b站刘二老师pytorch深度学习课程:https://www.bilibili.com/video/BV1Y7411d7Ys?p=2&vd_source=b17f113d28933824d753a0915d5e3a90

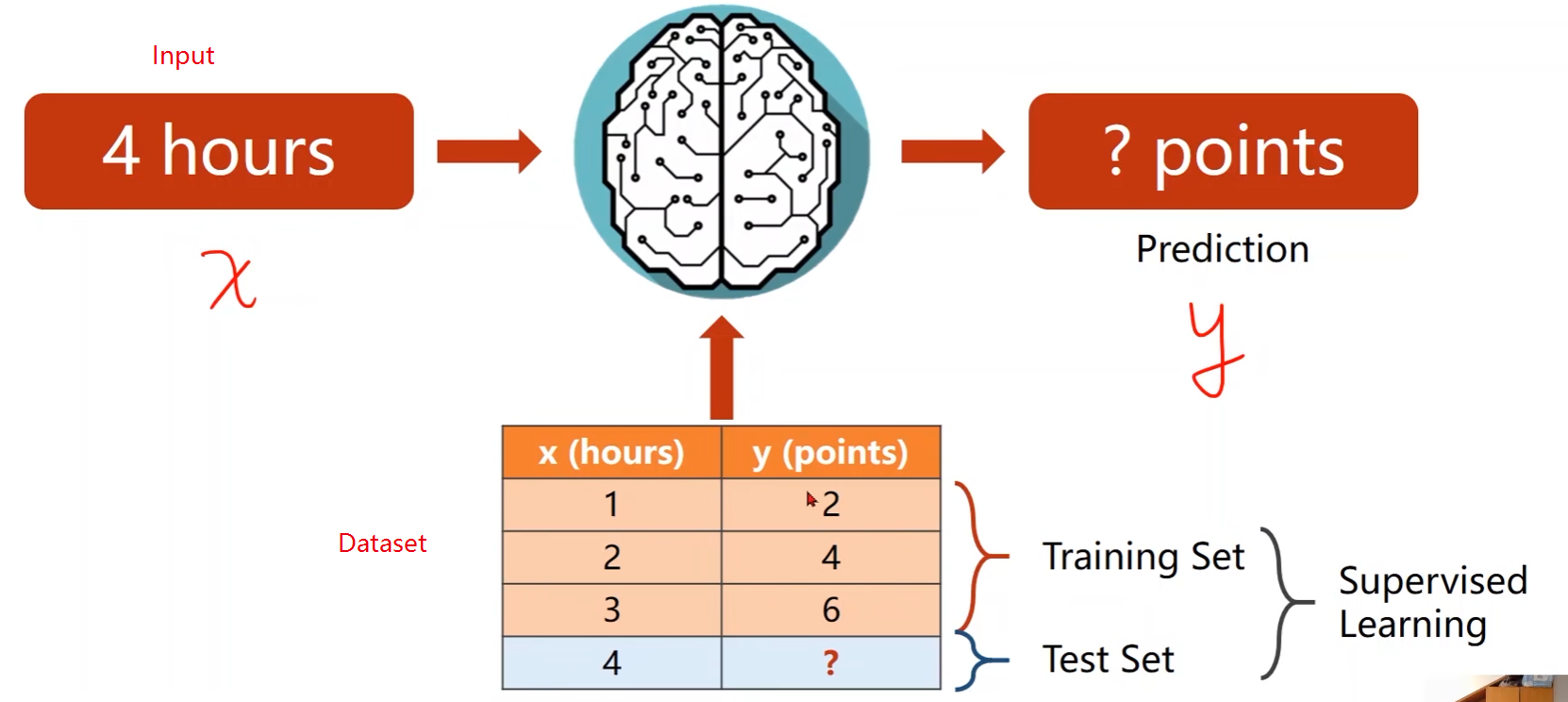
- 如果每周学习4个小时,那能够获得什么成绩?
- y已知的是采样得到的数据,属于训练集(training)
- y未知的是需要通过模型预测得到的,属于测试集(test)
机器学习的过程:
- 先把数据集(Data Set)交给算法进行训练
- 然后把新的输入(Input)输给训练好的算法,能够得到相应的预测(Prediction)结果
-
在上述问题中,输入是x,输出是y,在训练集中x和y的值都是已知的,该类问题也称为监督学习(Supervised Learning)。即在学习训练过程中,知道输入所对应的输出值是多少,那么就可以在训练过程中得到模型预测值和真实值之间的偏差,从而对模型进行调整,使得该偏差尽可能小。
