前言
最近我们在重构消息中心,关于设计上的部分记录一下笔记,希望能够帮助到正在做类似设计的。另外我创建了一个高级研发的笔记分享群,免费加入,有兴趣的可以在文章底部扫描二维码加入
需求
我们的消息中心主要服务于如下场景:
1、业务使用消息通知对应人员;这也是我们目前主要的使用场景
2、给租户发送通知;如新功能上线,试用,开通功能场景
3、运营类的场景
以上只是列举了在企业中常见的3个场景,其实还有很多,消息中心存在着以下几个特征:
调用量大
消息中心的上游系统很多是监控系统、或者是营销系统等,这些系统的特点就是瞬间的调用量大,比如当云厂商发生故障时,基本上所有的监控系统都在告警,往外push消息。又或者营销系统在某个时间点大量发送营销消息。这个问题的答案就是引入MQ来削峰。
低延迟
业务方通常希望自己的消息越快越好,最好实时送达,但是我们的资源是有限的,所以我们应该给消息分级别和分泳道,因为重要的消息一般量小,需要低延时。而不重要的消息量大,往往可以接收一定时间的延时。按消息级别分泳道,不要让不重要的消息阻塞重要消息的发送。
不丢消息、不重复发送消息
消息要保证不丢失,不重复发送。我们要记录消息的状态,保证消息的幂等,还要支持发送失败的消息自动或手动重试。
历史消息查询和备份
我们可以分库分表,或者定期归档到hdfs。
消息统计分析
对消息的统计和分析主要用来治理我们的上游调用方,比如:有些业务大量的使用重要级别发送不重要消息,或者大量消息占用成本等等。
整体设计
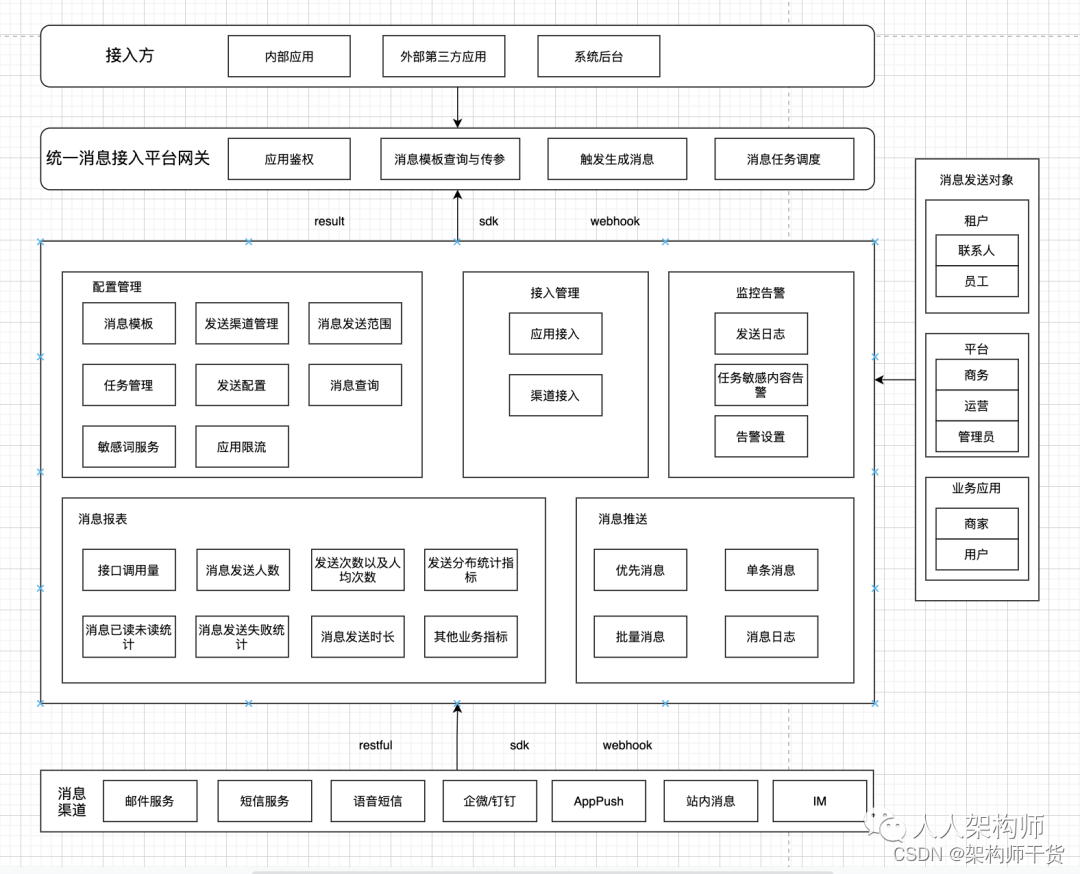
我们先来看下整体的设计
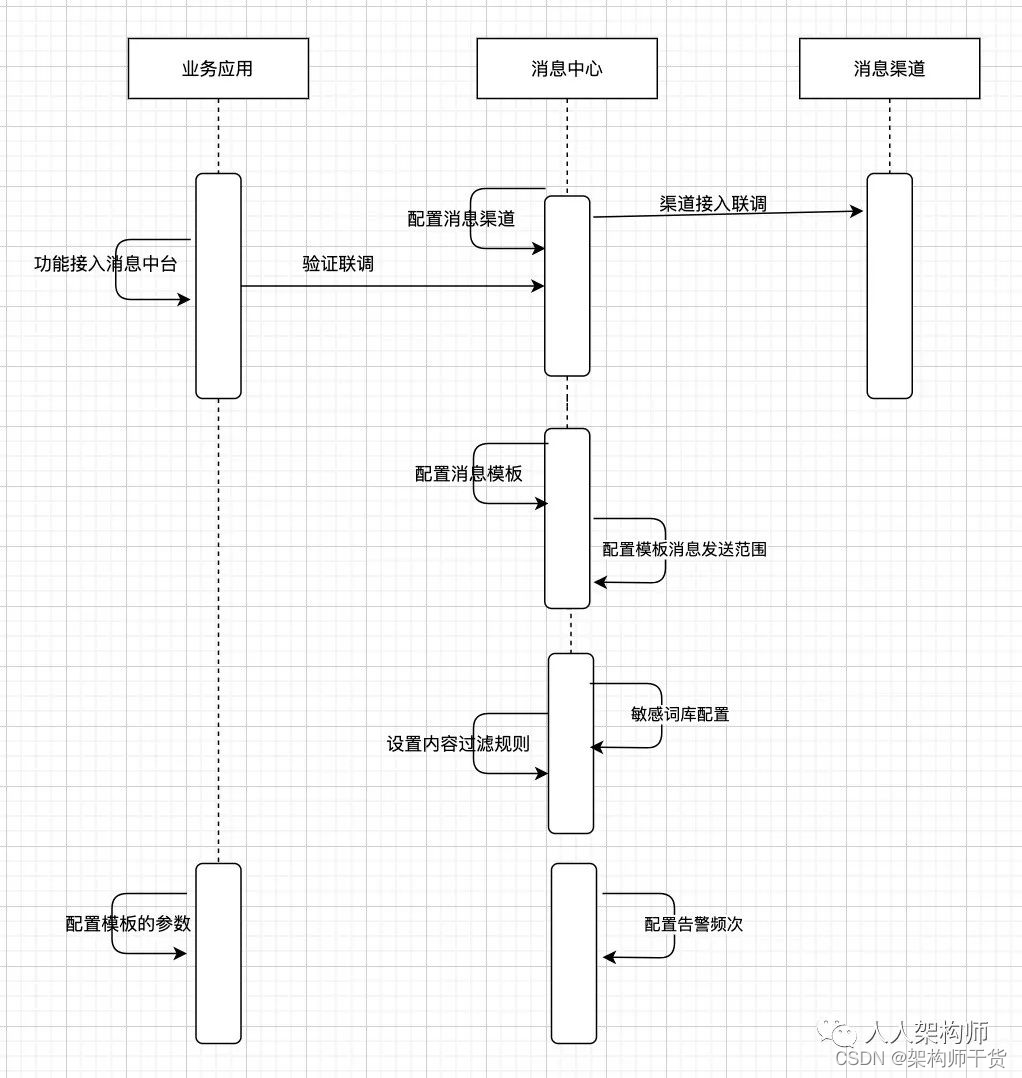
消息配置准备流程
