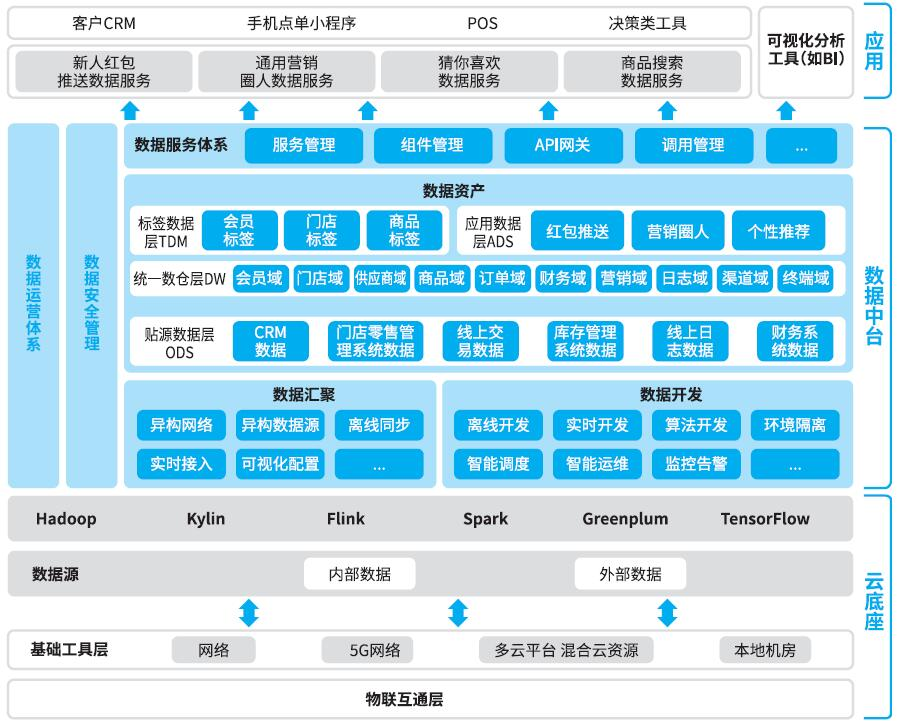
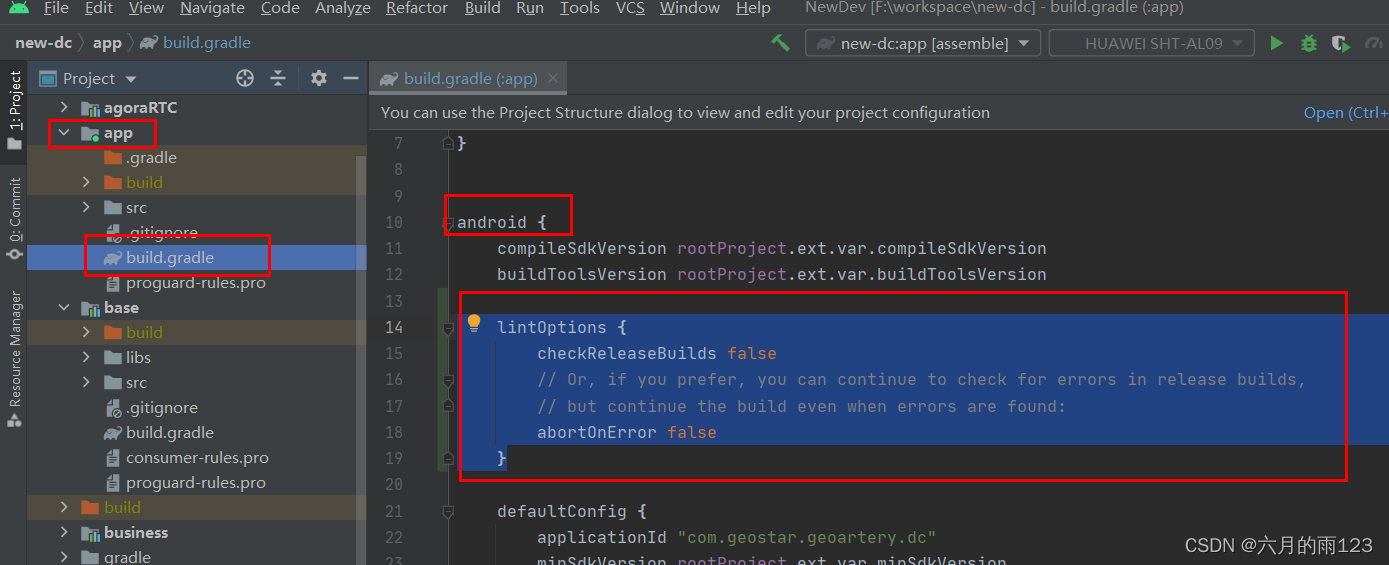
目录
一、前言
二、数据准备
三、进行预处理
四、进行降维任务
五、正态性检测
六、描述性统计
七、频数分析
八、代码功能
一、前言
SPSSPRO是一款全新的在线数据分析平台,可以用于科研数据的分析、数学建模等,对于那些不会编程或者刚进入科研的新人来说,这款工具再合适不过了。当然本人只是很早之前建模用过,所以有点关公面前武大刀的嫌疑。
二、数据准备
1、首先准备一份数据,这份数据需要表头等信息,我以一份CSI幅值数据为例(300行*30列)。当然表头可以自己打上去,也可以使用MATLAB或者其它程序进行标签。MATLAB打上表头标签:
