什么是Tensorcore
Tensor core是nvidia底层执行运算的硬件单元,不同于nvidia以往的cuda core(全浮点型),Tensor core是近几年推出来的、混合精度的、将累加和累乘放在一起的计算硬件;
什么是混合精度
混合精度指的是在输入、输出的时候使用FP16,计算的时候使用FP32;

什么是GPU当中的kernel
在GPU编程中,"kernel"一词有特定的含义,与计算机操作系统中的内核不同。
在GPU编程中,"kernel"是指在并行计算中由多个线程同时执行的函数。它是在GPU上执行的并行计算任务的入口点。每个线程都独立地执行相同的代码,但可能使用不同的数据或索引来处理不同的任务或数据元素。
然而操作系统中kernel指的是操作系统与硬件之间的桥梁,用于管理操作系统对硬件和软件的访问和控制;
什么是SP/SM
GPU就是由显存+计算单元构成;

sp
streaming processor,最基本的处理单元,也就是cuda core
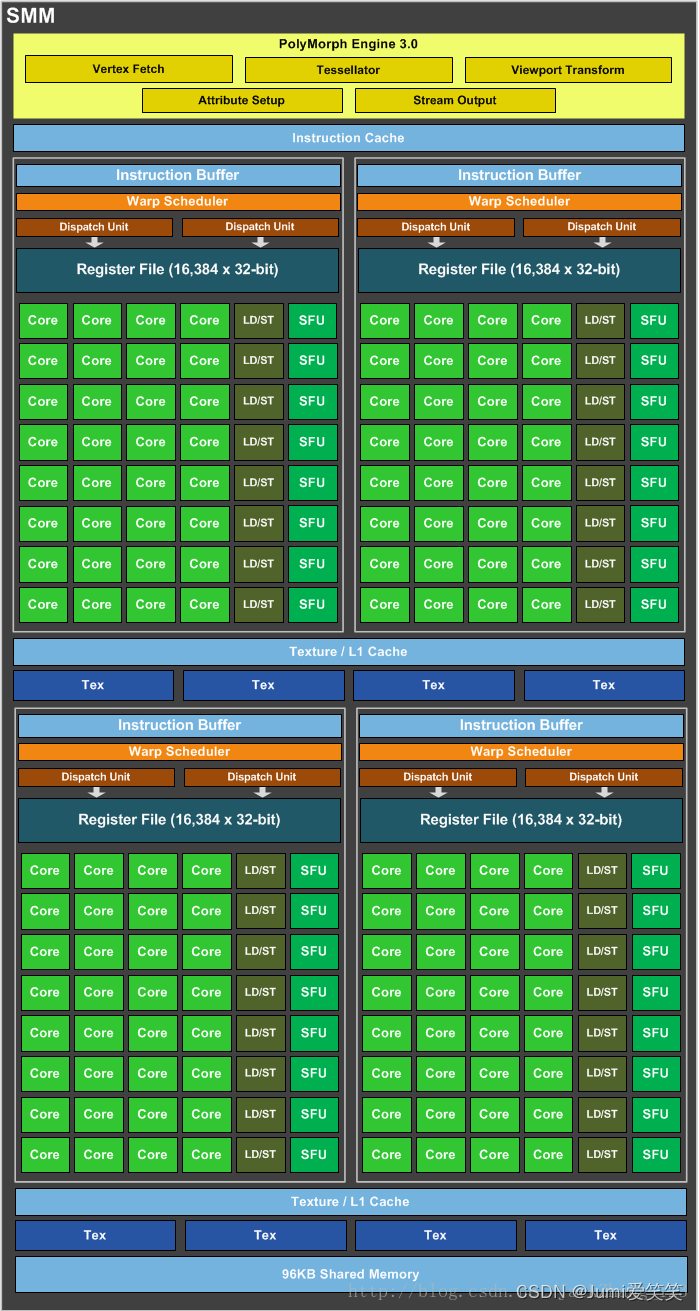
sm
streaming multiprocessors,由sp组成,每个SM包含的sp个数依据不同的GPU架构有所不同,从32~128不等,以上整个大图就是一个SM的示意图;
什么是warp
thread、block、grid、warp都是软件层面上的概念;
thread:一个CUDA的并行程序会被以许多个threads来执行。
block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
grid:多个blocks则会再构成grid。
warp:GPU执行程序时的最小调度单位,用于线程管理,目前一个warp可以管理32个线程,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT(单指令多线程)。
下图反应了block和grid之间的关系:
