文章目录
- 1.前言
- 2.物理执行生成(Stage)的生成
- 2.1不同的调度分区策略
- 2.1.1 Connector自己提供的分区策略
- 2.1.2 Presto提供的Partition策略(SystemPartitioningHandle):
- 2.2 为Stage创建StageScheduler
- 2.2.1 普通的非bucket表的TableScan Stage
- Split 放置策略解析
- 2.2.2 有splitSource但不是SOURCE_DISTRIBUTION的Stage的调度
- RemoteSourceNode的exchange类型为replicate 或者 没有RemoteSourceNode但是直接读bucket表
- RemoteSourceNode的exchange类型不是replicate
- 2.2.3 其它没有splitSource的Stage
- 3.1 FixedCountScheduler
- 3.2 SourcePartitionedScheduler
- 3.3 FixedSourcePartitionedScheduler
- 总结
1.前言
在我的上一篇文章《Presto(Trino)的逻辑执行计划和Fragment生成过程》介绍了Presto从Query提交到生成逻辑执行计划、逻辑执行计划的分段全过程。本文书接上文,开始讲解物理执行计划的生成,以及基于物理执行计划的task 和 split 的调度过程。
逻辑执行计划的整个生成和优化是基于用户的SQL和定义好的规则以及外围数据的基本元信息来进行,但是,与逻辑执行计划的生成和优化不同,物理执行计划的生成和调度需要依赖集群和外围数据本身的特性, 比如, 集群当前的动态运行状态,表(本文只讨论Hive)特征(是否是bucket表?是partition还是flat 表),甚至Presto worker和HDFS之间的位置关系来确定。
NOTE:
- 在本文中经常会出现
上游和下游,很容易引起部分读者的相反的理解,在这里明确,本文中,下游的输入会依赖上游的输出,因此典型的下游是执行计划树的root节点,典型的上游是直接读表的TableScanNode。- 在Presto物理执行计划的生成和调度这一层,很多代码涉及到了写数据的调度,以及grouped execution这个特性, 本文均不讨论。
2.物理执行生成(Stage)的生成
----------------------------------------------------------------
// 一个Hive的partition表(无bucket),作为join的左侧表(probe table)
CREATE TABLE `default.zipcodes_orc_partitioned`(
`recordnumber` int,
`country` string,
`city` string,
`zipcode` int)
PARTITIONED BY (
`state` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
----------------------------------------------------------------
// 一个Hive的partition且做了bucket表,作为join的右侧表(build table)
CREATE TABLE `zipcodes_orc_partitioned_bucket`(
`recordnumber` int,
`country` string,
`city` string,
`zipcode` int)
PARTITIONED BY (
`state` string)
CLUSTERED BY (
zipcode)
SORTED BY (
city ASC)
INTO 4 BUCKETS
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
----------------------------------------------------------------
SELECT *
FROM hive.default.zipcodes_orc_partitioned_bucket t1
LEFT JOIN hive.default.zipcodes_orc_partitioned t2
ON t1.country = t2.country;
----------------------------------------------------------------
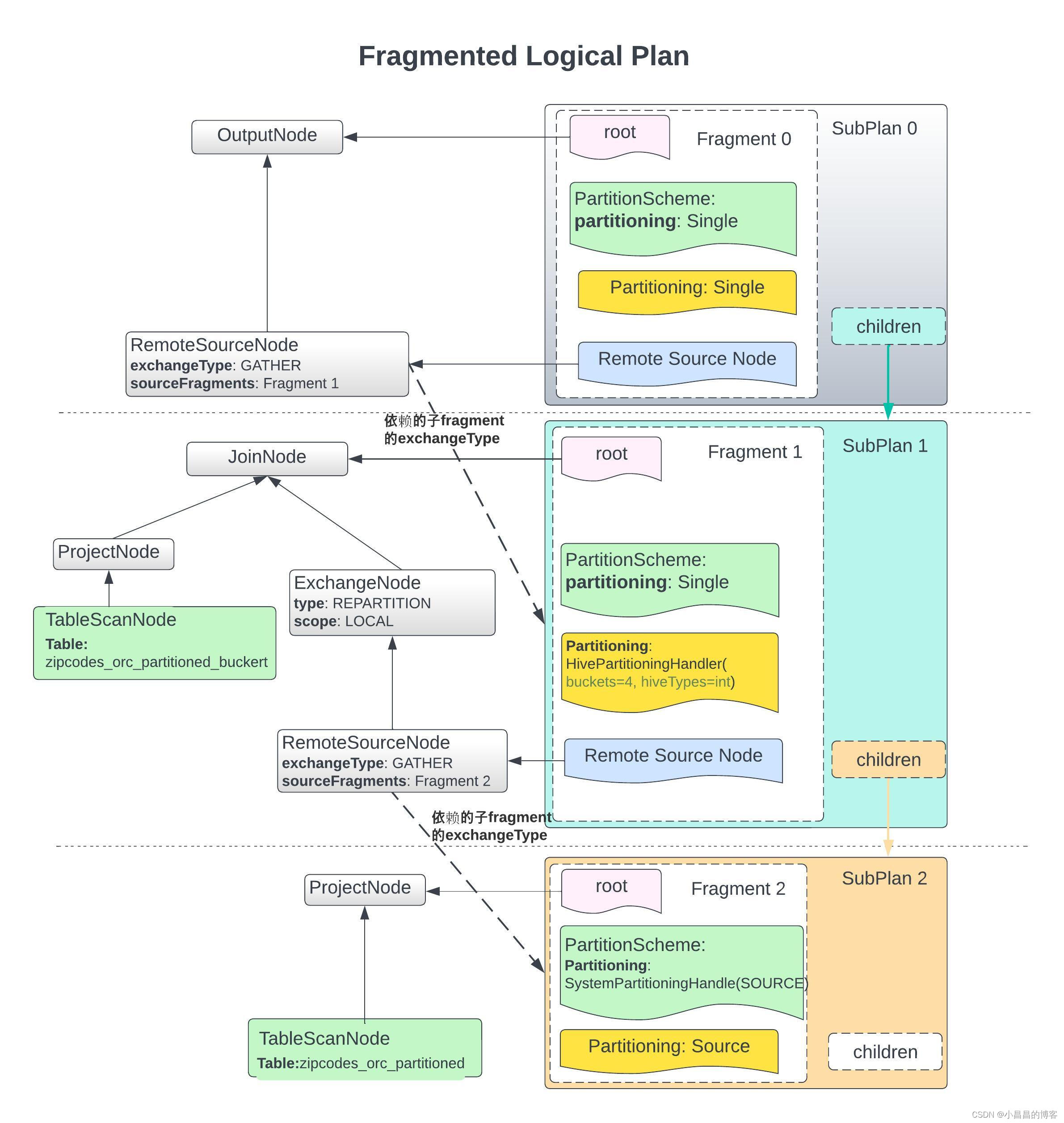
对于以上query,生成的分段逻辑执行计划如下图所示:
在SqlQueryExecution.start()中可以看到1) 构建逻辑执行计划以后 2) 开始构建物理执行计划 3) 对物理执行计划进行调度的代码逻辑:
// 构建逻辑执行计划,并对计划进行Fragment处理
PlanRoot plan = planQuery();
// 构建物理执行计划
planDistribution(plan);
.......