-
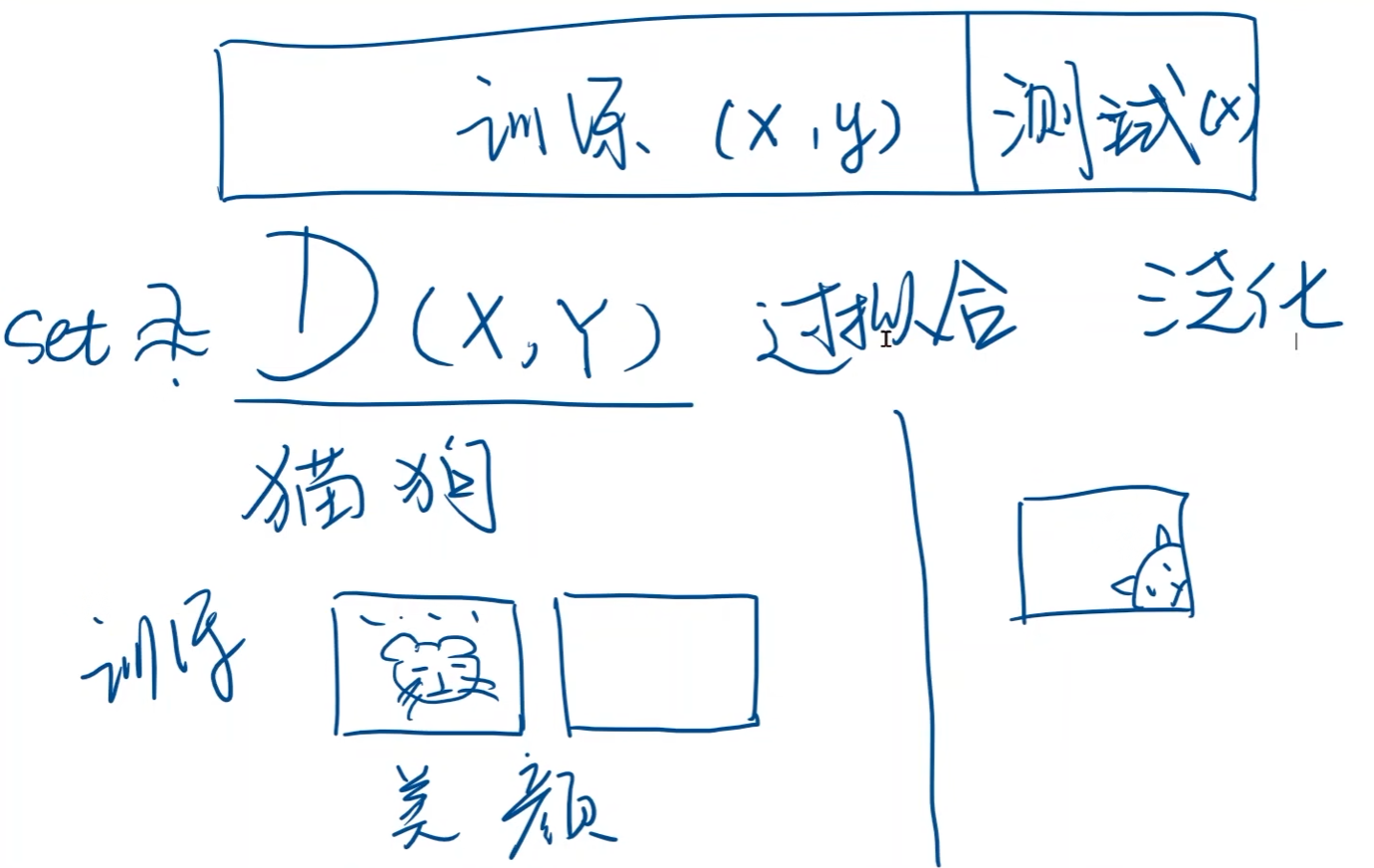
模型在训练好之后,都要先用测试集(test set)进行测试,以评估模型的性能。
-
overfitting,过拟合:模型在训练集上表现很好,但在测试集中表现较差,即泛化能力差
-
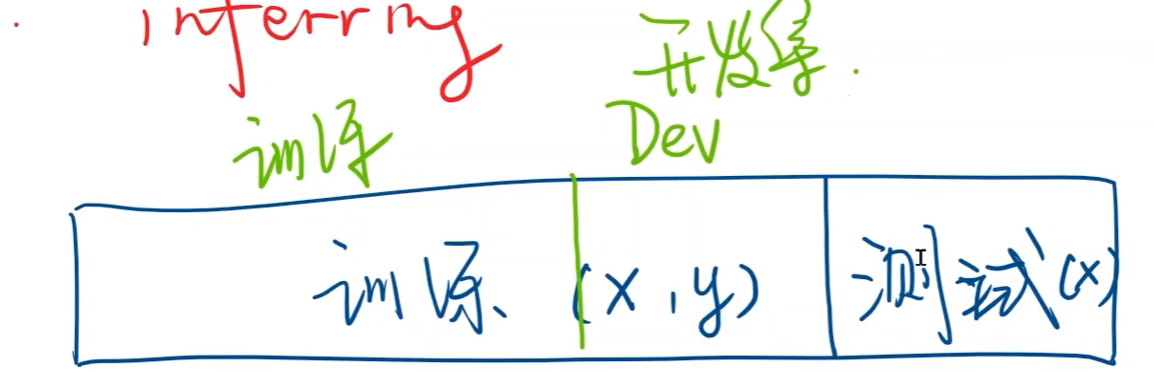
通常会将训练集再划分成两块,一块作为训练集,用于模型训练,另一部分作为开发集(验证集),用于模型的评估
- 如果模型训练后评估的性能比较好,则再将所有训练集数据再丢到模型中训练,然后再用测试集测试
-
模型设计:
-
要解决的问题:**对数据而言,什么样的模型是最合适的???**即 f ( x ) f(x) f(x)的形式是什么???
