文章目录
- 一、前言
- 二、主要内容
- 1. 评估
- 2. 时间线
- 3. 奖金
- 4. 代码要求
- 三、总结
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、前言
使用机器学习技术,通过匿名健康特征的测量数据来检测疾病。
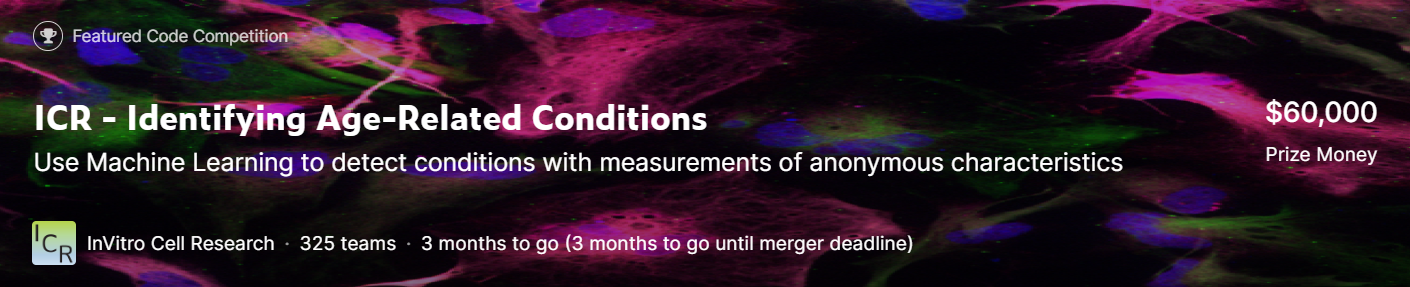
比赛目标
本次比赛的目标是预测一个人是否患有三种医疗状况中的任何一种。您需要预测这个人是否患有其中一种或多种医疗状况(类别 1),或者没有这三种医疗状况之一(类别 0)。您将创建一个基于健康特征的测量数据训练的模型。
要确定某人是否患有这些医疗状况,需要进行长时间和侵入性的过程来收集患者信息。而通过预测模型,我们可以通过收集与该情况相关的关键特征,然后对这些特征进行编码来缩短此过程并保持患者详细信息私密。
您的工作将帮助研究人员发现某些特定特征的测量值与可能存在的患者状况之间的关系。
比赛背景
他们说年龄只是一个数字,但随着年龄的增长,会带来一系列健康问题。从心脏病和痴呆症到听力丧失和关节炎,衰老是许多疾病和并发症的风险因素。生物信息学这个不断发展的领域包括对能够帮助减缓、逆转生物衰老并预防主要与年龄相关的疾患干预措施的研究。数据科学可以在开发解决具有多样化数据问题的新方法方面扮演一定角色,即使样本数量很少。
目前,像 XGBoost 和随机森林这样的机器学习模型被用于预测医疗情况,但是它们的表现还不够好。在处理涉及生命安全的关键问题时,模型需要可靠地、一致性地做出正确的预测。成立于 2015 年的比赛主办方 InVitro Cell Research,LLC (ICR) 是一家私人资助公司,专注于再生和个性化预防医学。他们在纽约市区拥有最先进的研究空间。InVitro Cell Research 的科学家是他们与众不同之处,在帮助引导和定义他们研究如何快速修复老龄化人群方面发挥着重要作用。
在本次比赛中,您将使用健康特征的测量数据来解决生物信息学中的关键问题。基于最少训练,您将创建一个模型来预测一个人是否患有三种医疗状况中的任何一种,并旨在改善现有方法。您可以帮助推动生物信息学领域的发展,并探索解决具有多样化数据复杂问题新方法。
This is a Code Competition. Refer to Code Requirements for details.