// if query is not finished, start the scheduler, otherwise cancel it
SqlQueryScheduler scheduler = queryScheduler.get();
if (!stateMachine.isDone()) {
scheduler.start(); // 开始调度物理执行计划
}
物理执行计划的生成自顶向下进行,即递归遍历刚刚生成的fragment计划,自顶向下生成整个stage执行树。
物理执行计划树的生成和调度都是由SqlQueryScheduler来完成的。
在Presto中,每一个Stage是一个SqlStageExecution的对象。Presto会首先构造一个SqlQueryScheduler对象,在构造函数中构建了rootStage, 然后递归调用createStages()方法生成并构造完成stage 树。
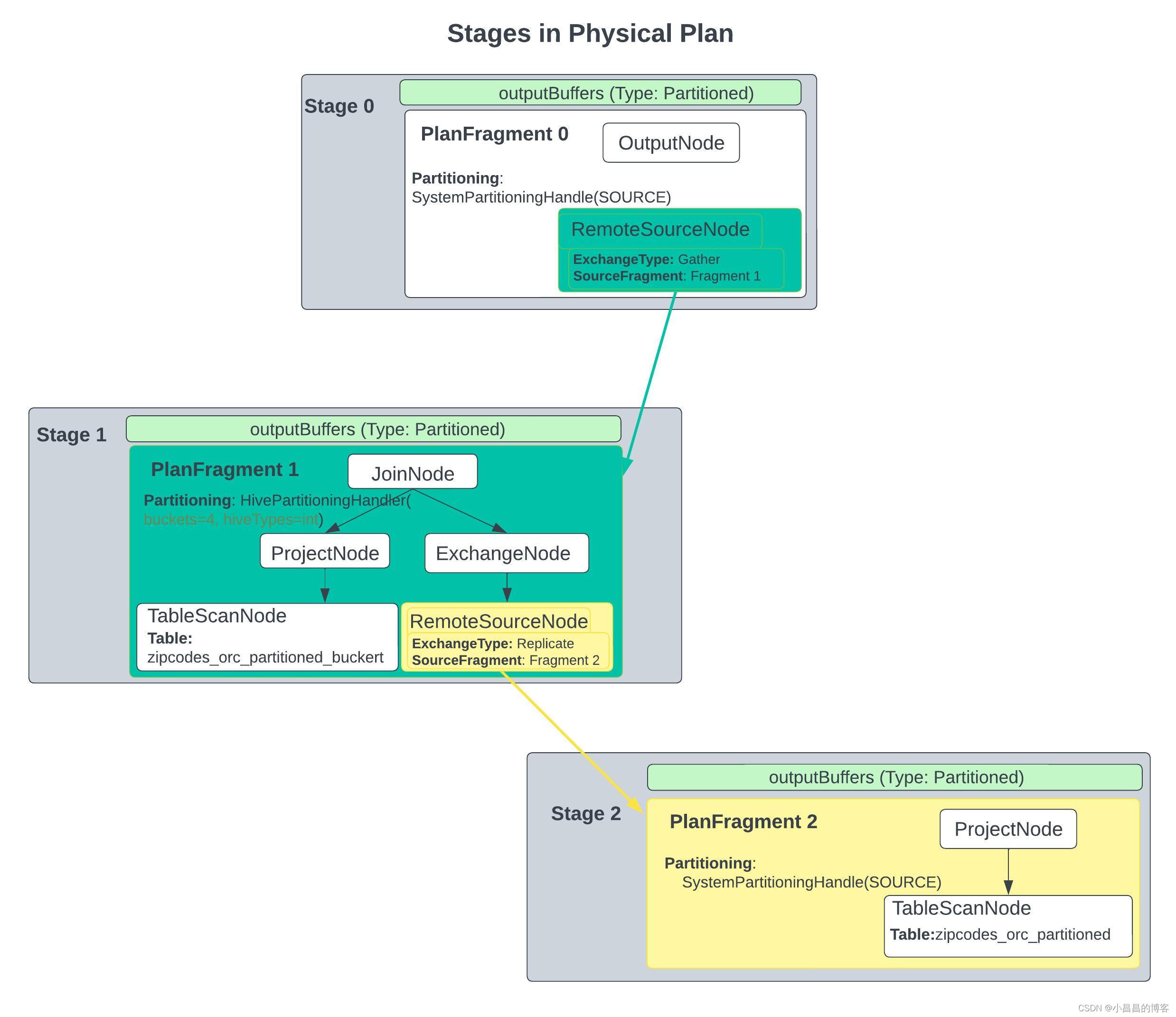
在构造每一个stage的时候,会做下面几件事情:
根据当前不同的PartitionHandle 构建
- 不同的split placement policy以确定split的调度方式
- 不同的stageScheduler以确定stage内部task的调度方式
2.1不同的调度分区策略
注意,这里的分区并不是指Hive表的分区,而是Presto中的分区概念,指Presto中每一个Fragment中的 task 和 split的分布策略,比如,
- 我们下文会详细分析,读原始非bucket hive 表的时候,这个策略叫做
SOURCE_DISTRIBUTION, - 而读bucket表的时候,一个bucket中的数据不会被打散,而是调度到一起,这时候的partition策略则是根据bucket的数量进行,
- 最后的计算结果会集中到最终的
OutputNode, 这个fragment的partition策略就叫做SINGLE。
不同调度策略决定于逻辑执行计划分段(PlanFragment)阶段,到了创建Stage的阶段,就需要根据不同的partition 策略,来确定具体的调度细节。
所有的根据partition策略来创建stage的过程,都体现在SqlQueryScheduler.createStages()中。
所以,每一个Presto 的 Fragment都有一个对应的partition策略,信息都封装在PartitioningHandle.java中:
public class PartitioningHandle
{
private final Optional<CatalogName> connectorId;
private final Optional<ConnectorTransactionHandle> transactionHandle;
private final ConnectorPartitioningHandle connectorHandle; // 比如对应 Bucket Hive表的ScanNode,partitioninHandle是HivePartitioningHandle
不同的PartitioningHandle的区别主要体现在connectorHandle上。我们可以把connectorHandle 分成两类,一种是Connector自己提供的分区策略,一种是Presto内置的处理各种分区方式的分区策略。具体介绍如下:
2.1.1 Connector自己提供的分区策略