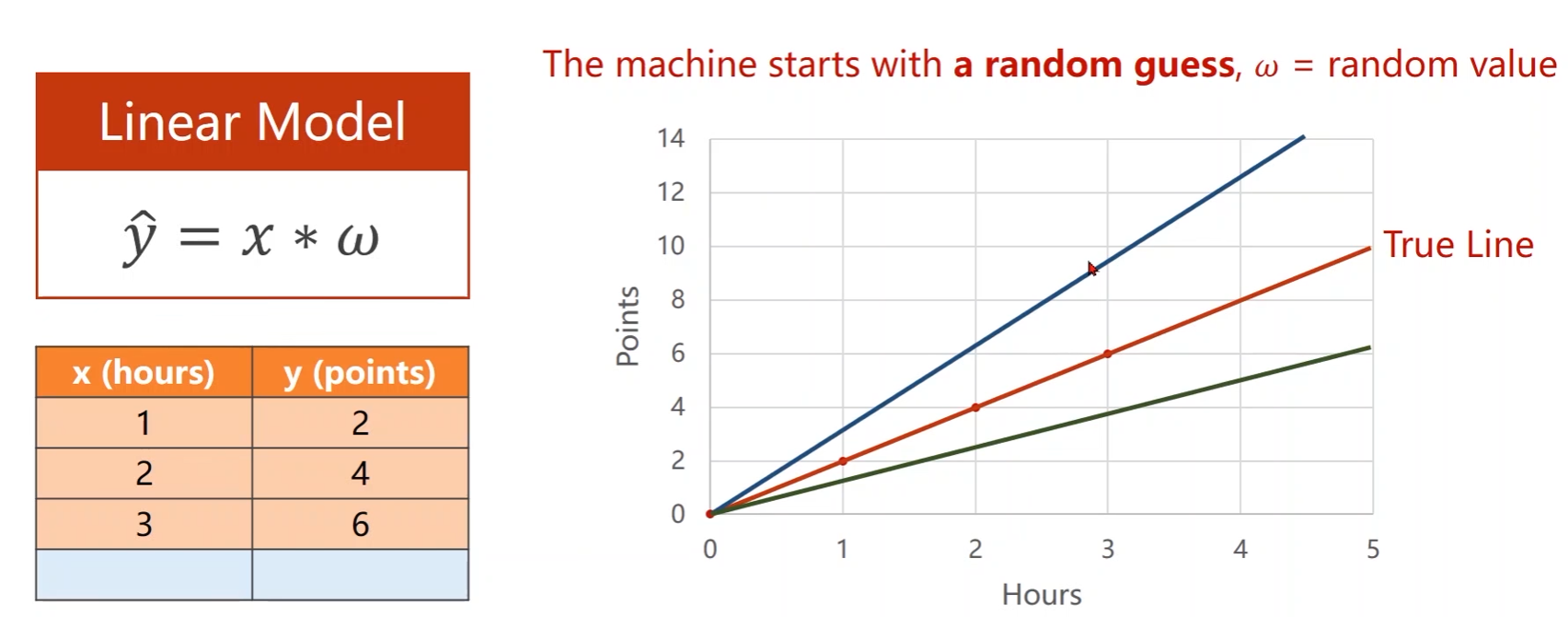
- 最基本的:线性模型

- 线性模型中,训练时关键的就是确定
w
w
w和
b
b
b的值
- w w w被称为权重, b b b称为偏置
对模型做一个简化,去掉截距 b b b
y ^ \hat{y} y^表示预测结果
-