关键词:表格数据、医疗健康、二分类、机器学习、平衡对数损失
二、主要内容
1. 评估
提交的结果将使用平衡对数损失进行评估。总体效果是每个类别对于最终得分都大致相等。每个观测值都属于 1 类或 0 类。对于每个观测值,您必须提交每个类别的概率。公式如下:
Log Loss
=
−
w
0
N
0
∑
i
=
1
N
0
y
0
i
log
p
0
i
−
w
1
N
1
∑
i
=
1
N
1
y
1
i
log
p
1
i
w
0
+
w
1
\text { Log Loss }=\frac{-\frac{w_{0}}{N_{0}} \sum_{i=1}^{N_{0}} y_{0 i} \log p_{0 i}-\frac{w_{1}}{N_{1}} \sum_{i=1}^{N_{1}} y_{1 i} \log p_{1 i}}{w_{0}+w_{1}}
Log Loss =w0+w1−N0w0∑i=1N0y0ilogp0i−N1w1∑i=1N1y1ilogp1i
- N 0 N_{0} N0 和 N 1 N_{1} N1 分别是类别 0 和类别 1 观察样本的数量; l o g log log 是自然对数; y c i y_{ci} yci 是 1 如果第 i i i 个样本的类别标签属于 1,否则为 0。
- p c i p_{ci} pci 是第 i i i 个样本属于类别 c c c 的预测概率,权重 w 0 w_{0} w0、 w 1 w_{1} w1 等于该类别样本数量的反比例。
在得分之前,给定行的提交概率不需要总和为 1 ,因为它们会被重新缩放(每行都会除以行总和)。为了避免对数函数的极端情况,每个预测概率 p p p 都被替换为: max ( min ( p , 1 − 1 0 − 15 ) , 1 0 − 15 ) \max \left(\min \left(p, 1-10^{-15}\right), 10^{-15}\right) max(min(p,1−10−15),10−15)。
提交文件。对于测试集中的每个 id,您必须预测两个类别中每个类别的概率。该文件应包含表头,并具有以下格式:
| Id | class_0 | class_0 |
|---|---|---|
| 00eed32682bb | 0.5 | 0.5 |
| 010ebe33f668 | 0.5 | 0.5 |
| 02fa521e1838 | 0.5 | 0.5 |
| 040e15f562a2 | 0.5 | 0.5 |
| 046e85c7cc7f | 0.5 | 0.5 |
2. 时间线
2023 年 5 月 11 日 - 开始日期。
2023 年 8 月 3 日 - 报名截止日期。您必须在此日期之前接受比赛规则才能参加比赛。
2023 年 8 月 3 日 - 团队合并截止日期。这是参与者加入或合并团队的最后一天。
2023 年 8 月 10 日 - 最终提交截止日期。
所有截止时间均为相应当天 UTC 时间晚上 11:59,除非另有说明。如果比赛组织者认为必要,他们保留更新比赛时间表的权利。
3. 奖金
第一名 - $18000
第二名 - $15000
第三名 - $10000
第四名 - $7000
第五名 - $5000
第六名 - $5000
4. 代码要求
这是一场代码比赛。参赛作品必须通过 Notebooks 提交。为了在提交后激活 “提交” 按钮,必须满足以下条件:
- CPU Notebook <= 9 小时运行时间。
- GPU Notebook <= 9 小时运行时间。
- 禁用互联网访问(Notebook 是离线测试的)。
- 提交文件名必须命名为 submission.csv。
请查看代码竞赛 FAQ 以获取更多有关如何提交的信息。如果遇到提交错误,请查阅代码调试文档。
三、总结
Kaggle 链接:https://www.kaggle.com/competitions/icr-identify-age-related-conditions
ICR 比赛的目标是预测一个人是否患有三种医疗状况中的任何一种。您需要预测这个人是否患有其中一种或多种医疗状况(类别 1),或者没有这三种医疗状况之一(类别 0)的概率。创建一个基于健康特征的测量数据训练的模型,提交 notebook 评测。
在这样一个小数据集上使用机器学习算法是一项非常困难的任务。很容易出现过拟合问题,训练集分布和测试集分布之间的差异,以及潜在的特征工程。需要一些 Leaderboard 探测策略来弄清楚训练集分布和测试集分布之间的关系。但是,如何进行探测呢?我们应该关注哪些指标(标准差、均值等)?
为了有效探测,可以用表现最佳的 notebook(目前是 0.08)并在测试集(未标记)上进行预测。将这些预测用作伪标签,它们将是对真实标签的最佳近似。由于这个近似相当不错,您可以将这些预测二值化,并通过引发异常来计算正例数量。尝试一些提交后,您将得到对潜在分布的公平估计。
简单轻巧的方法可能才是制胜关键。需要一些独到的见解来处理数据集,一些信息可能会帮助我们取得成功。目前 Leaderboard 已经不可靠了,B 榜可能面临巨大的抖动。在挑战结束时需要简单的方法和大量的运气才能获得足够好的分数和排名。简单来说,需要找到一种同时改善本地 CV 和 LB 的方法。
开源的 notebooks 会诱惑你使用更复杂的模型,在小数据集上做太多事情,他们将学习到仅仅由于小数据集而产生的偶然模式,而不是具有好的预测性质的模式。一定要注意避免过拟合,稳住。
📚️ 参考链接:
- This is a very difficult competition and come and see why…🧠🧠🧠
- ICR - Identifying Age-Related Conditions