如果Connector 自己提供了对应的PartitionHandle,那么就用connector自己提供的ConnectorPartitioningHandle来构造PartitioningHandle。这里最典型的例子是,Hive的bucket表. 在构建Fragment阶段,如果遇到了TableScanNode, Presto会尝试使用Hive Connector自己的ConnectorPartitioningHandle实现, 查看代码HiveMetadata.getTableProperties:
if (isBucketExecutionEnabled(session) && hiveTable.getBucketHandle().isPresent()) {
tablePartitioning = hiveTable.getBucketHandle().map(bucketing -> new ConnectorTablePartitioning(
new HivePartitioningHandle(
bucketing.getBucketingVersion(),
bucketing.getReadBucketCount(),
bucketing.getColumns().stream()
.map(HiveColumnHandle::getHiveType)
.collect(toImmutableList()),
OptionalInt.empty()),
bucketing.getColumns().stream()
.map(ColumnHandle.class::cast)
.collect(toImmutableList())));
可以看到,hive层面的处理策略是,如果是bucket表,那么会提供一个叫做HivePartitioningHandle 的 ConnectorPartitioningHandle实现,这个实现的最大功能是提供了bucket number的数量信息, 后期,Presto将根据bucket 的数量来确定调度的分区,即NodePartitionMap,本文后面会具体讲解。
2.1.2 Presto提供的Partition策略(SystemPartitioningHandle):
这发生在我们的Connector没有提供对应的PartitioningHandle的情况下,Presto就在生成Fragment的时候为这个Fragment构造合理的ConnectorPartitioningHandle并组装为PartitioningHandle。这种Partition策略的ConnectorPartitioningHandle实现类是都是SystemPartitioningHandle
public SystemPartitioningHandle(
@JsonProperty("partitioning") SystemPartitioning partitioning,
@JsonProperty("function") SystemPartitionFunction function)
{
this.partitioning = requireNonNull(partitioning, "partitioning is null");
this.function = requireNonNull(function, "function is null");
}
private enum SystemPartitioning
{
SINGLE,
FIXED,
SOURCE,
SCALED,
COORDINATOR_ONLY,
ARBITRARY
}
可以看到,SystemPartitioningHandle可以封装不同的Partition的策略,我们从改名字能够大致知道这些Partition策略所代表的partition的方式。