不同的权重 w w w,曲线斜率不一样,那么该如何找到最优的权重值???
-
初始的时候是随机猜测,权重可能大可能小,不一定正好落在真实值,因此需要进行评估
-
当取了一个权重之后,它所表示的模型和数据集里面的数据之间的偏移程度有多大
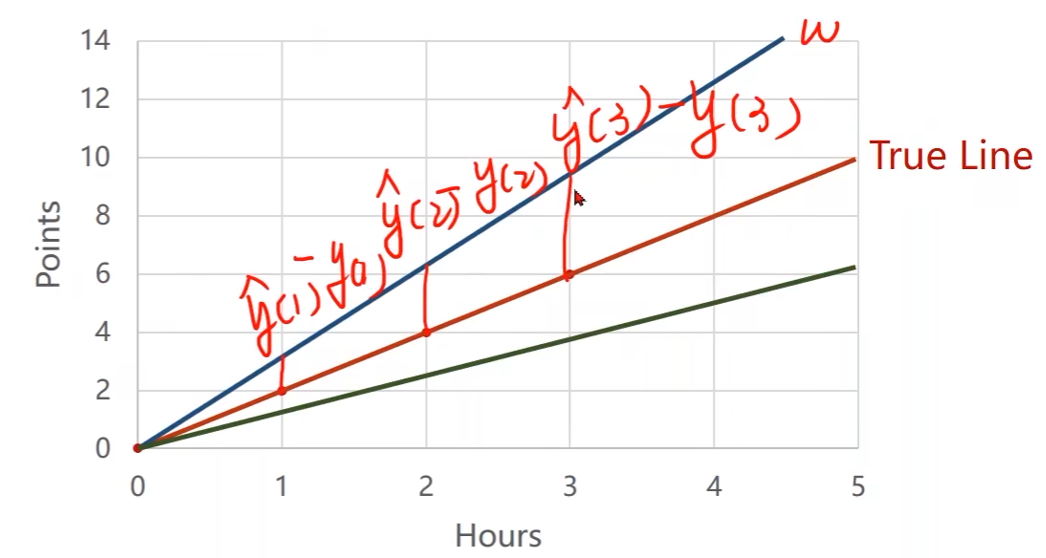
-