T = array2table(raw_amp);
writetable(T,'SpassTest.xlsx');2、将生成的表格导入spasspro里面,并查看数据:
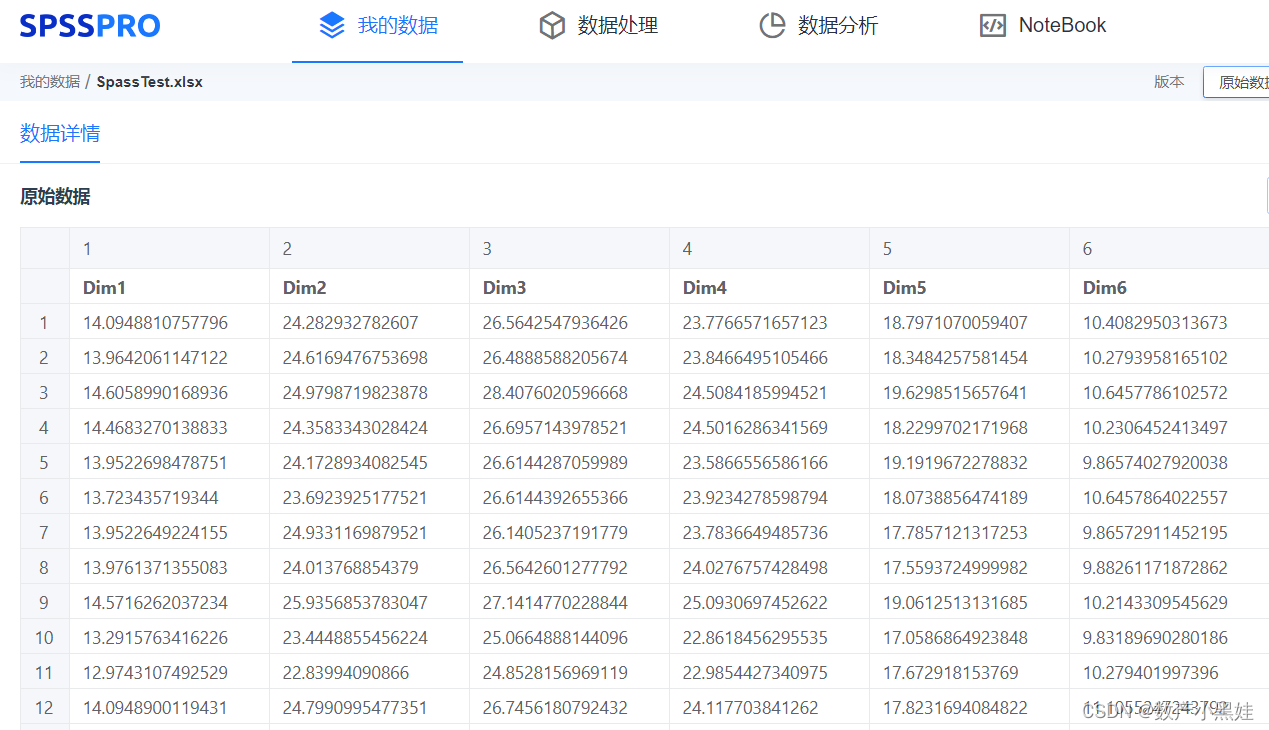
三、进行预处理
1、数据处理——>异常值处理
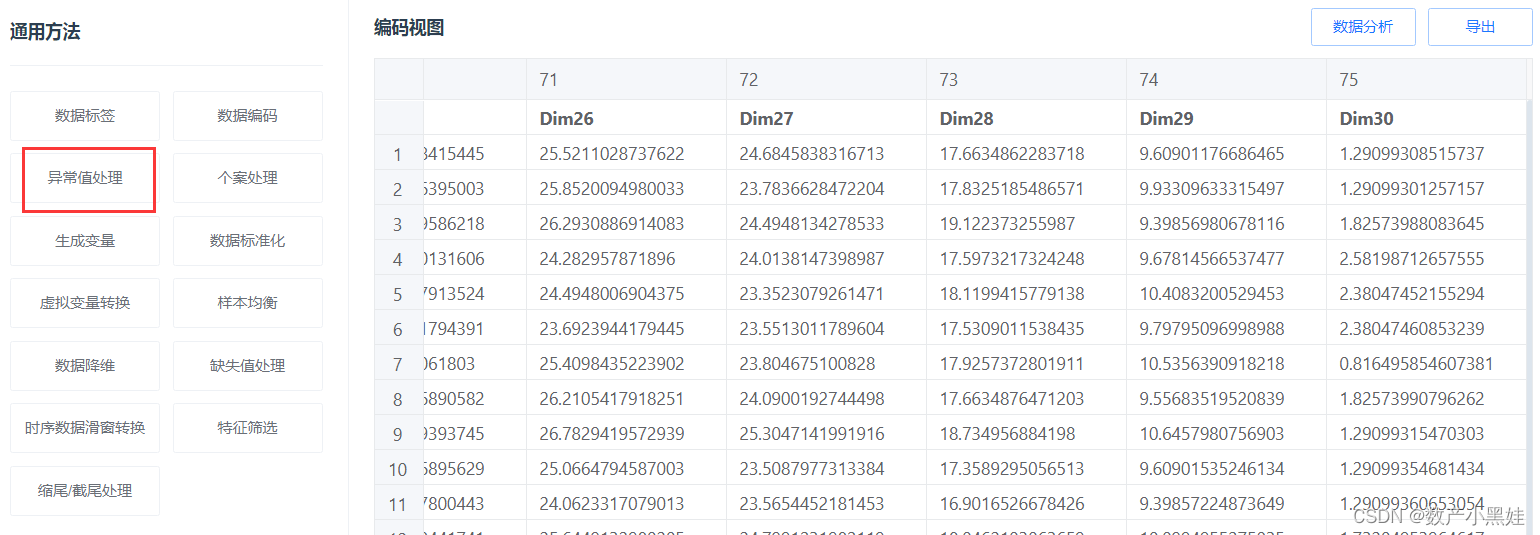
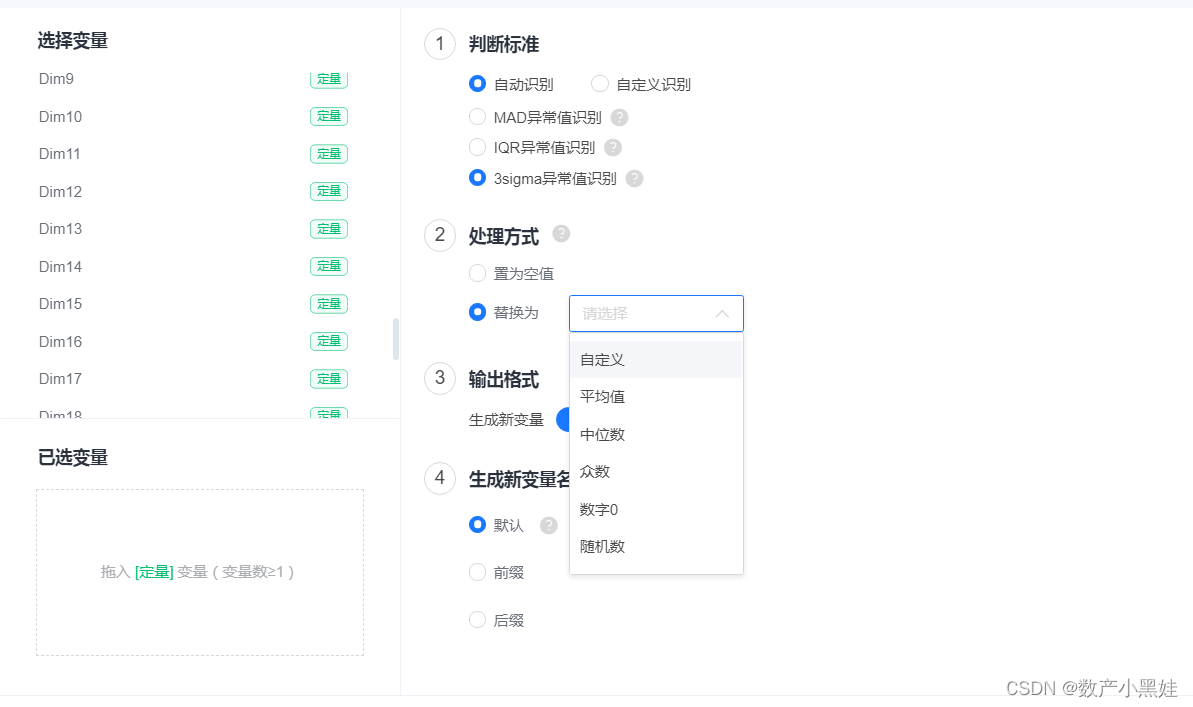
2、 选择三倍标准差进行预处理,对检测出的异常值可以直接剔除,也可以用中位数、平均数、众数等替代,具体根据你的任务来。只需要将m维定量拖进已选变量中就行。
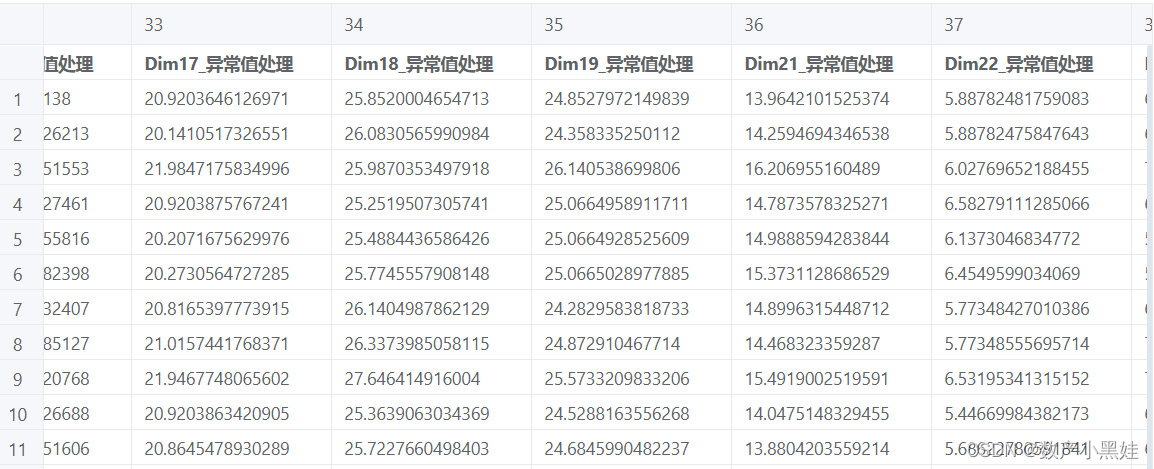