比如:对于非Partition的Hive 表,由于Hive没有提供ConnectorPartitioningHandle实现,因此, Presto使用Partition策略为SystemPartitioning.SOURCE作为PartitioningHandle的策略,封装为一个叫做SOURCE_DISTRIBUTION的PartitioningHandle的对象:
public static final PartitioningHandle SOURCE_DISTRIBUTION = createSystemPartitioning(SystemPartitioning.SOURCE, SystemPartitionFunction.UNKNOWN);
下面的代码显示,在逻辑执行计划生成阶段,会将非bucket表对应的Fragment的Partitioning设置为SOURCE_DISTRIBUTION
@Override
public PlanNode visitTableScan(TableScanNode node, RewriteContext<FragmentProperties> context)
{
PartitioningHandle partitioning = metadata.getTableProperties(session, node.getTable())
.getTablePartitioning()
.map(TablePartitioning::getPartitioningHandle)
.orElse(SOURCE_DISTRIBUTION);
2.2 为Stage创建StageScheduler
上面简单介绍了Presto中partition的策略,基于对partition策略的理解,我们开始来看Presto是怎么根据各个Stage的partition的特性,来为各个Stage准备好对应的StageScheduler实现,进而使用这些Scheduler实现来对Stage进行调度的。
下图是创建StageScheduler的基本流程。
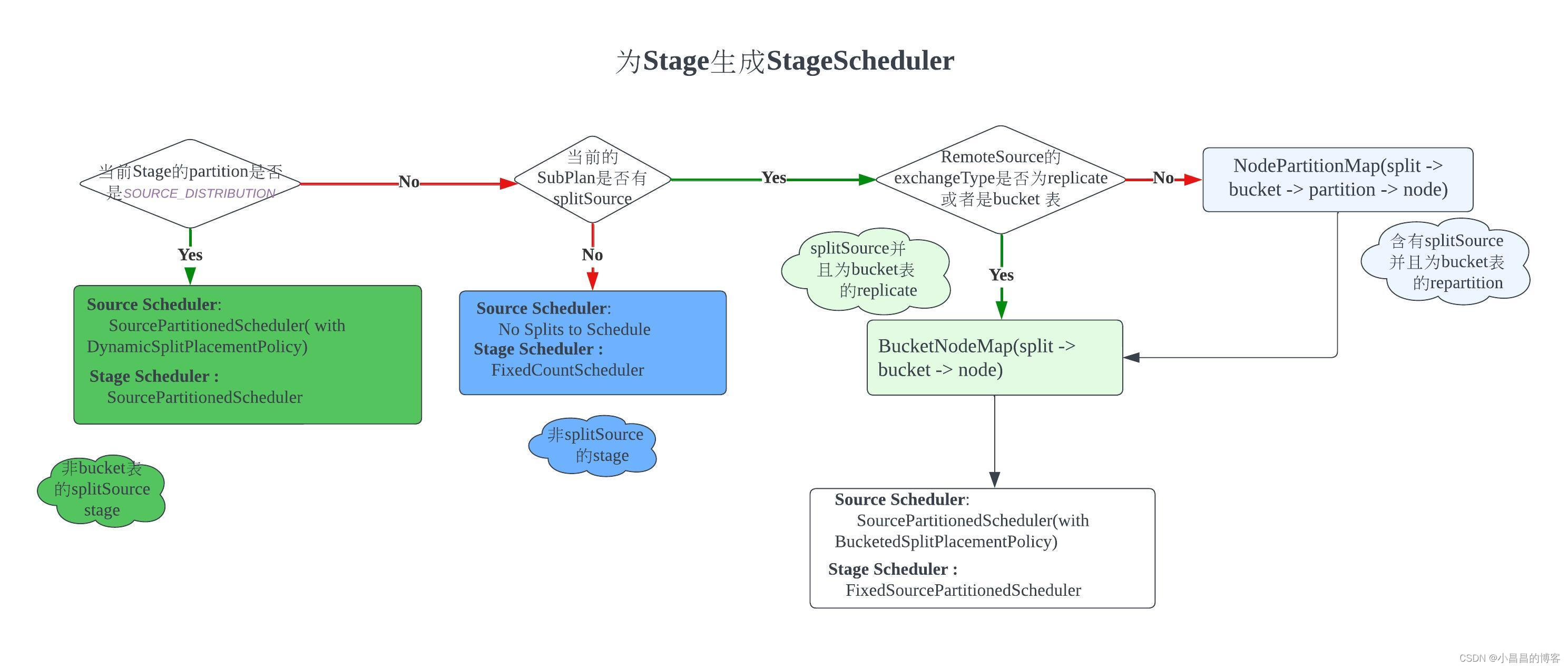
我们说Stage的调度,指的是对Stage中的Split和Task进行节点分配, 即让对应的Task在合适的节点上运行起来,同时,让这些Task知道从哪些上游(Children)的task中拉取数据,也知道有哪些下游(Parent)的task会从自己这里拉取数据因此自己需要把这些数据准备好。
Presto在这一层的代码实现并不是特别容易理解,Presto大致是这样考虑的:
- 对于那些直接读取Hive数据的Stage(有splitSource,并且是非partition表)
- 如果不是bucket表, 那么,我们会把读取这些split的task均匀分布到整个集群的所有节点,让每个节点均匀地负责一部分splits
- 如果是bucket表,那么会为每一个bucket独立分配一个task去处理数据
- 如果是既直接读取Hive数据(有splitSource,并且是bucket表),同时又通过
RemoteSourceNode指向了子Stage,那么这时候需要根据子Stage的exchange类型来确定调度形式- 如果子Stage的
ExchangeType是replicate,意味着上游(Children)Stage产生的数据需要无差别地复制到下游(Parent)Stage中去,不存在进行分区的问题 - 如果子Stage的
ExchangeType不是replicate(repartition或者gather),意味着上游(Children)Stage产生的数据需要根据对应的分区策略,只交付给对应的分区
- 如果子Stage的
- 没有splitSource的stage,这时候需要根据具体的分区情况来构建对应的Scheduler, 但是这时候由于没有直接的
TableScanNode,因此全部都是RemoteSplit,不存在Split的调度,只存在Task的调度,因此很简单。