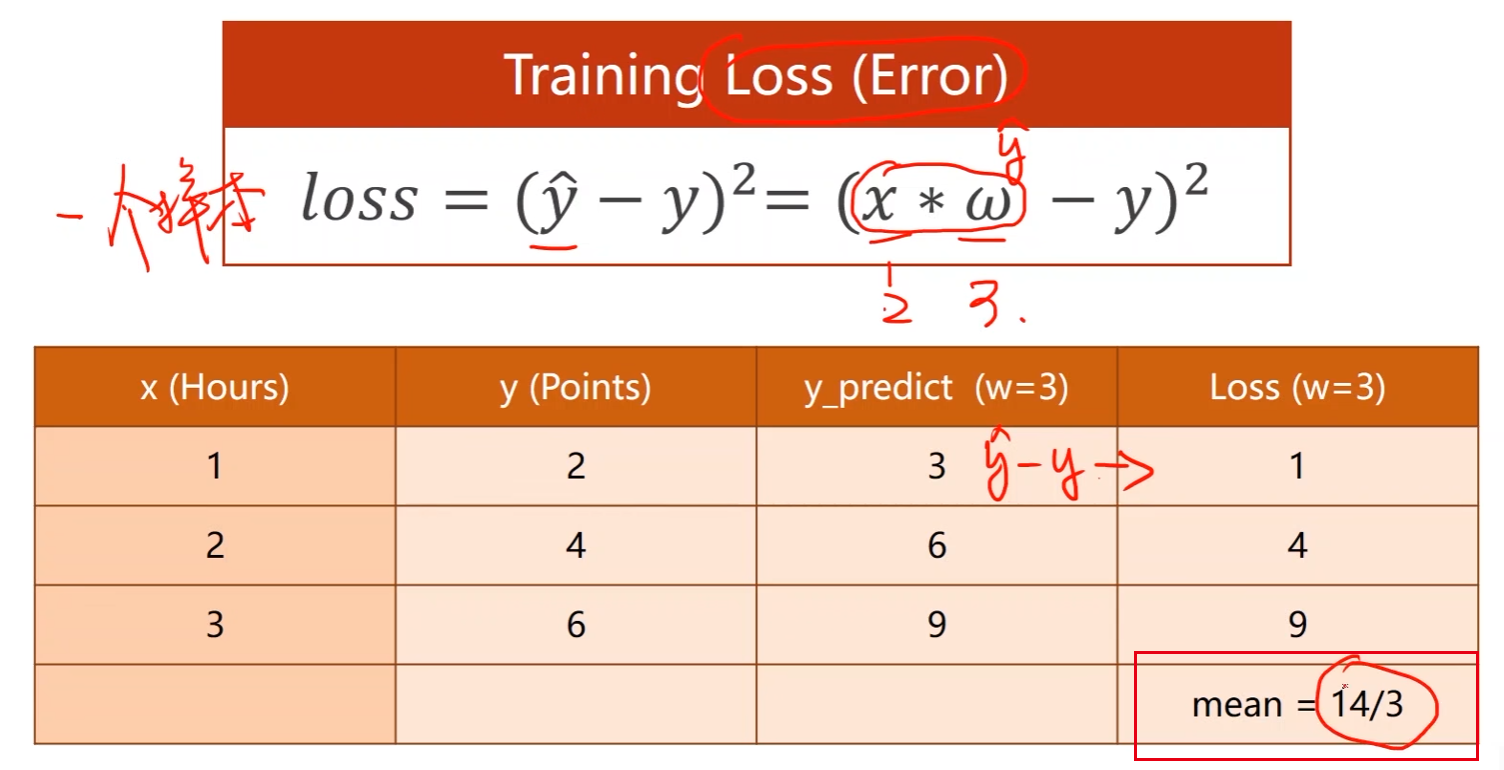
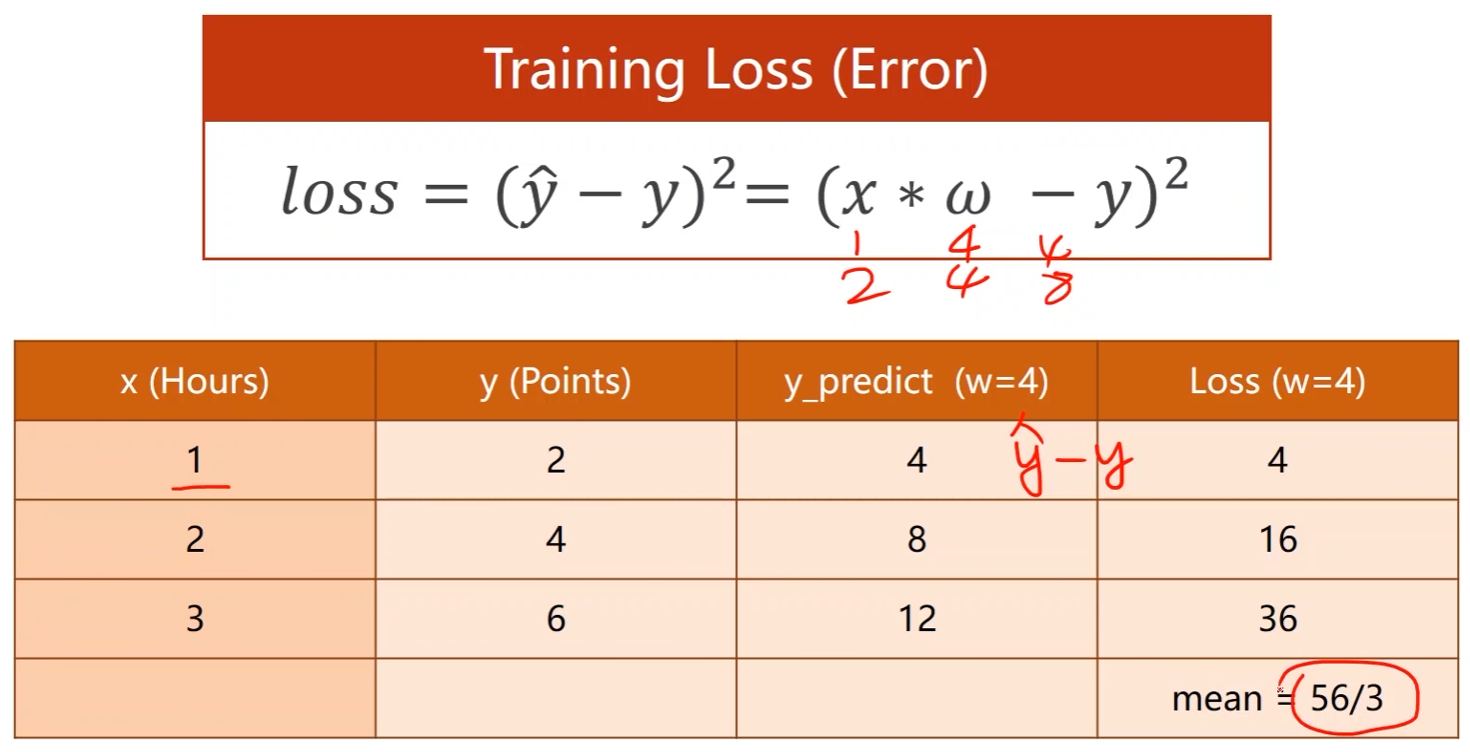
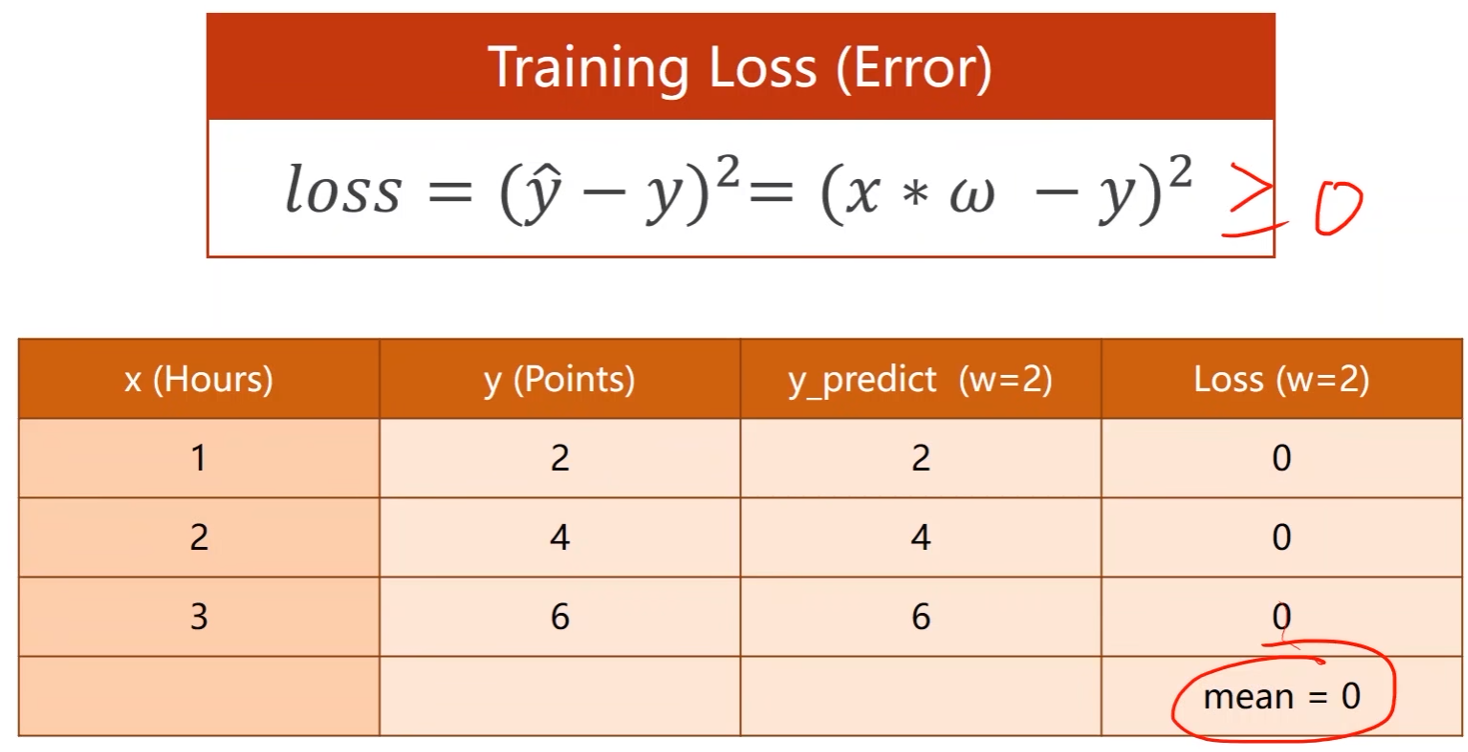
评估模型(loss):评估模型偏差
- 平均损失降到最低
-
-
-
如何找到合适的权重值,使得损失最小 ???