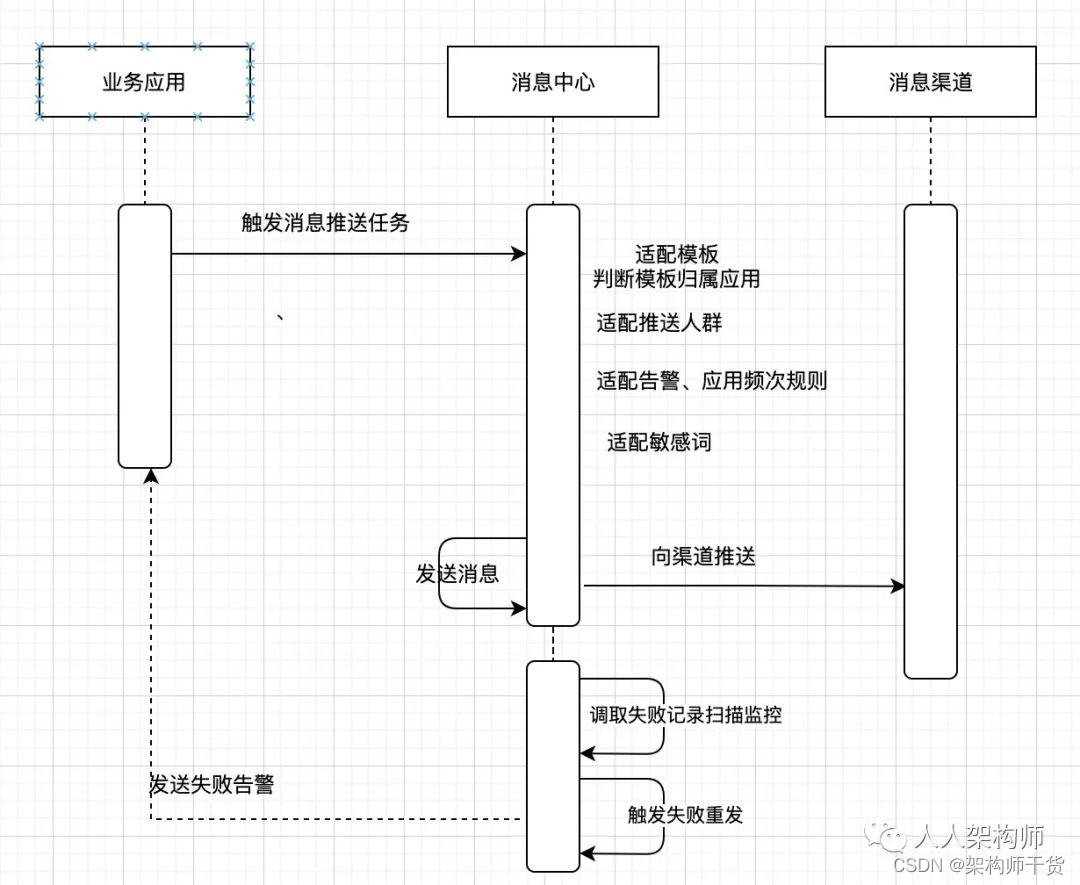
消息推送流程
消息任务生命周期
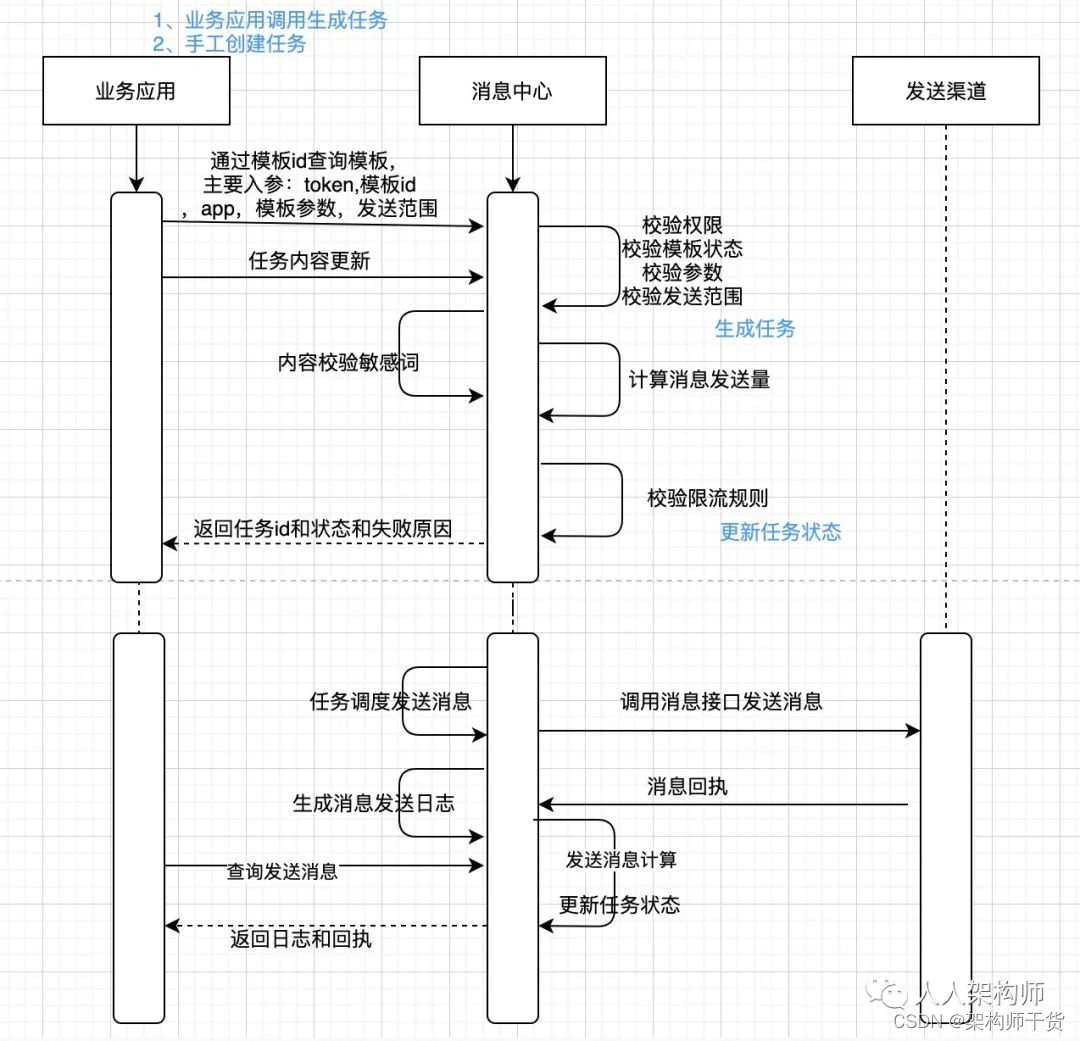
消息中心关键业务对象

用户免打扰
某些用户可能不想接收消息,某些场景下用户可以主动设置,租户管理员也可以手动设置某些用户免打扰,不需要接收消息,或者限制接收消息的频次
技术方案
推模型
一般来说消息都是读多写少
拉模型
官方消息其实很少,可以采用客户端拉取模型
当然如果数据量太大可以放弃掉mysql,改用hbase存储
为什么是Hbase?