3、生成处理完成的数据,表头名字由上图第四项决定(我们选择的是默认):
四、进行降维任务
1、根据自己的任务选择合适的降维算法,这里选择PCA算法进行线性降维,如果你的数据是非线性的,可以采用KPCA降维算法。总方差解释率表示降维后保留多少信息,一般选择在90%-99%之间,可以根据自己的任务来。

2、 生成降维后的数据,这里我们是从30维降至15维
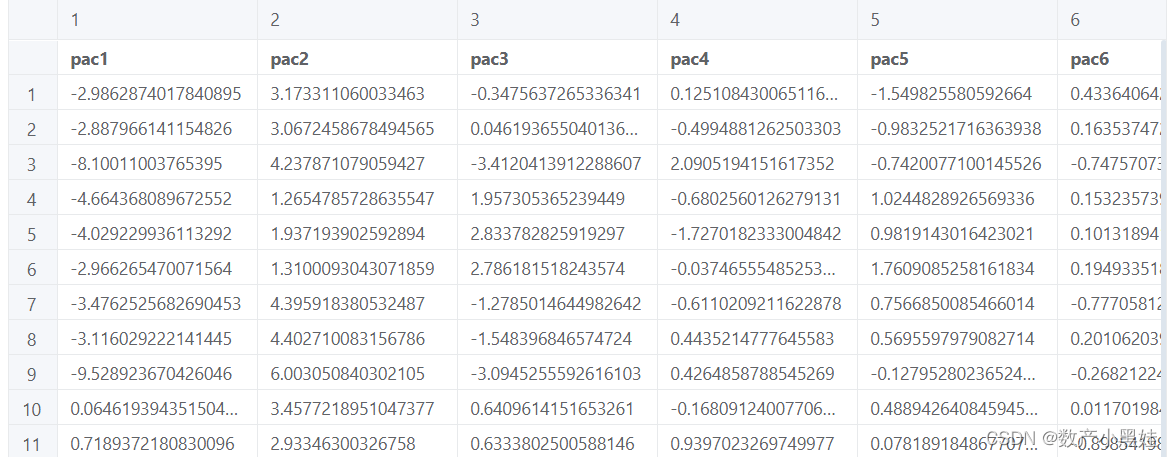
3、降维的相关性分析
数据分析——>选择分析项目——>选择相关性分析
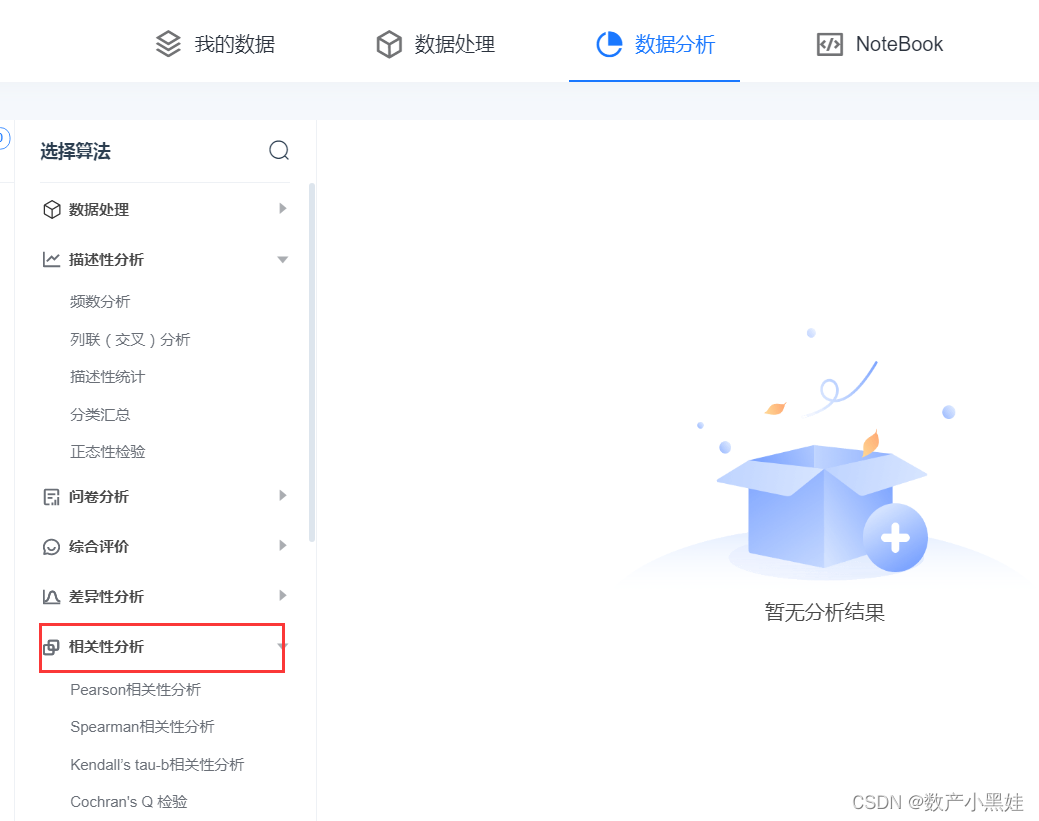
生成降维后的相关性热力图,从热力图也可以看出降维后的特征正交(即互不相关,相关性系数为0)