2.2.1 普通的非bucket表的TableScan Stage
这种Stage是指这个 Stage中有TableScanNode, 并且这个TableScanNode对应的表不是bucket表,比如下面两种情况:
- 直接读取某一个非bucket 表(然后进行聚合或者不聚合都可以),比如:
SELECT * FROM unbucketed_table - 一个Join操作中,任何对应于读取非bucket表的一侧的Stage(或者两侧表都是非bucket 表),那么这种Stage的partitioning就会是
SOURCE_DISTRIBUTION的,比如:SELECT * FROM unbucketed_table ut left join bucketed_table bt on ut.row = bt.row中的左侧读表Stage或者SELECT * FROM bucketed_table bt left join unbucketed_table ut on bt.row = ut.row的右侧读表Stage
综上,如果这个Stage含有直接读非bucket表的TableScanNode, 那么这个Stage的partitioning就会在planFragment 阶段被设置为SOURCE_DISTRIBUTION,这意味着对于这个Stage 的split和task的调度采用一种类似于均匀的调度策略DynamicSplitPlacementPolicy,先把split均匀的分配(注意,不是调度)到整个集群的所有节点,让各个节点尽可能有均匀地workload,然后,把task调度到这些节点上去,task调度上去以后,就可以开始调度对应的split了。
上面描述的调度逻辑,发生在下面的代码中(SqlQueryScheduler.java)
if (partitioningHandle.equals(SOURCE_DISTRIBUTION)) {
// 在这种情况下,节点是通过DynamicSplitPlacementPolicy动态选择的
// nodes are selected dynamically based on the constraints of the splits and the system load
Entry<PlanNodeId, SplitSource> entry = Iterables.getOnlyElement(plan.getSplitSources().entrySet());
PlanNodeId planNodeId = entry.getKey();
SplitSource splitSource = entry.getValue();
Optional<CatalogName> catalogName = Optional.of(splitSource.getCatalogName())
.filter(catalog -> !isInternalSystemConnector(catalog));
NodeSelector nodeSelector = nodeScheduler.createNodeSelector(catalogName); // UniformNodeSelector
// 使用DynamicPlacementPolicy作为底层Scan Data的策略。即,只要节点上还有空闲,就可以使用这个节点,不存在node map
SplitPlacementPolicy placementPolicy = new DynamicSplitPlacementPolicy(nodeSelector, stage::getAllTasks);
checkArgument(!plan.getFragment().getStageExecutionDescriptor().isStageGroupedExecution());