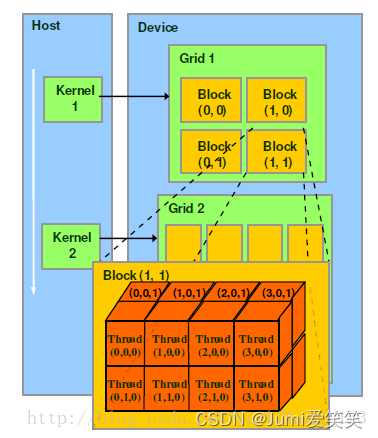
那么block和grid之间有什么区别呢?
Block(块):
Block是最基本的并行执行单元,它是一组线程的集合。这些线程可以协同工作来执行相同的操作。
在编写GPU kernel时,可以将问题划分为多个块,每个块独立地执行特定的计算任务。
每个块中的线程可以通过共享内存进行通信和协作。
块内的线程可以使用索引来访问自己的数据。
Grid(网格):
Grid是由多个块组成的集合,它表示了整个GPU上的并行计算任务。
Grid中的块可以相互独立地执行,彼此之间没有直接的通信和协作。
块之间可以通过全局内存进行数据交换。
网格中的块可以具有不同的块大小(线程数),因此可以根据任务的要求进行动态配置。
总结来说,Block(块)是GPU上最小的并行执行单位,它由一组线程组成,可以协同工作来执行特定的计算任务。Grid(网格)是由多个块组成的集合,表示了整个GPU上的并行计算任务。块内的线程可以通过共享内存进行通信和协作,而块之间可以通过全局内存进行数据交换。使用块和网格的组织方式可以实现高效的并行计算和数据共享。