五、正态性检测
1、选择算法——>描述性分析——>正态性检测,以第一维度的数据为例:
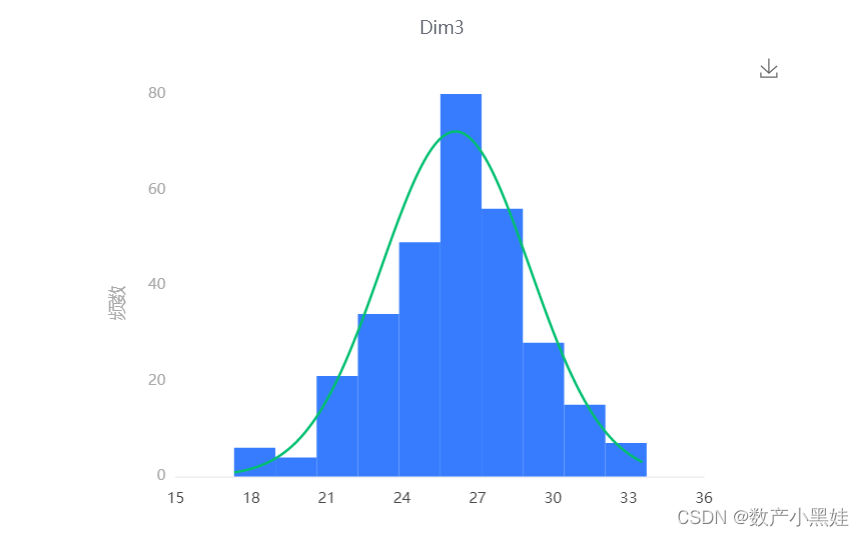
上图展示了Dim3数据的正态性检验直方图,若正态图基本上呈现出钟形(中间高,两端低),则说明数据虽然不是绝对正态,但基本可接受为正态分布。从检测的结果来看,30个维度基本可接受为正态分布。
2、正态性检验P-P图

上图是Dim1计算观测的累计概率(P)与正态累计概率(P)的拟合情况。拟合程度越高越服从正态分布。从检测的结果来看,30个维度基本可接受为正态分布。
六、描述性统计
首先,对总体的各项统计指标进行整体描述分析。其次,对异常或者表现得较为突出的指标进行分析,例如高方差、高平均值等等。