// 把SourcePartitionedScheduler作为StageScheduler而不是SourceScheduler
stageSchedulers.put(stageId, newSourcePartitionedSchedulerAsStageScheduler(stage, planNodeId, splitSource, placementPolicy, splitBatchSize));
bucketToPartition = Optional.of(new int[1]);
}
对于这种表的调度,在逻辑执行计划生成阶段,Presto已经从表的元数据信息中获取到该表不是bucket表,因此设置了partitionHandle为SOURCE_DISTRIBUTION, 对于这种stage, Presto的调度逻辑可以描述为:
- 根据当前的
SplitPlacementPolicy和split本身的特性(split是否允许远程访问,split是否携带了地址),来确定split的分配表, 即splitAssignment - 确定了split的分配表以后,开始逐个节点的进行调度和分配(因为一个节点上可能分配了多个split,因此逐个节点进行分配和调度明显优于逐个split进行调度)
- 如果该节点当前还没有创建task,那么就在该节点上创建task并把task在这个节点调度起来
- 如果task创建好了, 那么只需要把这批分配到该节点的split给attach给这个task,让这个task开始处理这些split
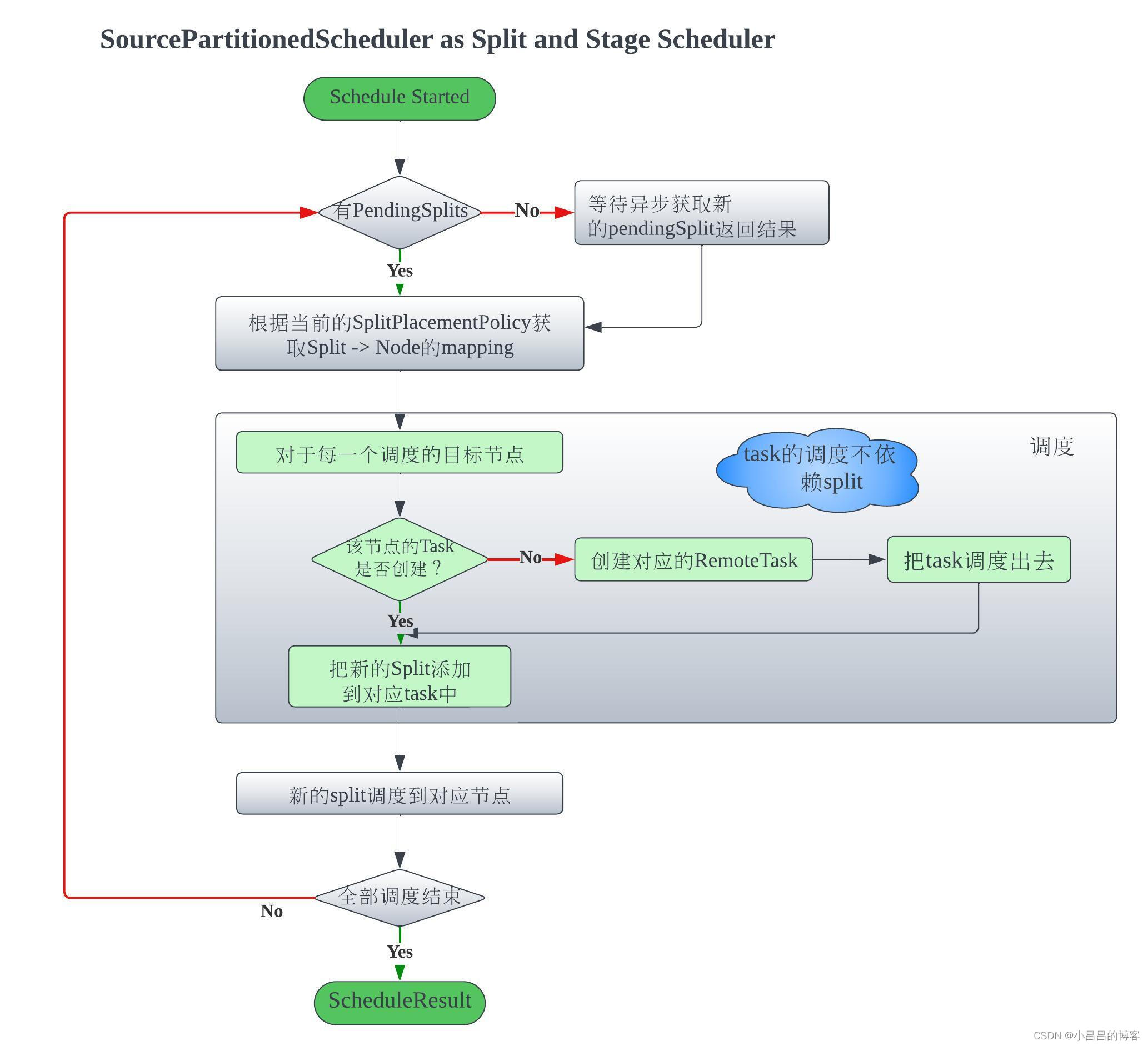
Split 放置策略解析
对于Split的放置策略,默认使用DynamicSplitPlacementPolicy,该DynamicSplitPlacementPolicy绑定的是UniformNodeSelector, 其节点选择逻辑为:
- 对于某一轮调度的一批splits, 先把所有的可以远程访问并且没有地址信息的split先进行worker节点分配, 即
- 该split是远程可访问并且split中没有地址信息, 那么为该split在当前所有的节点中选择已调度split数量最小的并且总的split数量没有超过最大允许运行的单节点的split数量的节点,从而实现worker节点所负责的split的数量的基本均衡
- 对于剩下的还没有分配到节点的split(这时候没有分配成功,可能是因为split不允许远程访问,也有可能是所有节点上运行的split已经超过了最大允许运行的split数量),这样做
- 如果该节点不是远程可访问,那么将这个split分配到这个split的address节点中去。很明显,这个split的address很可能根本不是presto的节点,那么这时候就分配失败。否则就分配成功
- 如果该节点可以远程访问,则尝试为该节点重新随机选择节点(不再考虑节点的worker上运行的split是否已经超过限制)
2.2.2 有splitSource但不是SOURCE_DISTRIBUTION的Stage的调度
这种Stage有splitSource,就意味着这个Stage有读表的TableScanNode,但是它的partitioning并不是SOURCE_DISTRIBUTION, 这发生在对于bucket 表进行读取的Stage (在2.2.1的Stage也有splitSource ,因为也读表了)。
这种Stage有splitSource,在Presto中意味着这个Stage是有读表的TableScanNode的,因此,上一章节中的Stage也是有splitSource的,但是仅限于**非bucket **表。但是,这种有TableScanNode的Stage可能还有其它类型,比如:
