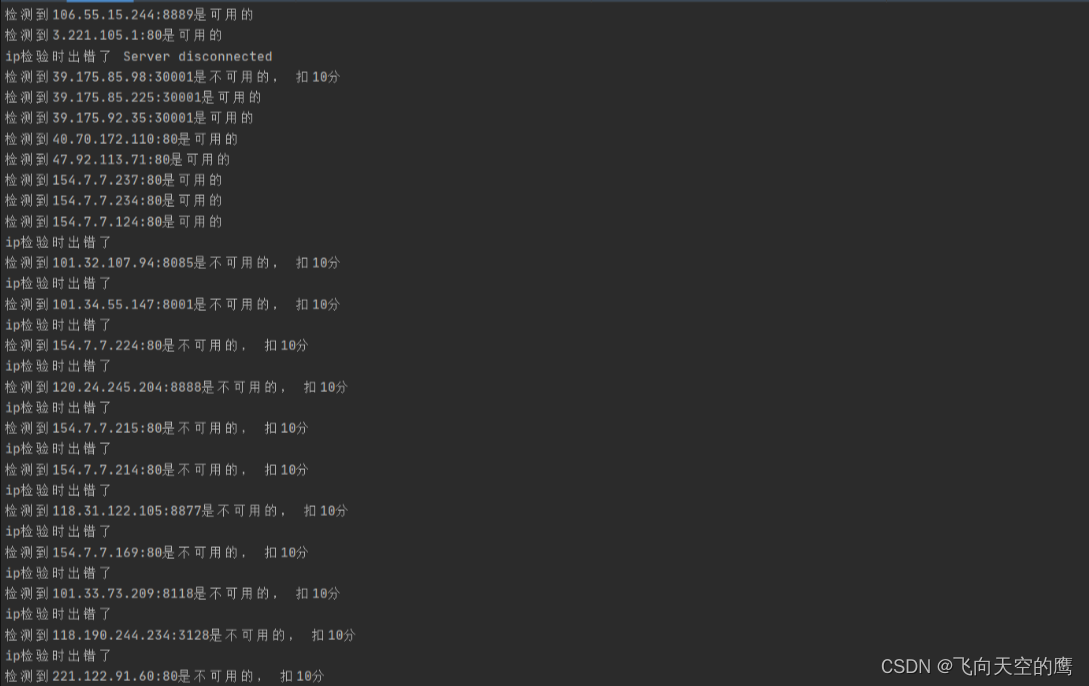
我们可以看到程序可以正常执行
然后去看一下我们的Redis中是否有IP
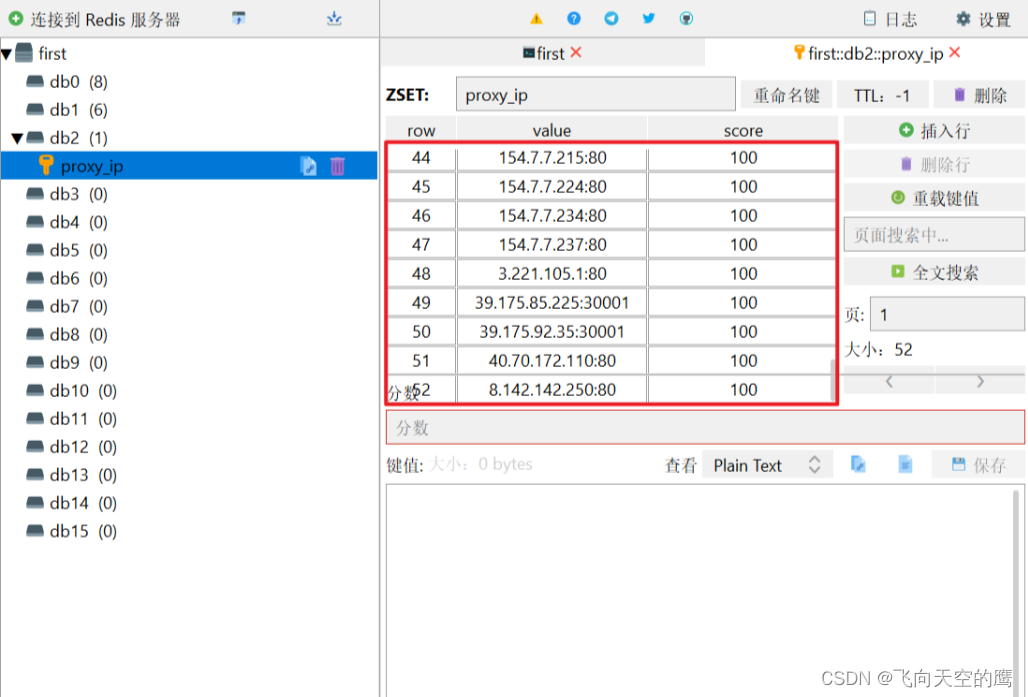
接口检验,访问 http://127.0.0.1:5800/get_proxy,检测用户是否可以拿到IP。
如下图:

- 检验IP代理池中的IP是否可用
免费IP代理池已经搭建好了,接下来就从IP代理池中取出来IP,检测IP是否可以使用
因为我们的IP有很多,使用这些IP最好的方法是将存放IP的列表进行循环,每拿一个IP访问一次或多次就换一个IP在访问,所以就需要写一个生成器,代码如下:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36"
}
def get_proxy():
url = "http://127.0.0.1:5800/get_proxy"
resp = requests.get(url, headers=headers)
ips = resp.json()
for ip in ips["ip"][0]:
yield ip # 生成器