关于SM和wrap,二者并没有直接的对应关系,解释如下:
在NVIDIA的GPU架构中,“SM”(Streaming Multiprocessor)和 “warp” 是两个相关但不完全相同的概念。
SM(Streaming Multiprocessor):
SM是GPU架构中的基本并行处理单元,也被称为流多处理器或多处理器。
一个GPU芯片通常包含多个SM,每个SM可以同时执行多个线程。
SM包含一组CUDA核心(也称为CUDA核),如CUDA Core或流处理器,用于执行指令和计算任务。
Warp(线程束):
Warp是SM中执行的最小调度单元,它是一组连续的线程。
在NVIDIA的GPU架构中,一般将32个线程组成一个warp。
当一个SM执行一条指令时,它会将指令分派给一个warp中的所有线程同时执行。
这意味着一个SM在同一时钟周期内会同时执行warp中的32个线程。
因此,可以说每个SM中的warp是并行执行的最小单元。SM将指令分派给warp,并且这些线程会同时执行,利用SIMD(Single Instruction, Multiple Data)并行性。这种并行性是通过在一个warp内执行相同的指令,但使用不同的数据来实现的。
需要注意的是,不同GPU架构可能具有不同的warp大小和SM配置。例如,现代的NVIDIA GPU架构如Turing和Ampere中的warp大小为32,而早期的架构如Kepler和Maxwell中的warp大小为64。因此,具体的warp大小和SM配置取决于GPU架构和型号。
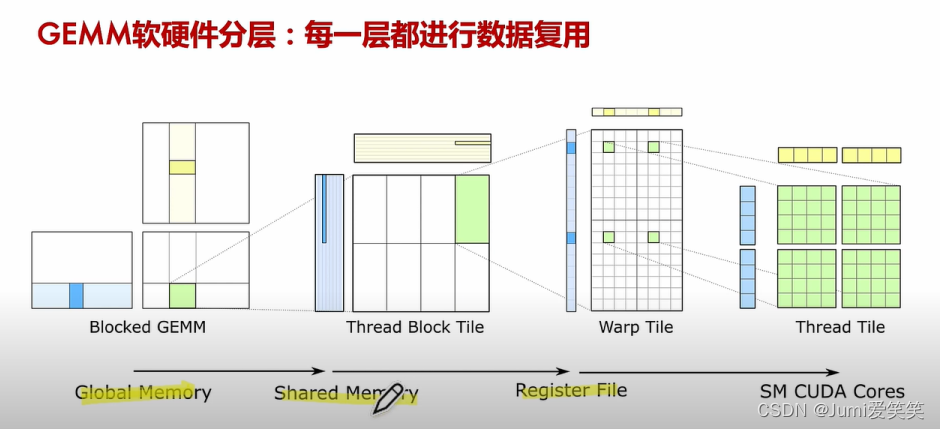
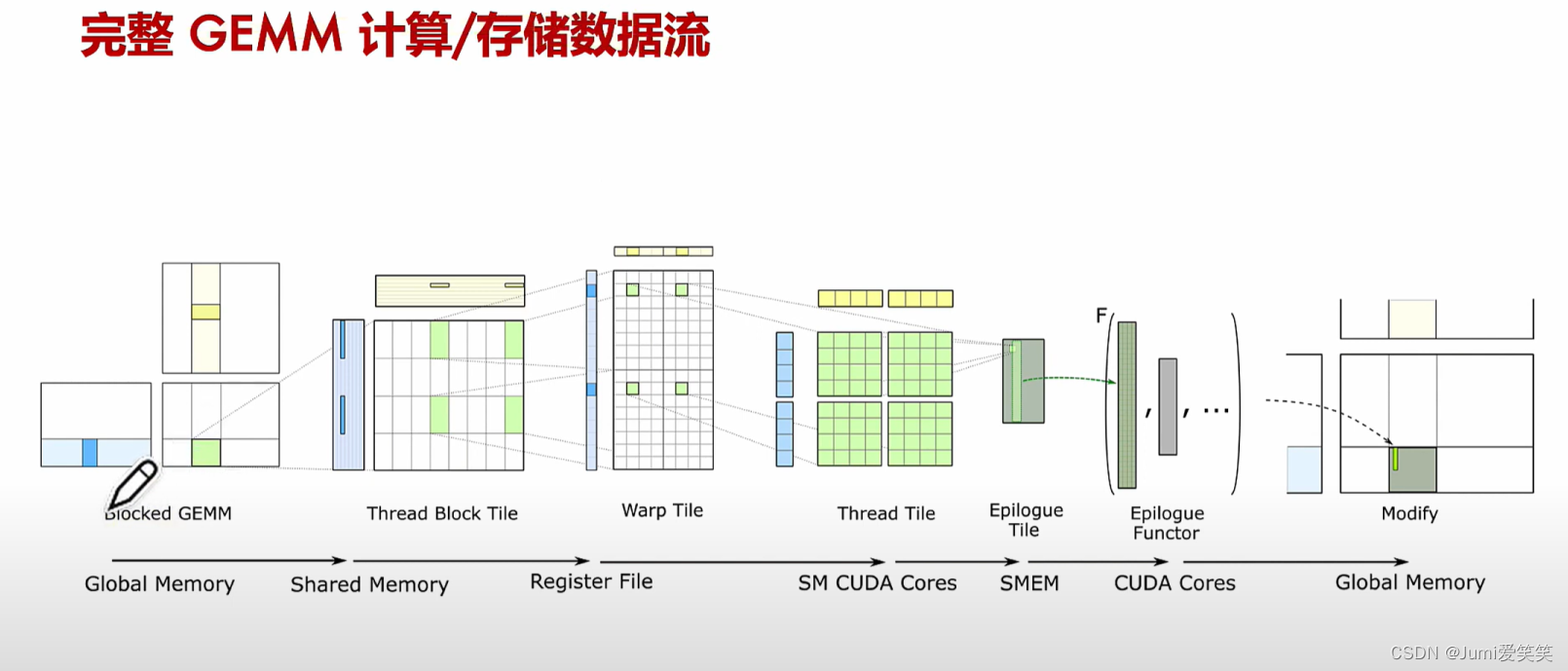
下图反映了软硬件方面的对应关系:

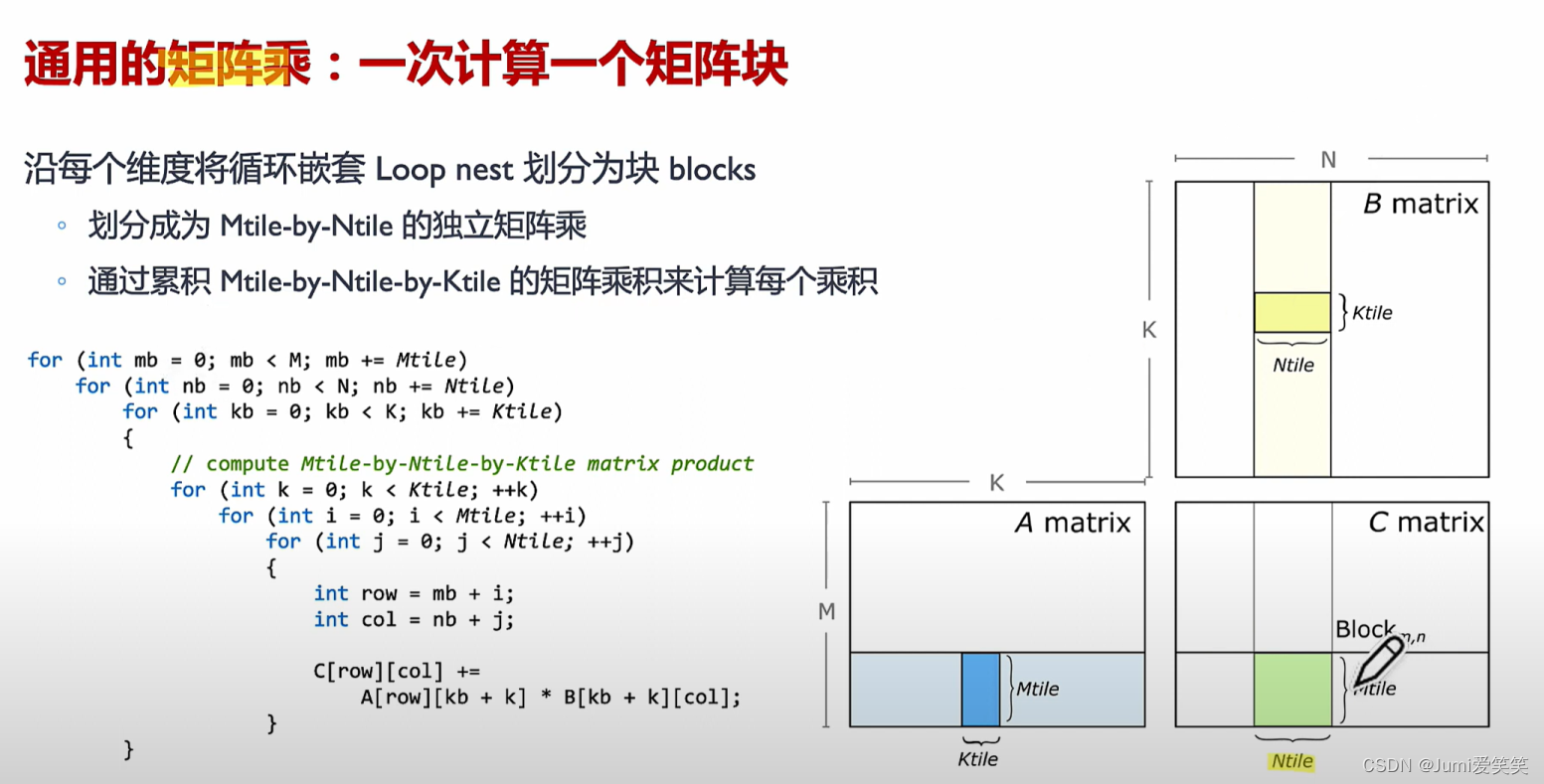
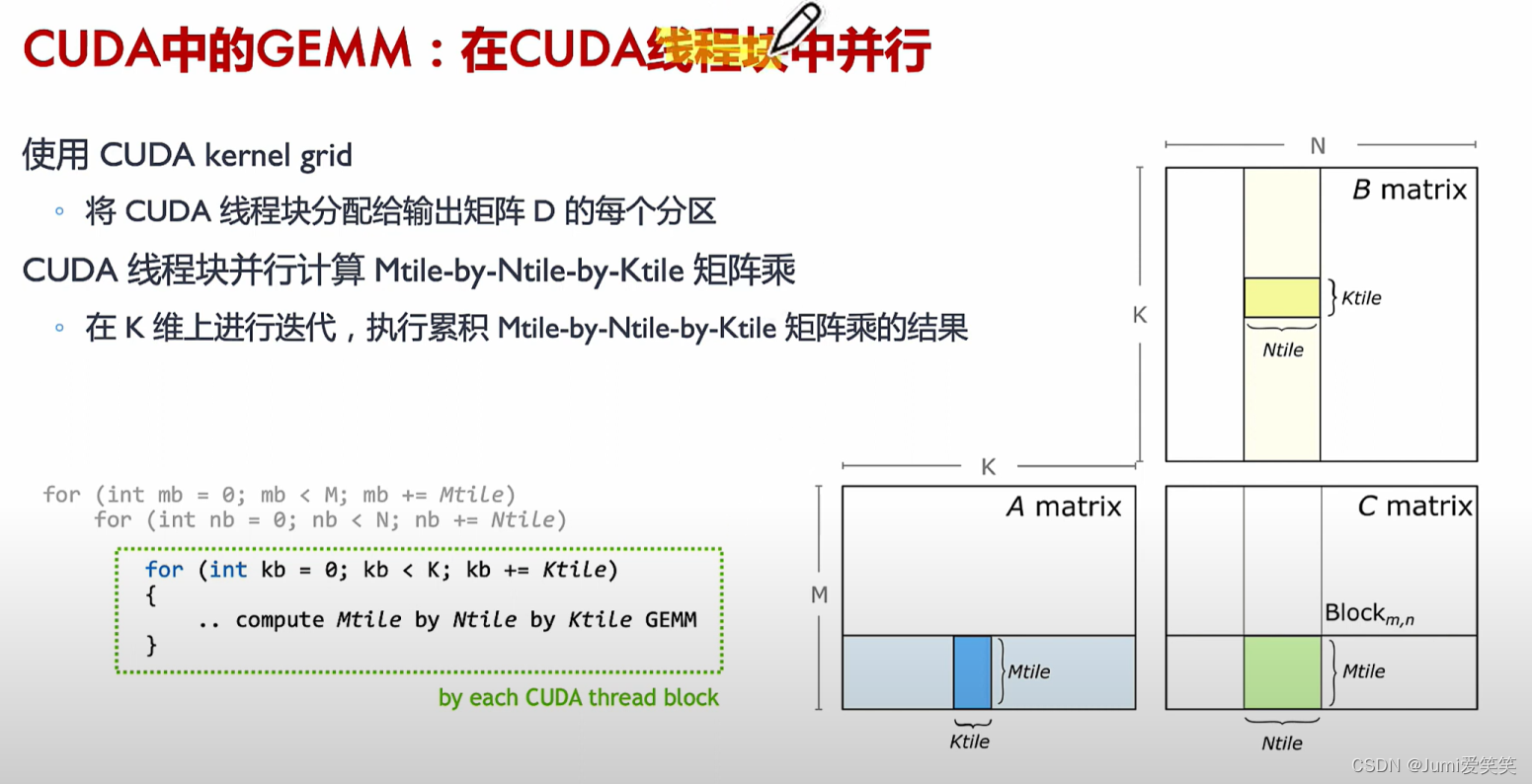