- 直接读取某一个bucket 表(然后进行聚合或者不聚合都可以),比如:
SELECT * FROM bucketed_table - 一个Join操作中,任何对应于读取bucket表的一侧的Stage(或者两侧表都是bucket 表),那么这种Stage就是有splitSource(因为读表了)却不是
SOURCE_DISTRIBUTION的,比如:SELECT * FROM unbucketed_table ut left join bucketed_table bt on ut.row = bt.row中的右侧读表Stage或者SELECT * FROM bucketed_table bt left join unbucketed_table ut on bt.row = ut.row的左侧读表Stage
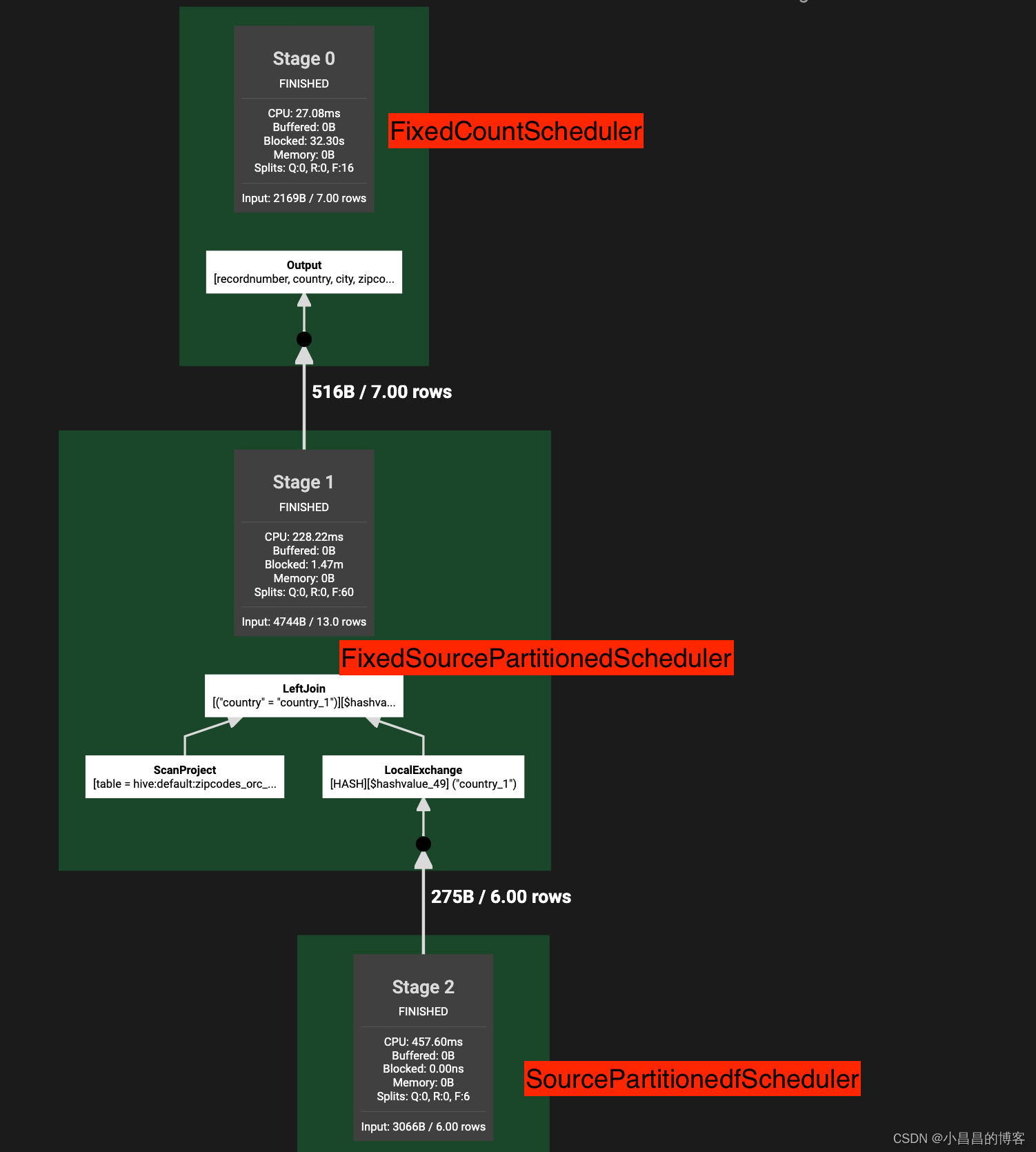
这种Stage有splitSource,我们需要根据RemoteSourceNode的partition 类型来分别计算从split到node之间的对应关系,然后进行split和task的调度
RemoteSourceNode的exchange类型为replicate 或者 没有RemoteSourceNode但是直接读bucket表
这种情况有两个前提,
- 一个是这个Stage有splitSource,即这个Stage有直接读表(
TableScanNode)的操作;另一个前提是整个Stage有RemoteSourceNode(即有子Stage)并且子Stage的exchange类型为replicate, 即当前Stage的RemoteSourceNode所指向的远程的Stage的exchange类型为replicate,而不是指当前Stage的exchange 类型为replicate。
或者
- 或者,这个Stage没有
RemoteSourceNode(即没有上游(Children)Stage),只有读表TableScanNode,并且这个表是bucket 表
Presto把这两种情况放在一个case中去处理,因为它们都不要求上游(Children)Stage有分区的概念,都有bucket表
这里的replicate, 和 spark中的BROADCAST是一个概念,发生在比如大表join小表,那么把小表的数据整个广播到所有join的task上面去构建一个哈希表。
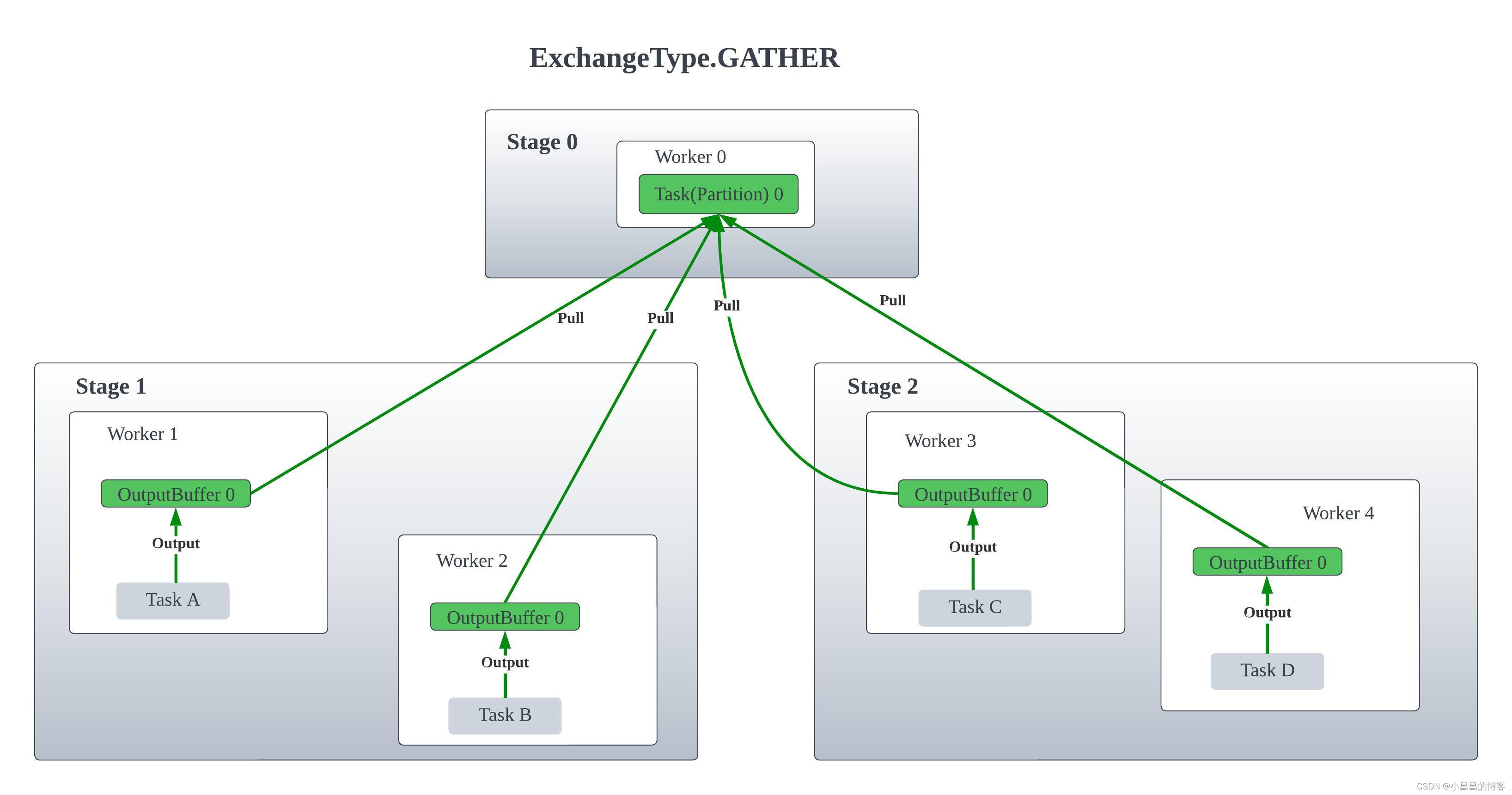
这是ExchangeType的定义,除了REPLICATE,还有REPARTITION和GATHER。Presto将REPLICATE单独处理,而将REPARTITION和GATHER放在一起处理,因为REPLICATE是没有PARTITION的概念的,而GATHER是一种特殊情况下的REPARTITION,即下游Stage只有一个task的REPARTITION。
public enum Type
{
GATHER, // 只是一种特殊情况下的repartition,即parent stage只有一个partition的REPARTITION
REPARTITION,
REPLICATE
}
下图分别释义了三种ExchangeType 的数据交换:
REPARTITION的exchange,上游(Children)的task会为下游(Parent)的每一个partition准备一个OutputBuffer, 根据比如hash算法,将对应的数据写入指定的partition 的OutputBuffer中,而下游(Parent)的task只会找上游(Children)的task拉取自己的partition的数据。