- 损失函数(Loss function)是针对一个样本的,对于整个训练集需要将每个样本的预测值和真实值求差然后计算均方根误差

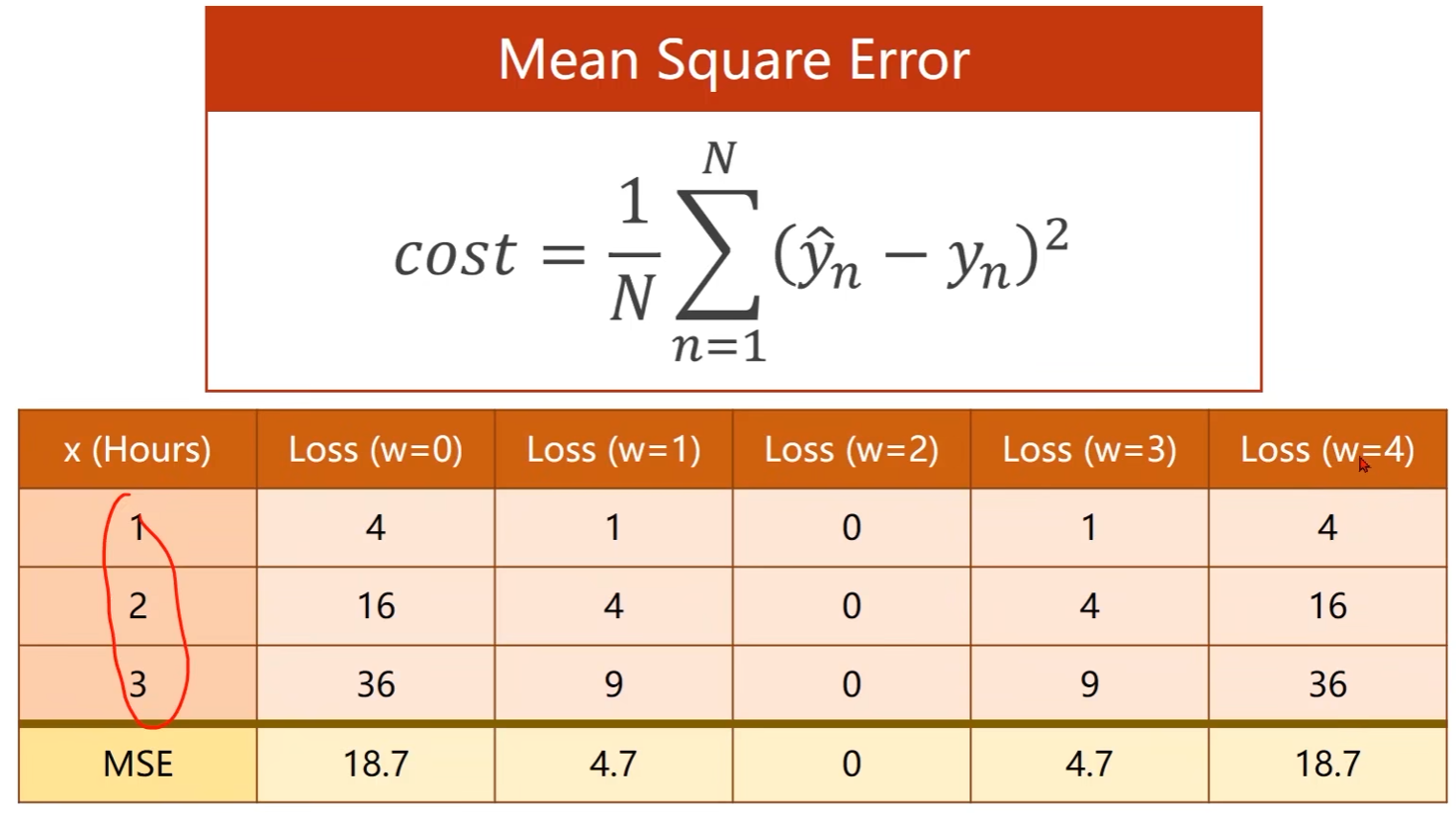
-
穷举法
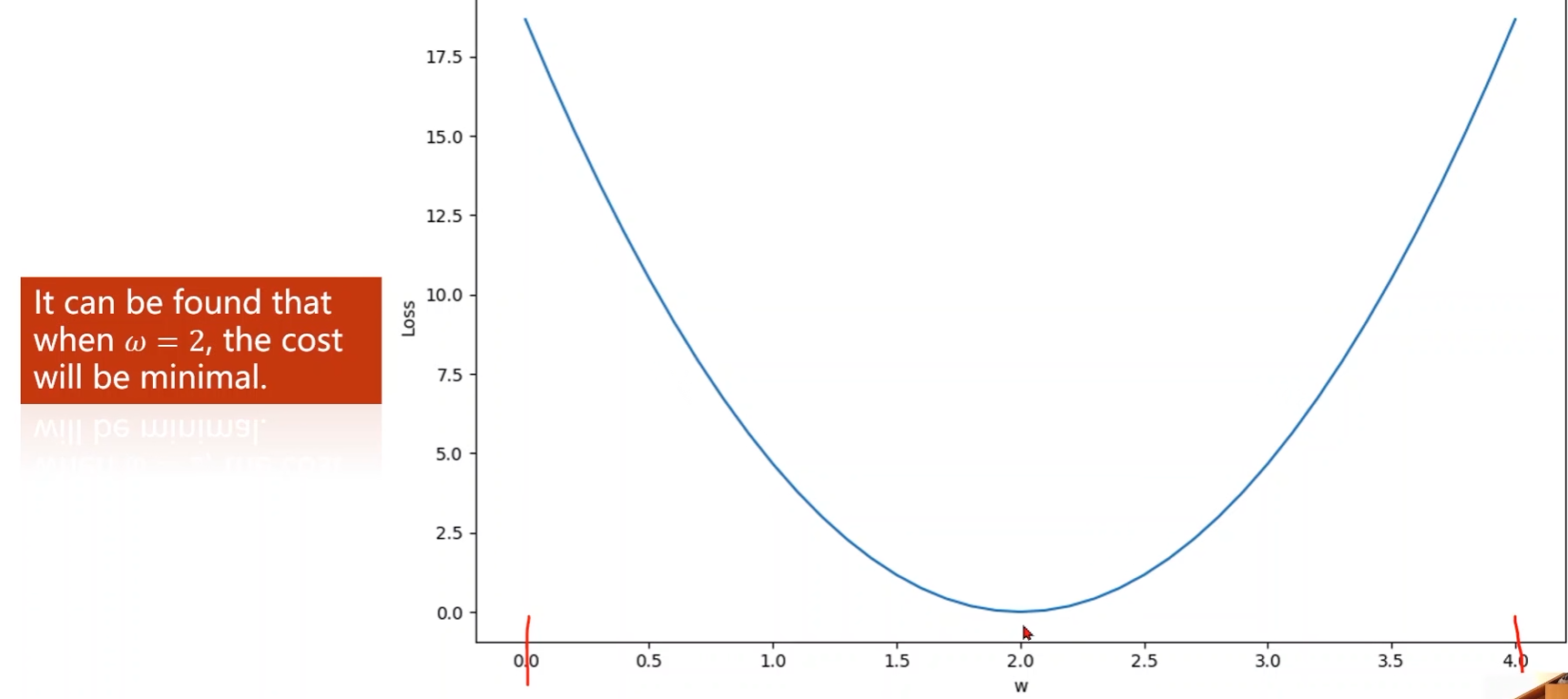
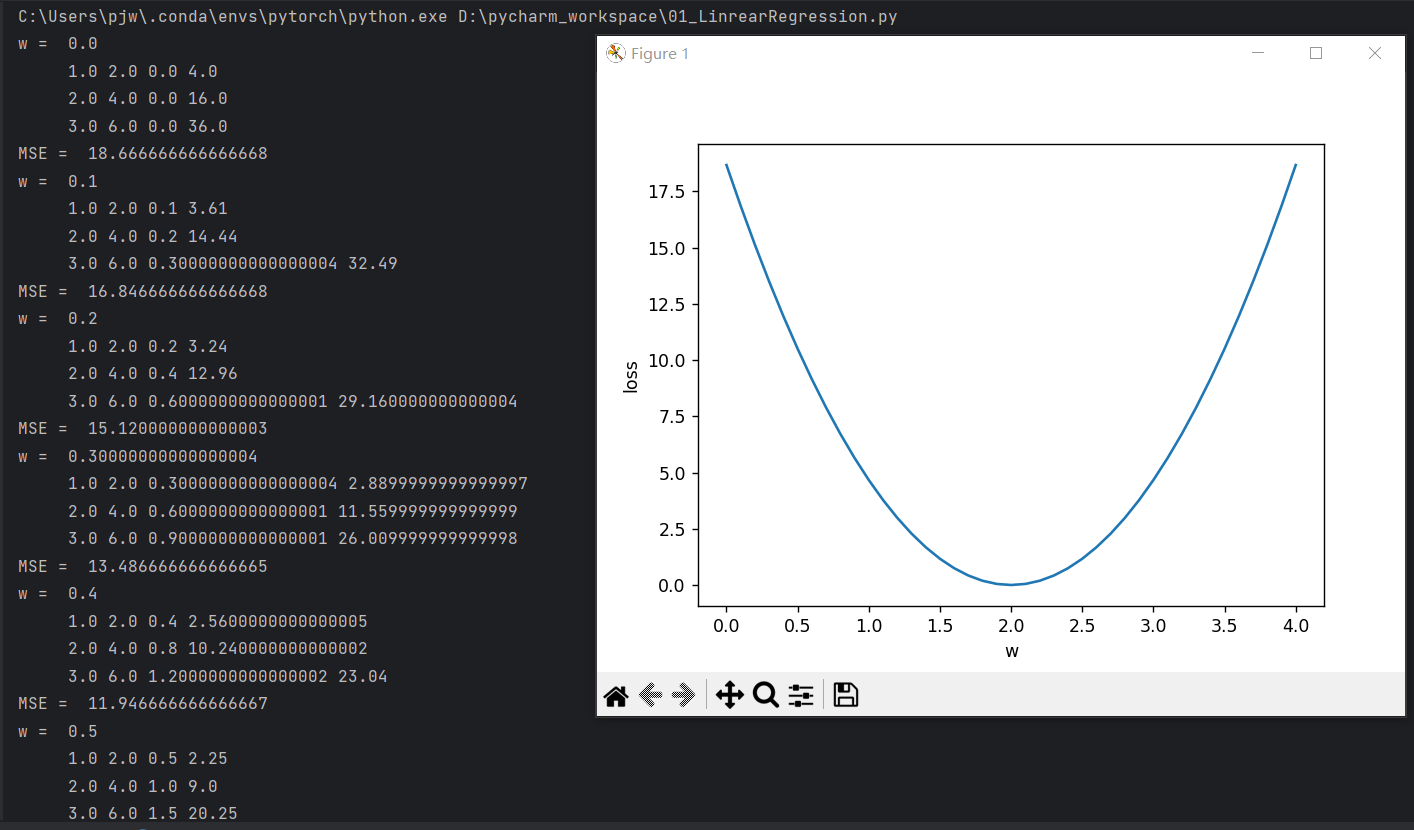
实践代码:
import numpy as np
import matplotlib.pyplot as plt
# 训练集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
# 定义模型:y_hat = x * w
return x * w
def loss(x, y):
# 定义损失函数loss function
y_pred = forward(x)
return (y_pred - y) * (y_pred - y) # (y_hat - y)的平方