| 变量名 | 样本量 | 最大值 | 最小值 | 平均值 | 标准差 | 中位数 | 方差 | 峰度 | 偏度 | 变异系数(CV) |
|---|---|---|---|---|---|---|---|---|---|---|
| Dim1_异常值处理 | 300 | 16.35 | 10.083 | 13.571 | 1.116 | 13.626 | 1.246 | -0.014 | -0.291 | 0.08225067000693603 |
| Dim2_异常值处理 | 300 | 29.45 | 16.862 | 23.934 | 2.271 | 24.276 | 5.16 | 0.247 | -0.457 | 0.09490615857836082 |
| Dim3_异常值处理 | 300 | 33.724 | 17.32 | 26.124 | 2.949 | 26.382 | 8.696 | 0.259 | -0.25 | 0.11288086696067898 |
| Dim4_异常值处理 | 300 | 31.037 | 15.188 | 23.485 | 2.855 | 23.629 | 8.152 | 0.272 | -0.124 | 0.12157260045341392 |
| ......... | ......... | ......... | ......... | ......... | ......... | ......... | ......... | ......... | ......... | ......... |
| Dim30_异常值处理 | 300 | 4.203 | 0 | 1.877 | 0.852 | 1.826 | 0.726 | -0.407 | 0.326 | 0.4538913156287607 |
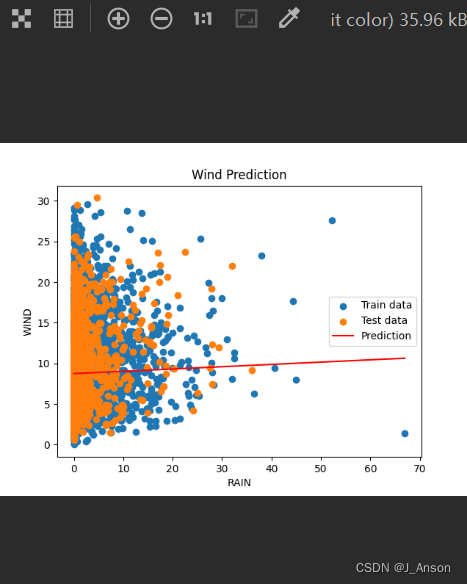
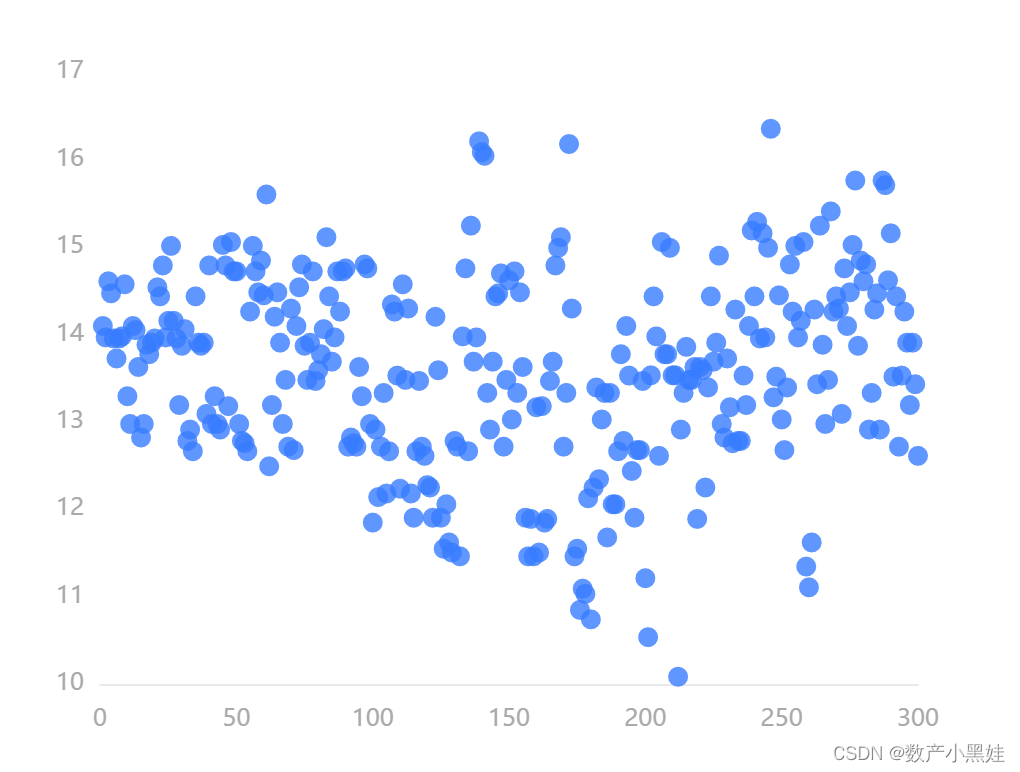
上表展示了描述性统计的结果,包括样本量、最大值、最小值等统计量,用于研究定量数据的整体情况。下图为某个维度的散点图可视化。
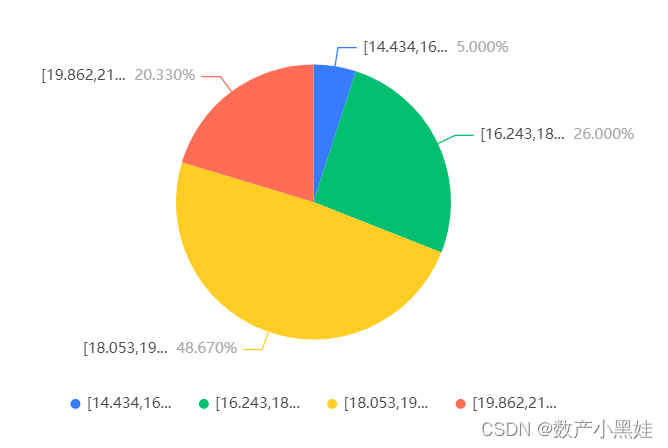
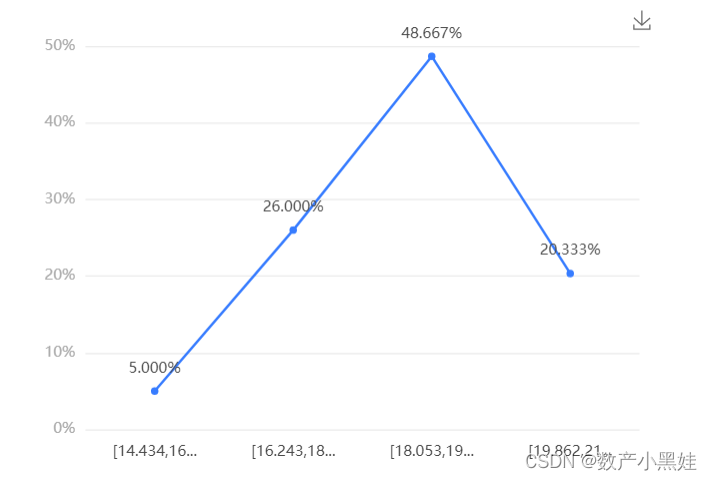
七、频数分析
下图展示了频数分析的结果,包括变量、频数、百分比等:

八、代码功能
1、SPSSPRO可直接编译python语言

2、 除了提供常用的py库外,还可以自己安装一些开源库

3、查看SPSSPRO已有的库,或者自己安装的库
4、利用代码进行导入数据的可视化,比如我们的数据是300*30的,进行可视化
(1)导入相应的库和数据
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_excel('SpassTest.xlsx')(2)打印数据

(3)可视化原始数据及三倍标准差处理后的数据

(4)我们发现系统的预处理方法并不是很好,所以自己在notebook写一个预处理程序进行处理

是不是觉得效果好多了啊,赶快行动起来吧,开始你的数据分析之旅。