def spider():
url = "http://www.baidu.com/"
while True:
try:
proxy_ip = next(gen)
proxy = {
"http:": "http:" + proxy_ip,
"https:": "http:" + proxy_ip
}
resp = requests.get(url, proxies=proxy, headers=headers)
resp.encoding = "utf-8"
return resp.text
except:
print("代理失效了")
if __name__ == '__main__':
gen = get_proxy()
page_source = spider()
print(page_source)
获取到数据源码就正常运行,如下图:
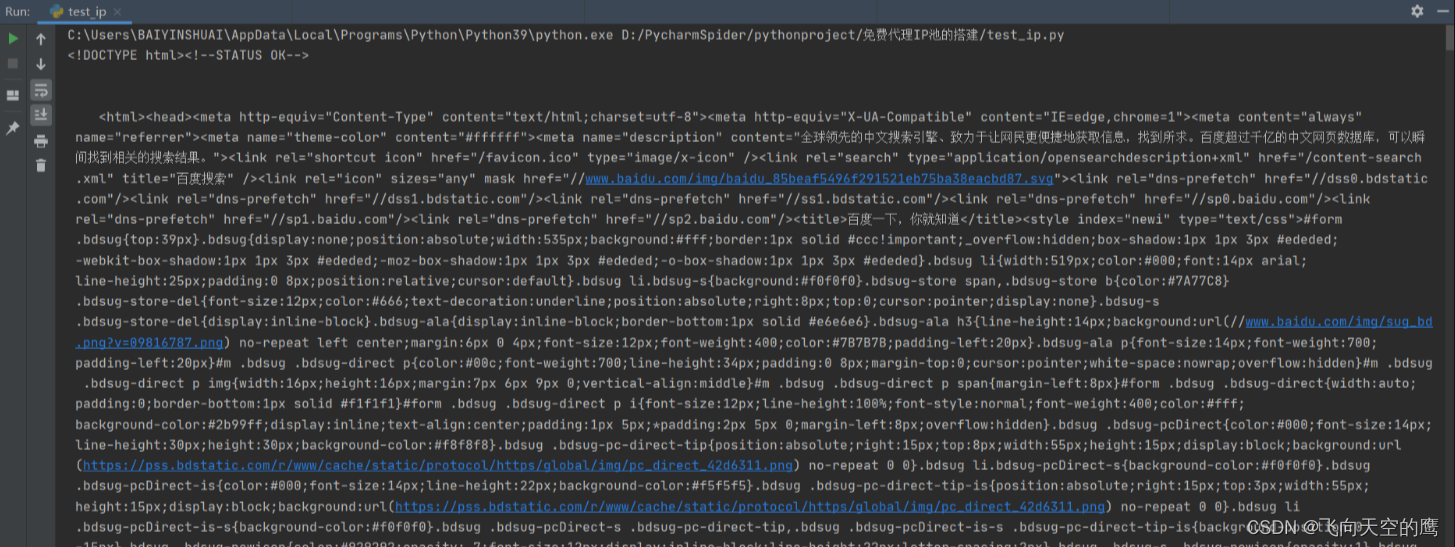
自此,个人搭建的ip池就完成了。





![[web]前端富文本编辑器](https://img-blog.csdnimg.cn/475e13aa5b12402db291c96163359a2c.png)