# w_list存储每个权重值,mse_list存储每个权重值对应的损失值
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
# 权重w在0到4.1之间进行采样,采样间隔为0.1,[0.0, 0.1, 0.2, ..., 4.0]
print("w = ", w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
# 遍历训练集中的每一个样本,并计算每个样本的损失值
# zip用法:https://blog.csdn.net/qq_45766916/article/details/125960493
# zip(numbers, letters)创建一个生成 (x, y) 形式的元组的迭代器,[(numbers[0], letters[0]),…,(numbers[n], letters[n])]
y_pred_val = forward(x_val) # x_val的预测值
loss_val = loss(x_val, y_val) # x_val的损失值
l_sum += loss_val # 叠加每个样本的损失值(此处不是求均值)
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE = ', l_sum / 3) # 计算得到权重值w对应的损失值
w_list.append(w) # 将权重w添加到w_list中
mse_list.append(l_sum / 3) # 将权重w对应的损失值添加到mse_list中
# loss曲线绘制,x轴是权重w,y轴是loss值,即表示每个权重值w对应的loss值
plt.plot(w_list, mse_list)
plt.ylabel('loss')
plt.xlabel('w')
plt.show()
-
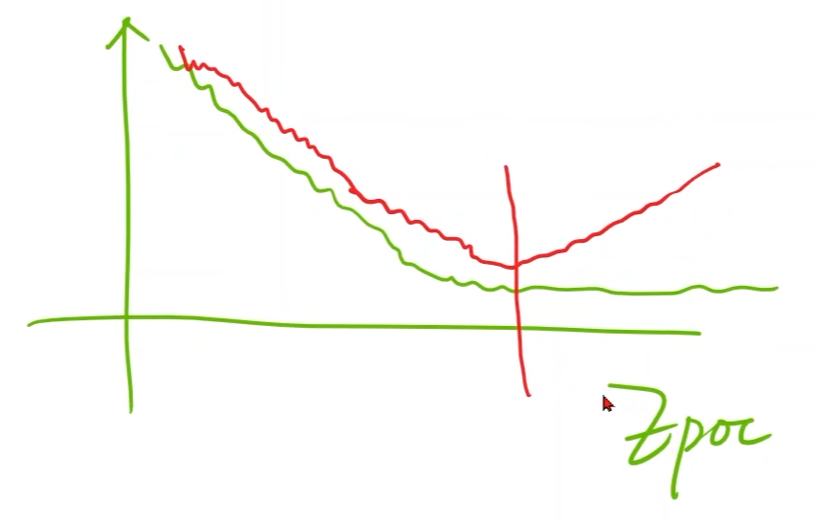
在深度学习中做训练的时候,loss曲线中一般不是用权重来做横坐标,而是训练轮数(epoch)
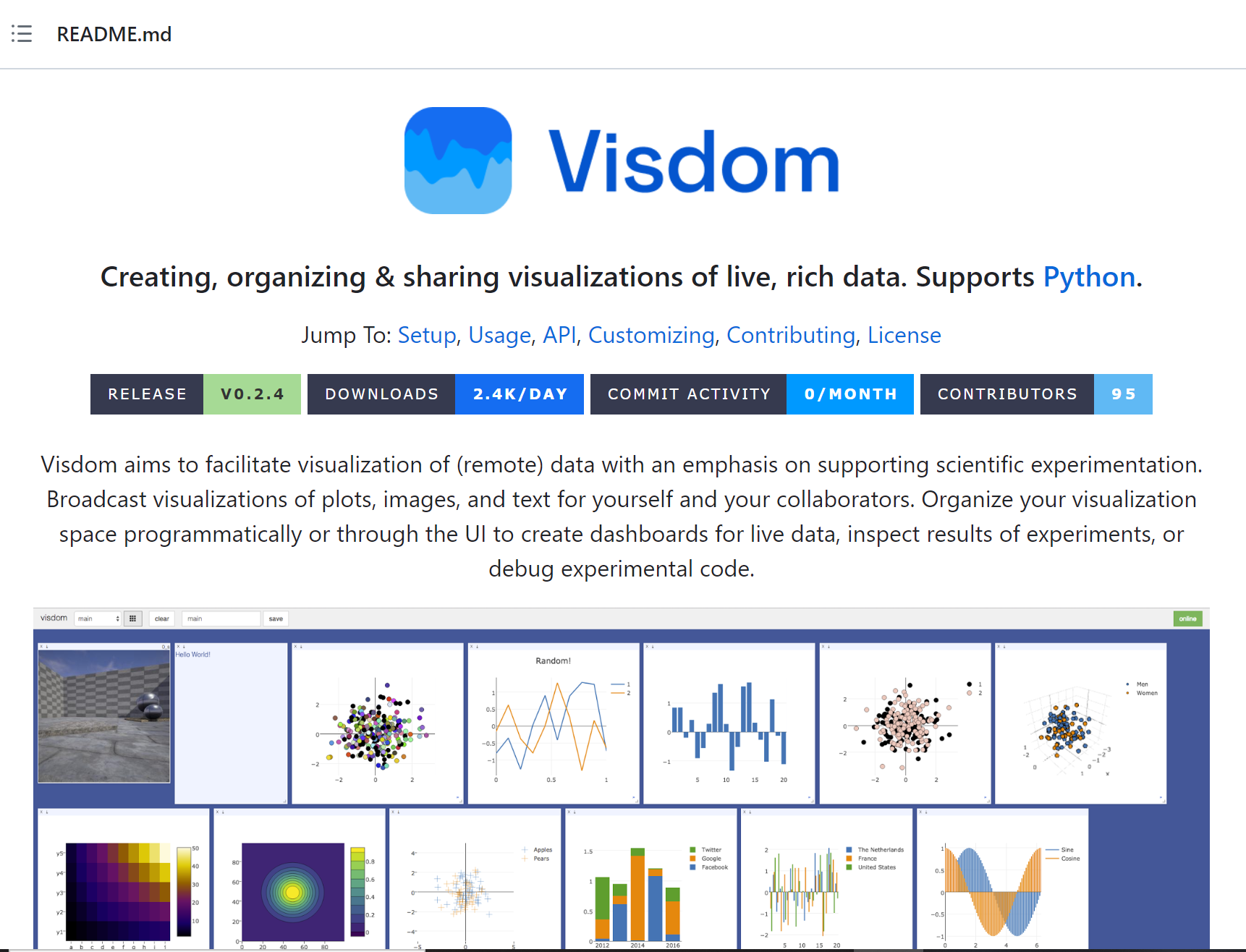
visdom:可视化工具包
- https://github.com/fossasia/visdom