GEMM
GEMM指的是对于矩阵相乘的优化;针对不同的硬件架构和计算需求,有多种优化的GEMM实现,如基于CPU的优化、基于GPU的优化(使用CUDA、OpenCL等编程模型),以及专用的张量处理单元(TPU、NPU)等。这些优化方法通常利用并行计算、向量化指令和数据局部性等技术,以提高矩阵乘法的计算性能。
cuda core和Tensor core之间的区别
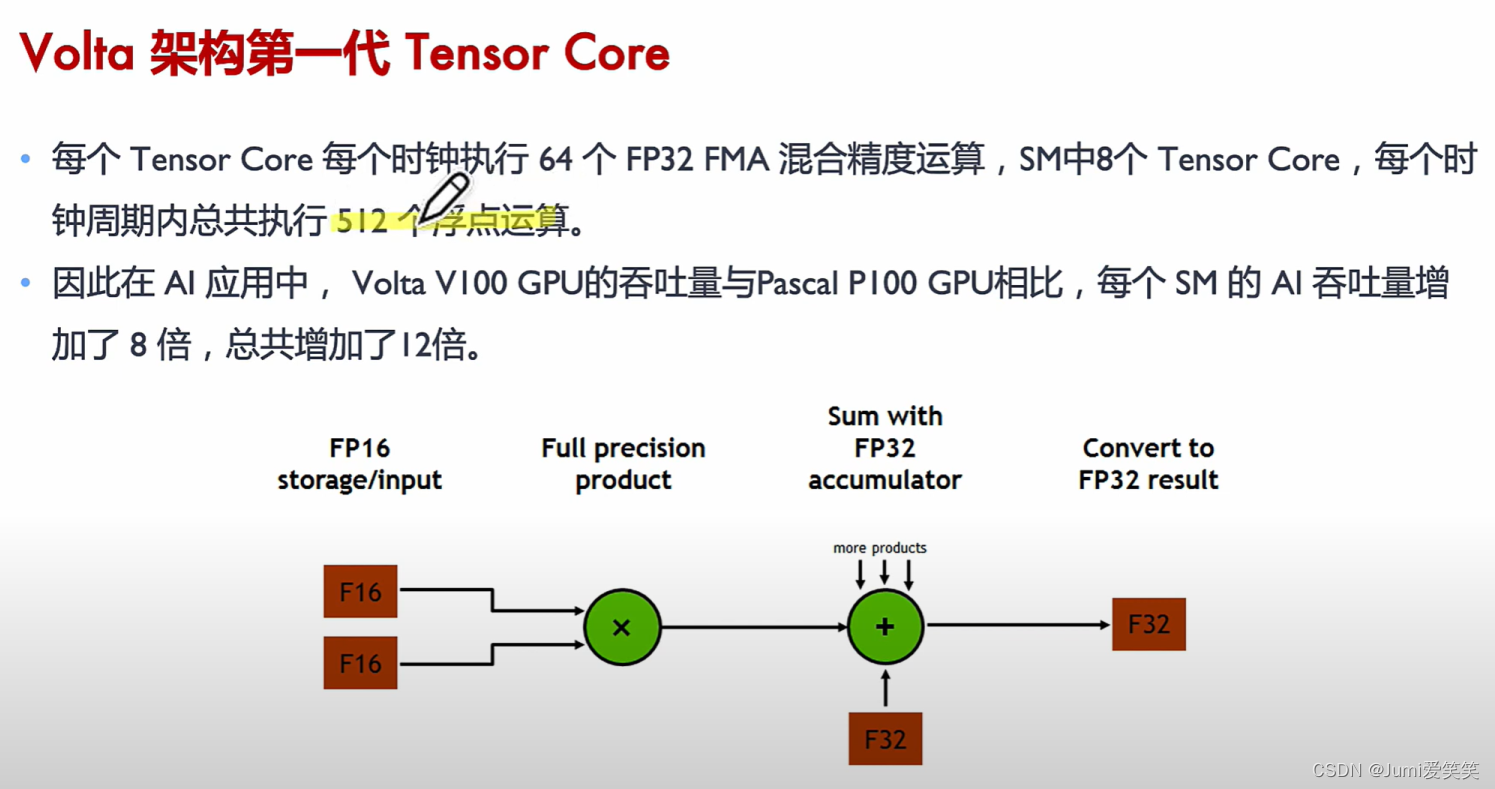
cuda core的话把乘和加分开执行,把数据放到寄存器,执行乘操作,得到的结果再放到寄存器,执行加操作,再将得到的结果放到寄存器;(ALU指的就是计算单元)

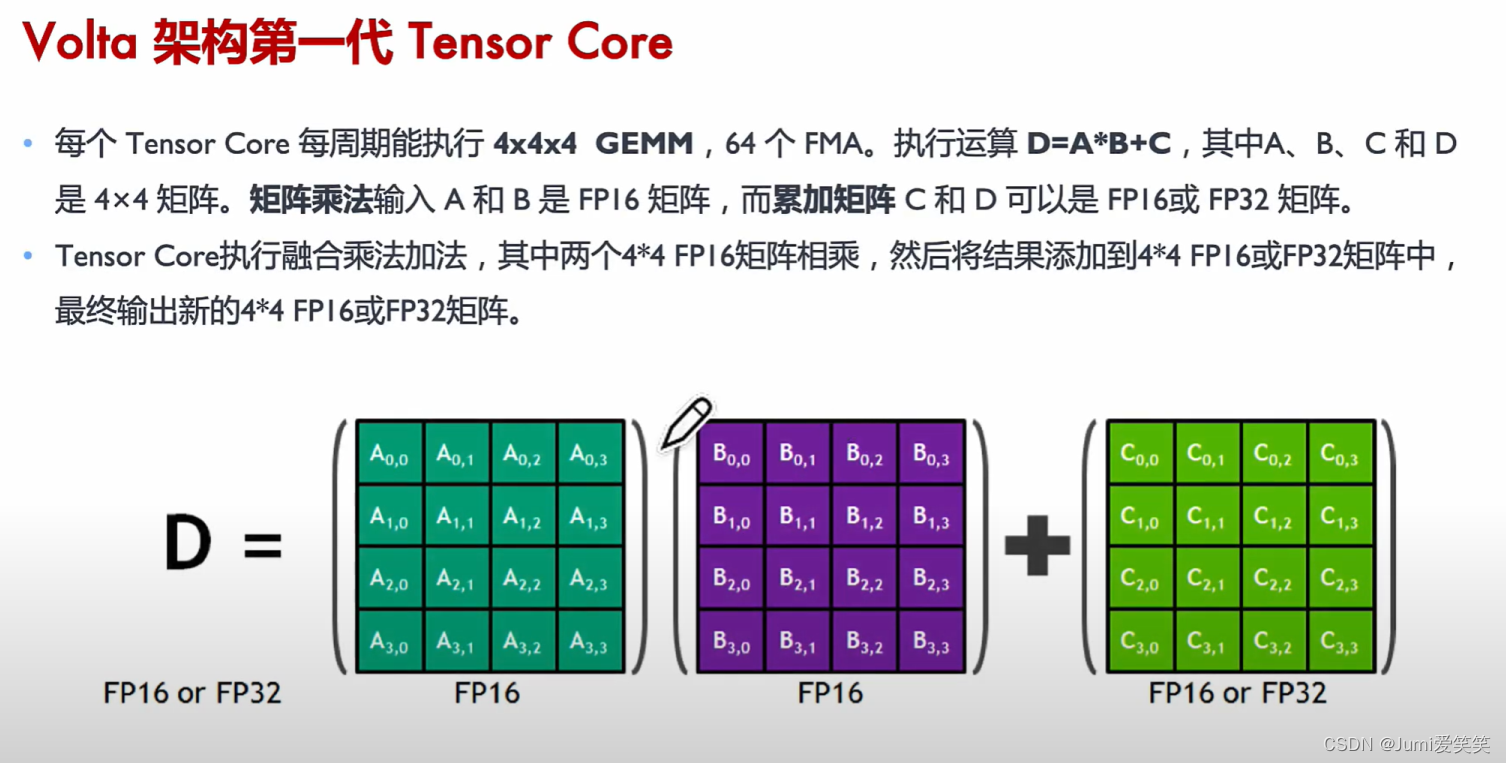
Tensor core处理的是4*4的矩阵
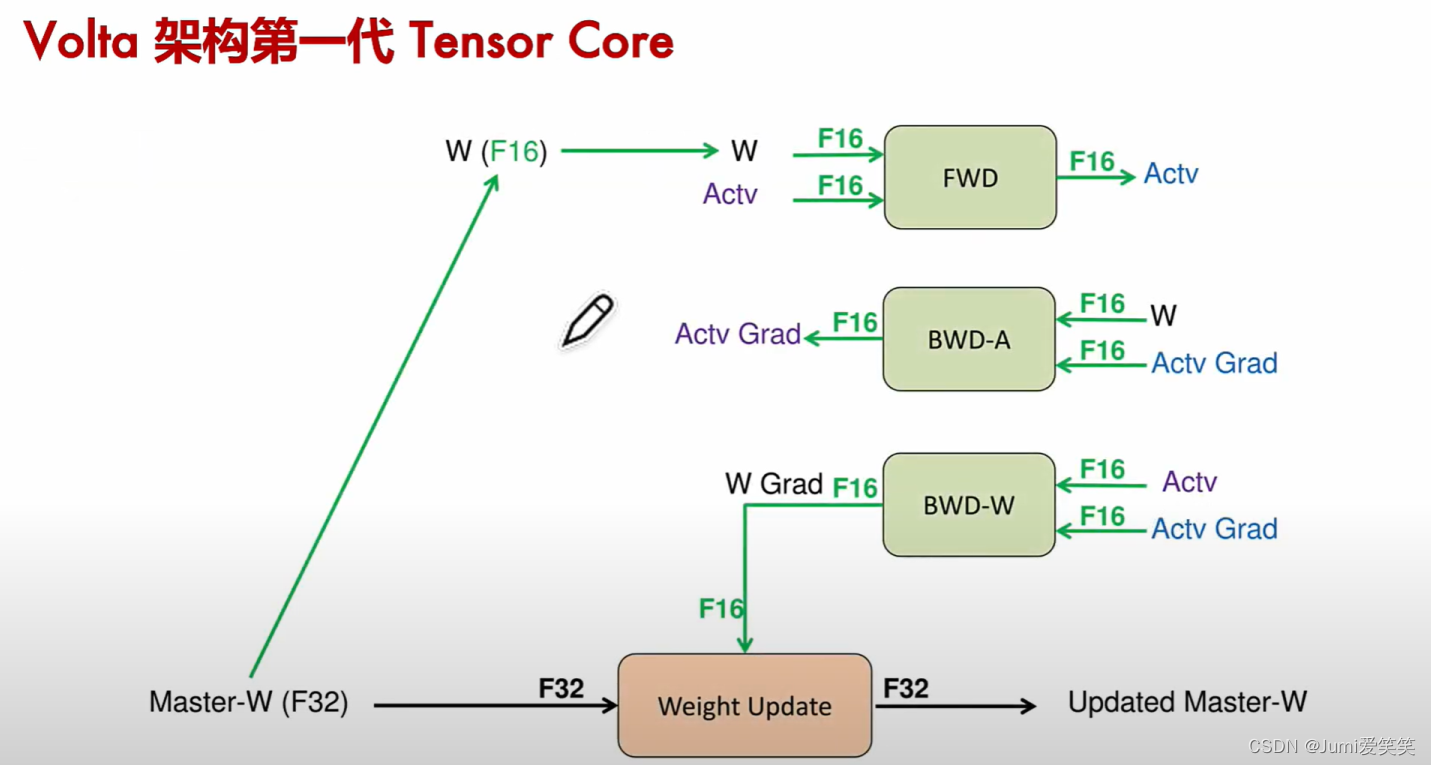