HBase 和 MySQL 的核心差异在于底层的数据结构,HBase 使用 LSM(Log-Structure Merge)树,Innodb 使用 B+树。
LSM 树,即日志结构合并树(Log-Structured Merge-Tree)。其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。
核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到最多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾 (因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。
LSM 具有批量特性,存储延迟。当写读比例很大的时候(写比读多),LSM 树相比于 B 树有更好的性能。因为随着 insert 操作,为了维护 B 树结构,节点分裂。读磁盘的随机读写概率会变大,性能会逐渐减弱。多次单页随机写,变成一次多页随机写,复用了磁盘寻道时间,极大提升效率。
缓解压力
1、异步写入消息
2、先写缓存
优先分发
利用消息优先级队列,将不同优先级的消息发送到不同的队列当中
SPI机制的运用
消息限流规则场景,用户可以利用SPI机制自定义限流规则
设计模式的运用
1、渠道工厂
利用工厂模式创建渠道对象
2、模板方法+策略模式-发送消息流程
消息发送的流程大体上是一致的,比如 选择渠道-》执行消息推送-》消息日志记录-〉状态更新
3、状态模式-消息状态
消息是有状态的,就绪、发送、到达、丢失、创建,每一个状态都有对应的逻辑,如果消息到达后会更改状态
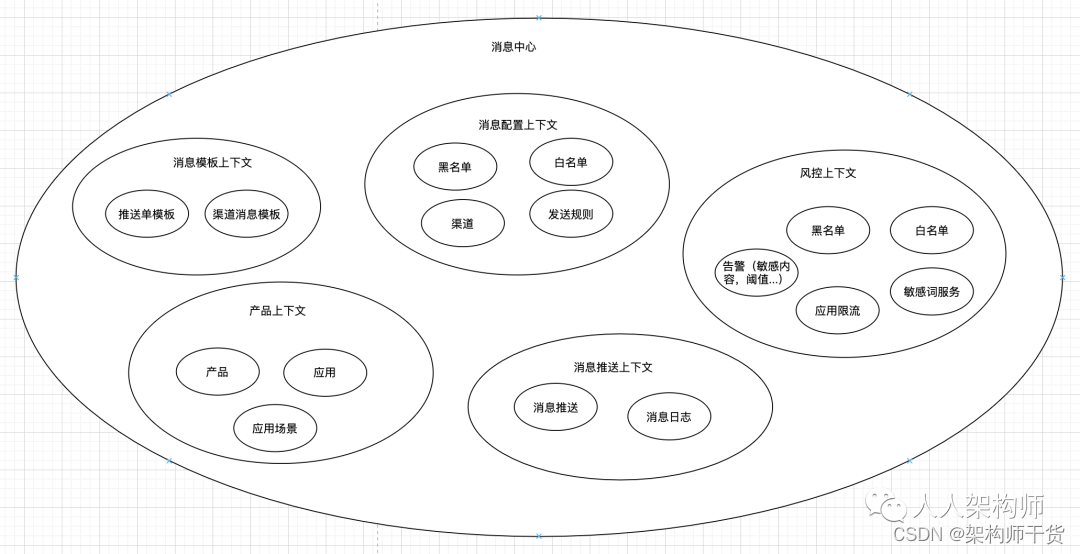
DDD上下文划分
关于DDD的上下文划分也给出来了,DDD其实在我们系统设计中用到很多了,无论是子域、上下文划分到聚合设计
未来展望
一个租户的短信消息可能走阿里云短信,可能走腾讯云短信
这样做一方面是为了并发处理和可用性,一方面是为了节省成本支出,因为不同数量的短信在不同的厂商的价格是不一样的。我们可以组合不同的价格策略对外提供消息价格,比如,外部接入消息价格为1条消息1毛,腾讯云和阿里云每个账号1w以下免费,那么我们就可以白赚2w条消息的钱。
因为高级研发笔记分享群是邀请制,评论留下你的微信号,我邀请你