下图反应了反向传播的过程中梯度的计算用的是Fp16,但是对于参数的更新计算用的是Fp32~


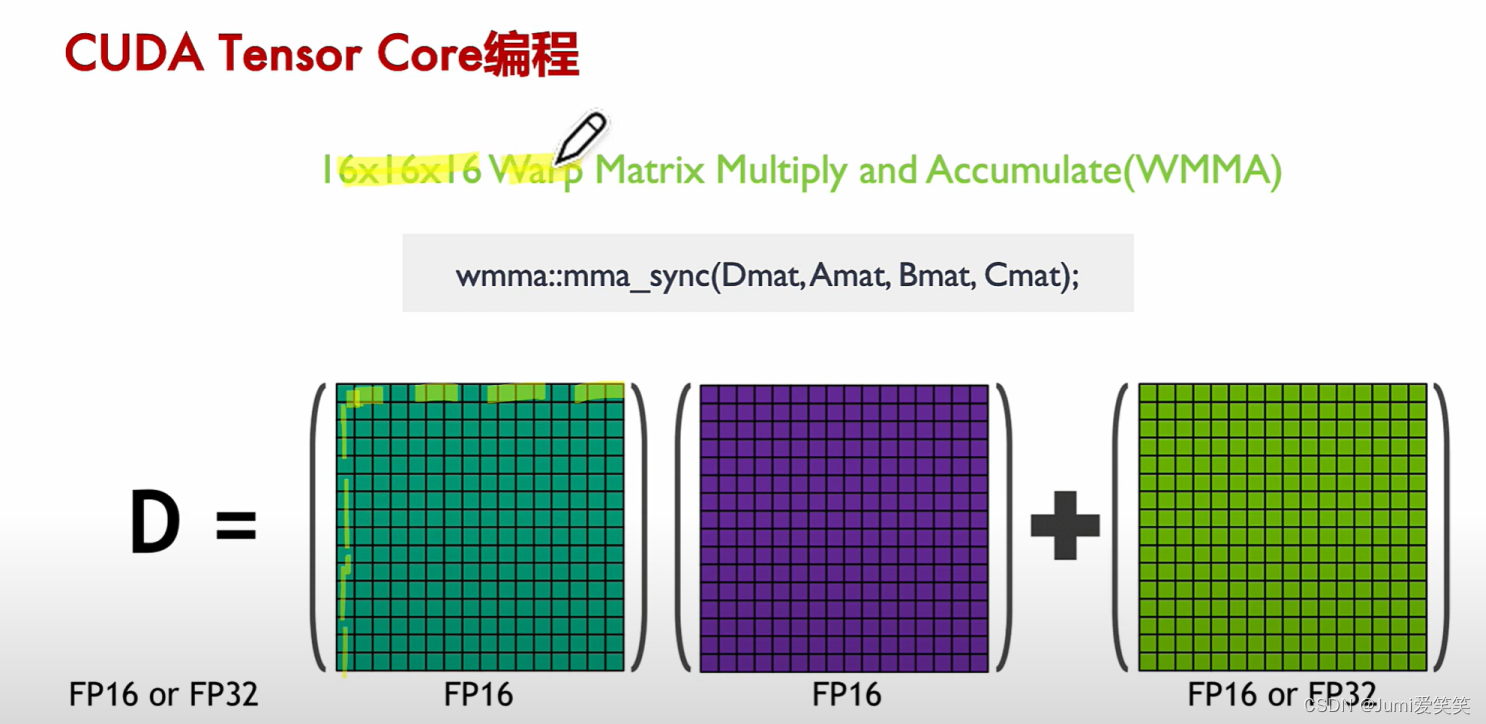
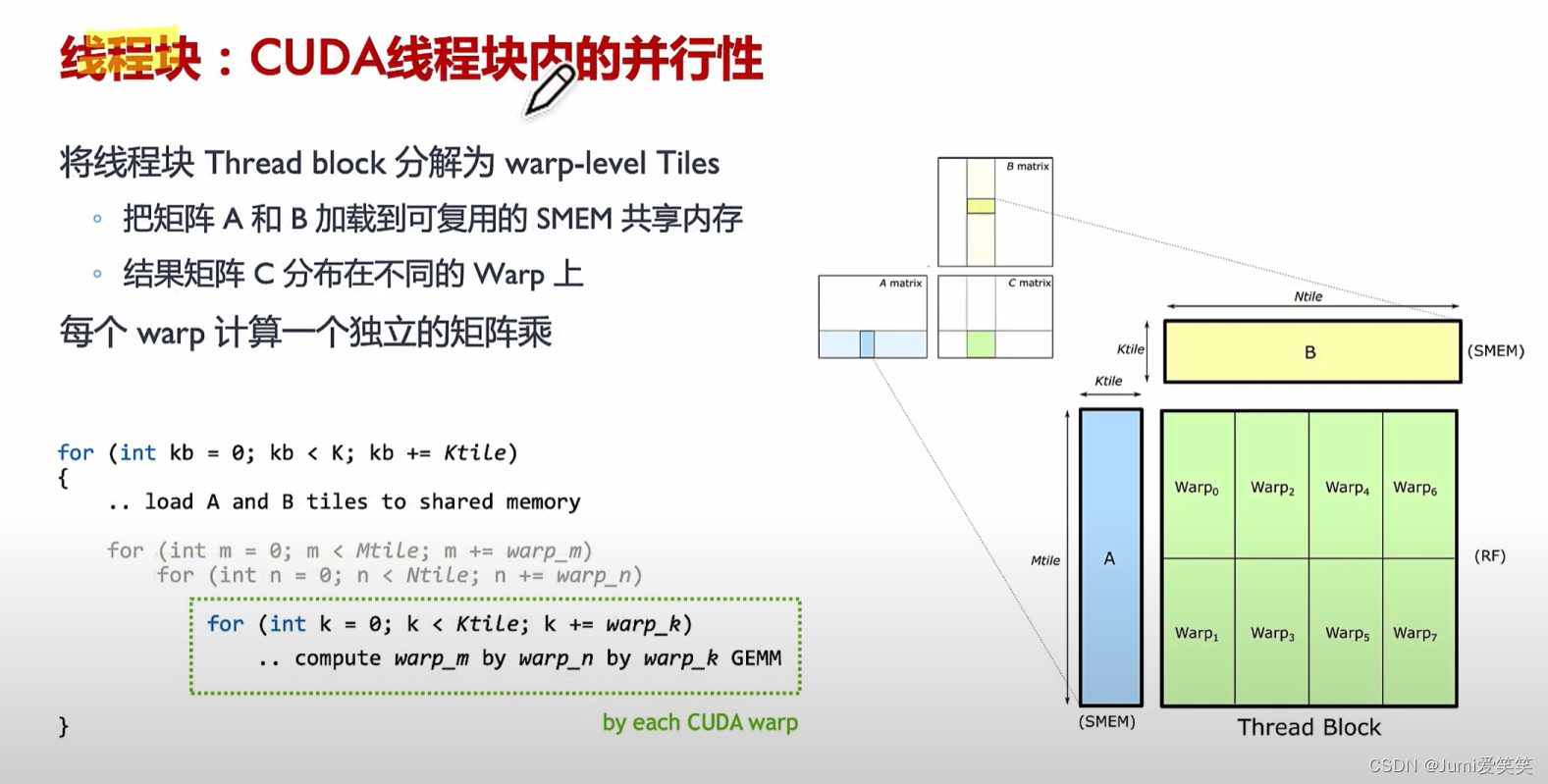
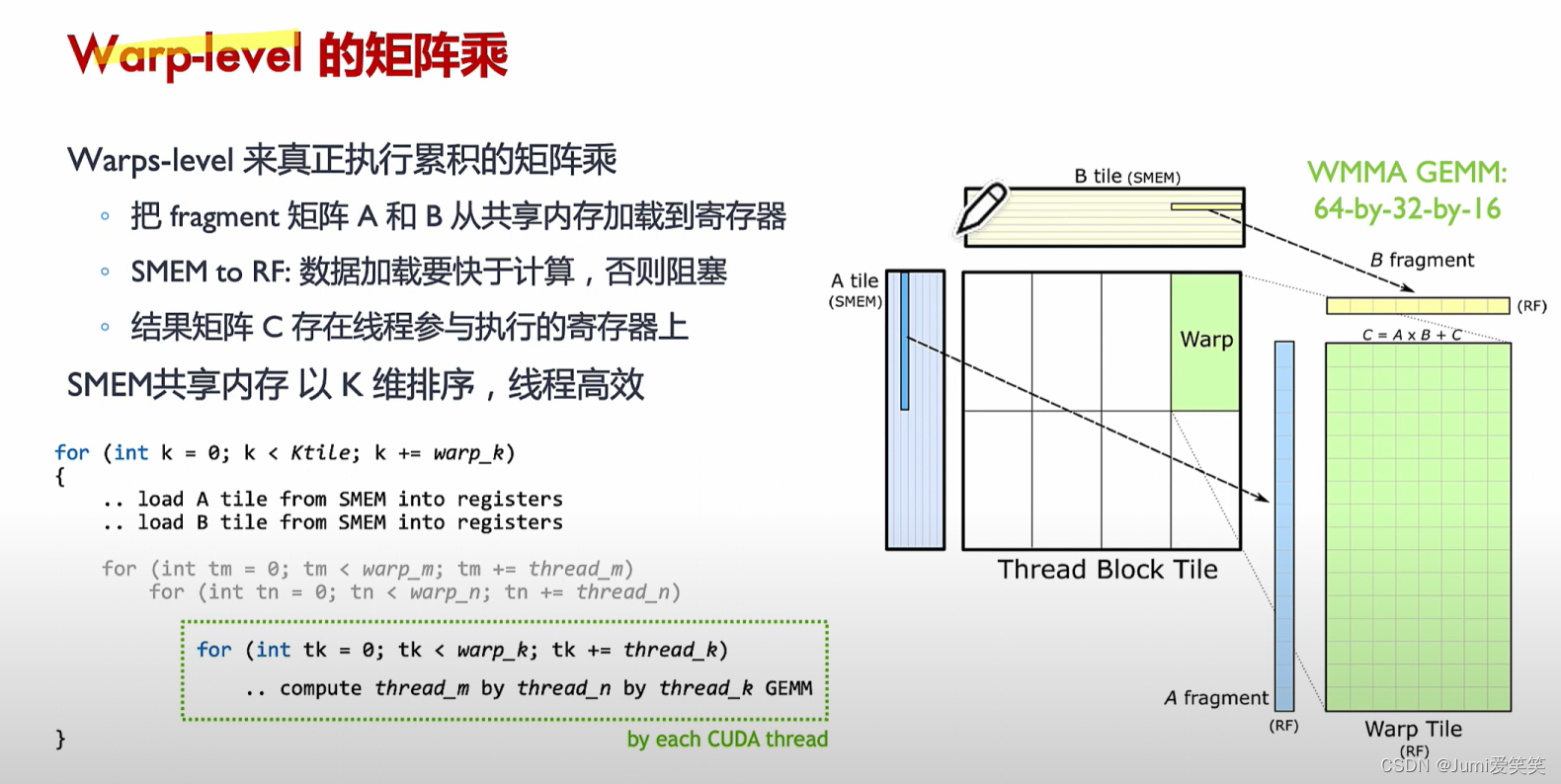
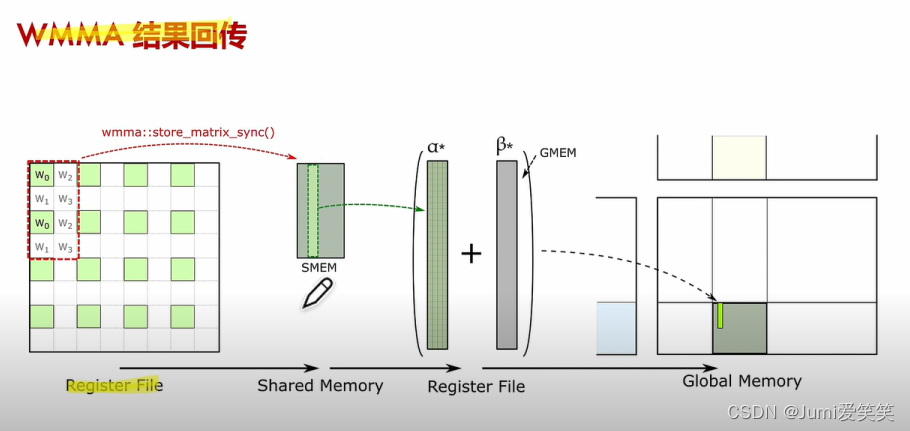
直接对于Tensorcore进行操作的话,颗粒度太小,所以把多个Tensorcore聚集起来放到一个wrap level的层面进行调度;
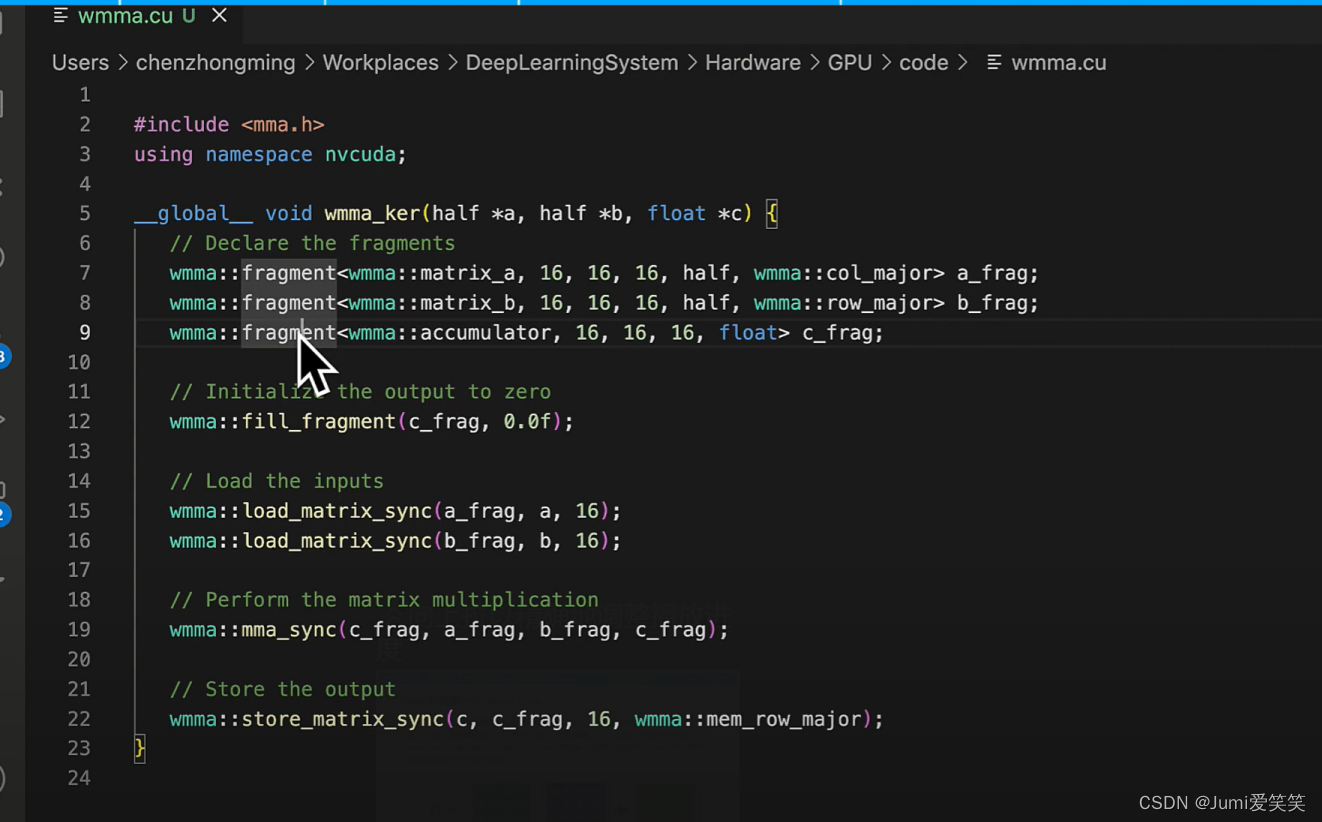
以下是一个执行cuda运算的基础例子:
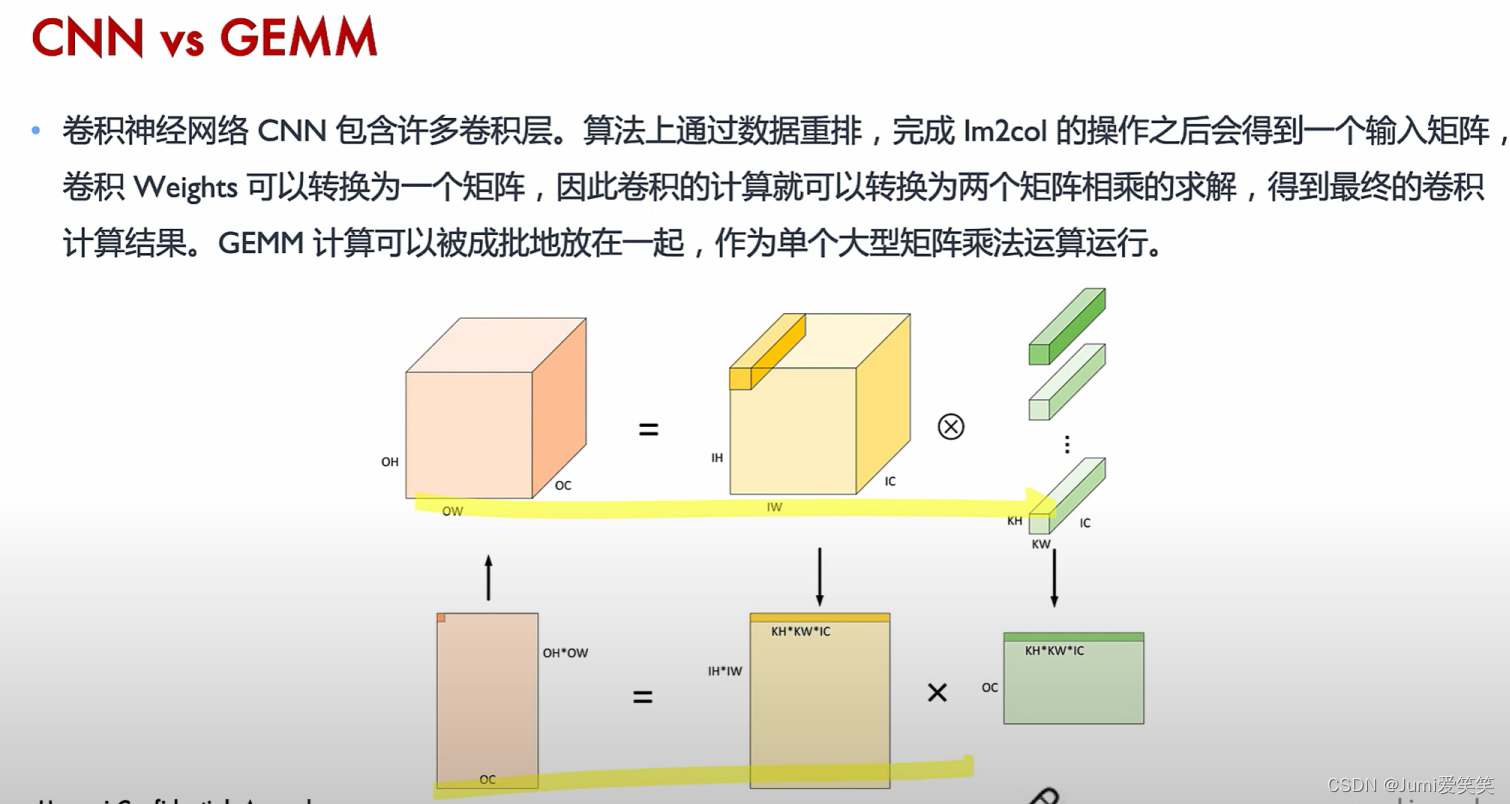
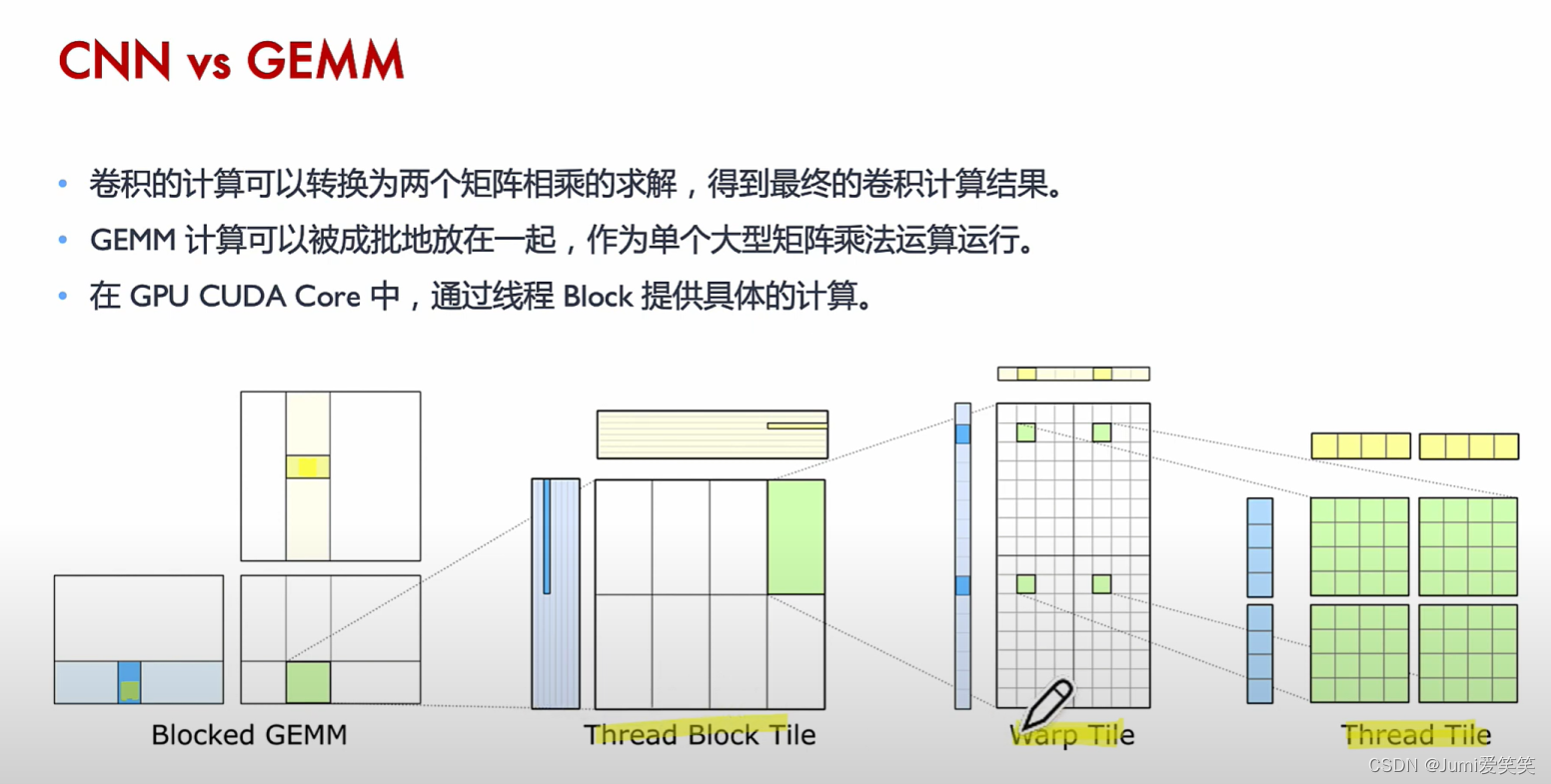
具体当输入图片是224224,卷积核的大小是77的时候,如何转换成底层的运算呢?
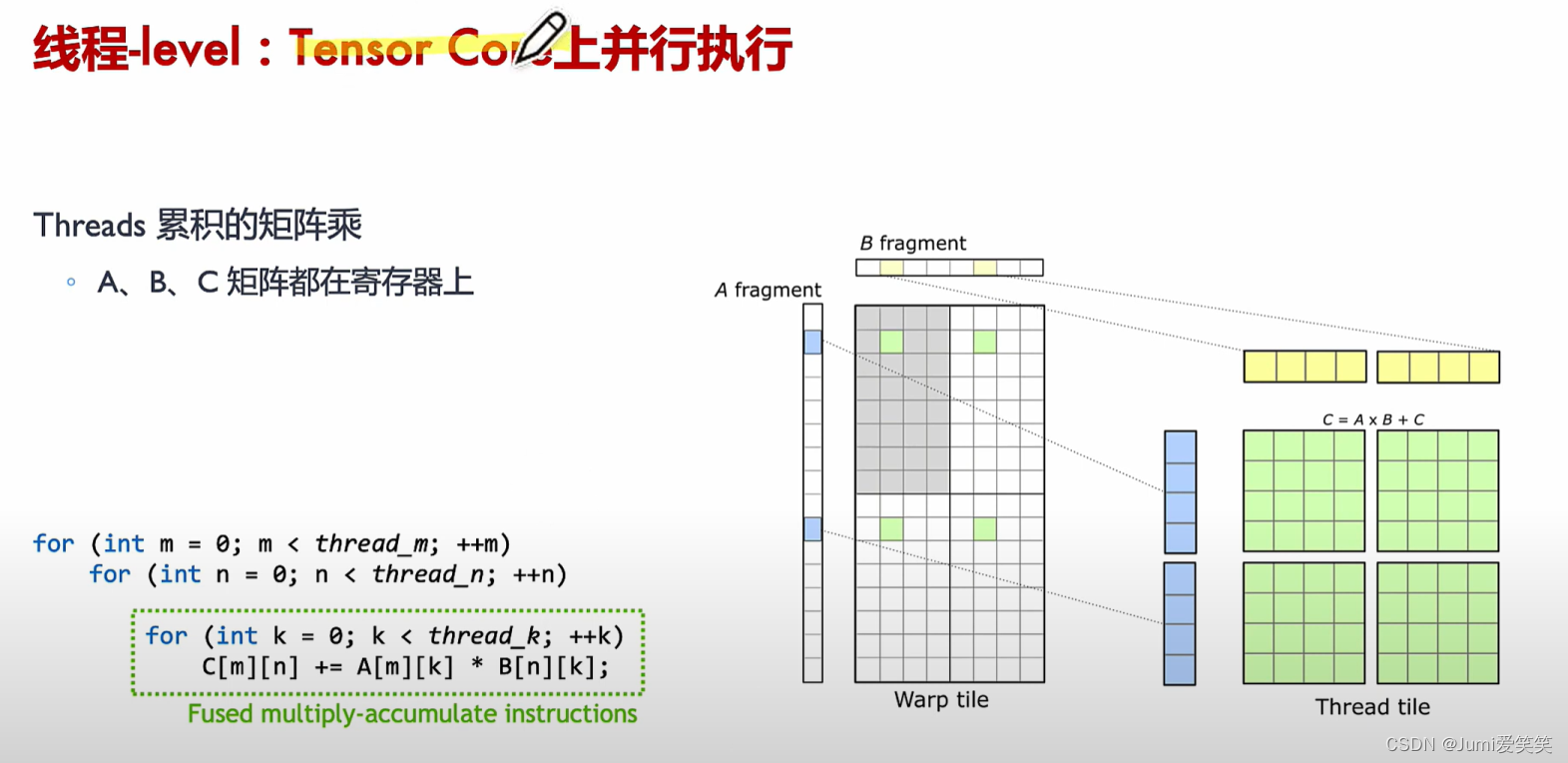
如下图,会将大的矩阵运算划分成一个个fragment,现在软件层面可以把它们划分到一个个thread block里面去,然后再warp调度,放在一个个Tensorcore去执行;
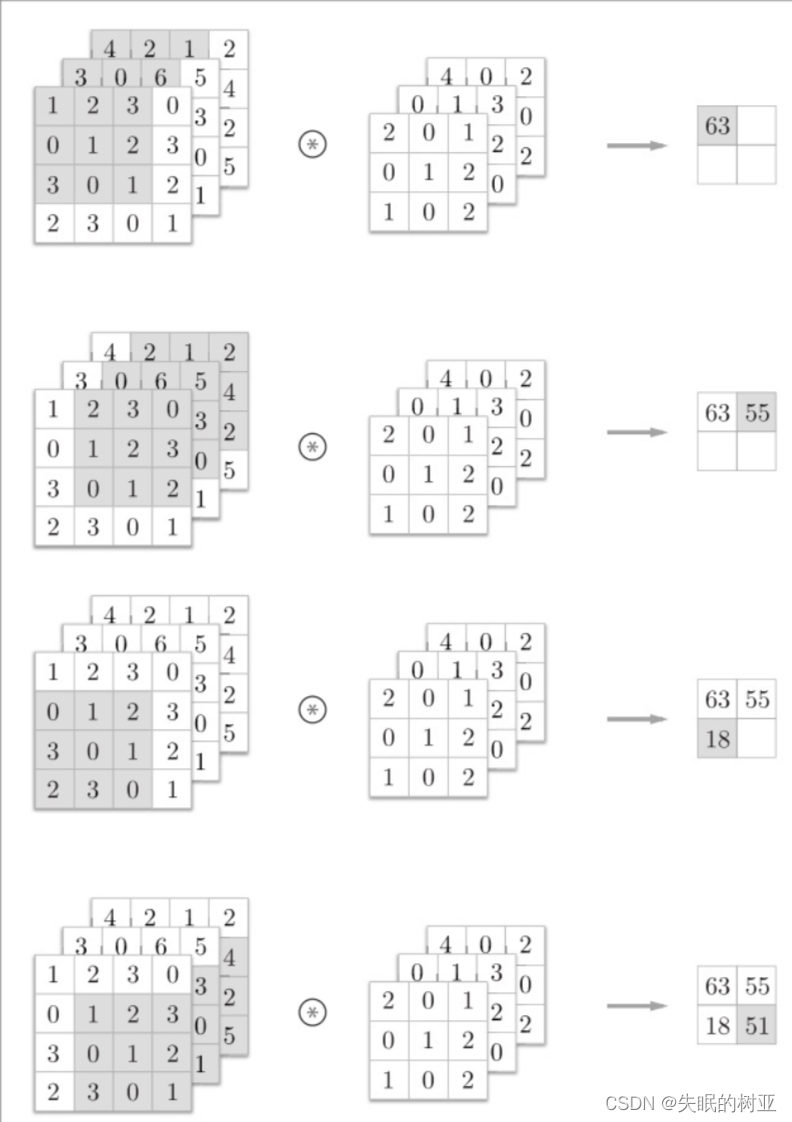
如下图所示,计算得到D某个元素的过程就是Tensorcore FMA指令的执行结果;

以下例子说明了GEMM矩阵相乘的具体执行过程,其会将大的矩阵块划分成一个个的fragment,每一个fragment的矩阵相乘对应一个thread
block,每一个thread block又可以划分成多个wrap,每一个wrap下面可以执行多个thread,每一个thread里面循环执行Tensor core的操作;