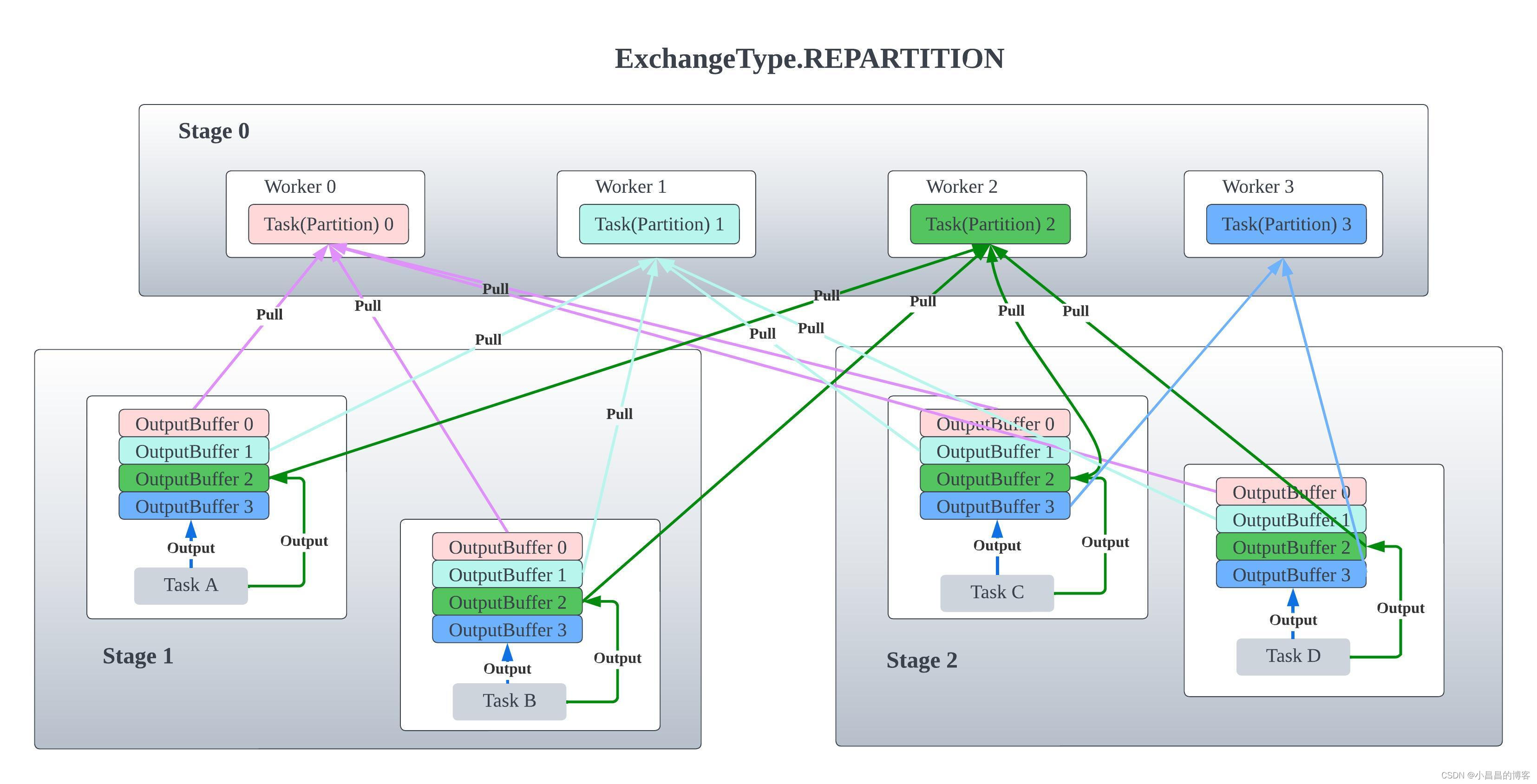
GATHER exchange其实是一种特殊的Exchange类型,即下游(Parent)只有一个task,因此上游(Children)每个Task的OutputBuffer只有一个。
REPLICATE 的exchange类型意味着上游(Children)的每个task的所有Output都放到一个Buffer中,下游(Parent)的每一个task会轮训上游(Children) Stage的所有task获取对应的这个task输出的全量数据。
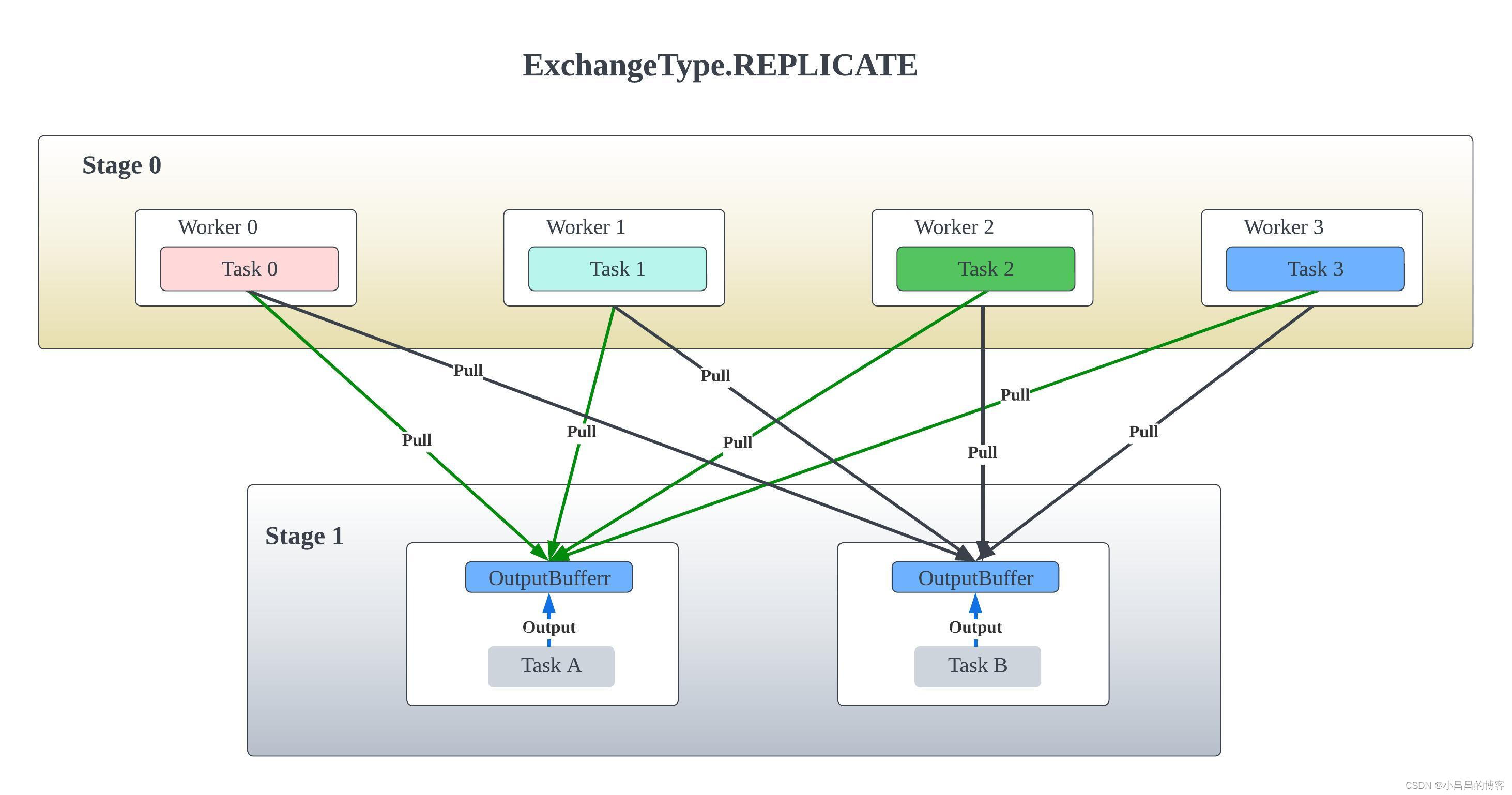
可以想见,如果自己依赖的下游的Stage的数据是会全量复制(replicate),那么我当前Stage的task的分布节点的调度可以只需要考虑到节点的数量。由于当前Stage的TableScanNode对应的表是bucket表,那么我完全可以为每一个bucket刚好调度一个task,即task与bucket一一对应,那么,上游的小表就为每一个task复制一份过去就行了。这其实就是这种Stage的调度思想。
这一部分调度处理逻辑发生在SqlStageScheduler.java中:
// 如果所有的节点的exchange type是REPLICATE,或者,它没有remoteSourceNodes,即只有读表的TableScanNode,显然,这张表是bucket表,因为在前面已经处理了非bucket表的读取了
// 检查RemoteSourceNode的exchangeType是否都是replicate. 注意,一个Stage如果只读表,是没有RemoteSourceNode的
if (plan.getFragment().getRemoteSourceNodes().stream().allMatch(node -> node.getExchangeType() == REPLICATE)) {
// no remote source
boolean dynamicLifespanSchedule = plan.getFragment().getStageExecutionDescriptor().isDynamicLifespanSchedule();
bucketNodeMap = nodePartitioningManager.getBucketNodeMap(session, partitioningHandle, dynamicLifespanSchedule); // 获取了从split -> bucket -> node的映射关系
// stageNodeList是所有的node // 需要调度到多少个节点上。stageNodeList的数量就是partition的数量
stageNodeList = new ArrayList<>(nodeScheduler.createNodeSelector(catalogName).allNodes()); //stageNodeList代表这个stage的所有节点
Collections.shuffle(stageNodeList);
// 用来创建对应的 StageExecutionPlan
bucketToPartition = Optional.empty(); // 这时候bucketToPartition是空的,即 没有什么partition的概念
}
从上面的代码可以看到,其实是构建了一个BucketNodeMap, 即构建完成了从split -> bucket -> node的映射关系,有了这一层映射关系,对于任何一个从connector层面读出来的split,我们都知道应该把这个split调度到哪个node上去。
那么,这个BucketNodeMap的映射关系是怎样构建的,构建原理如下图所示:
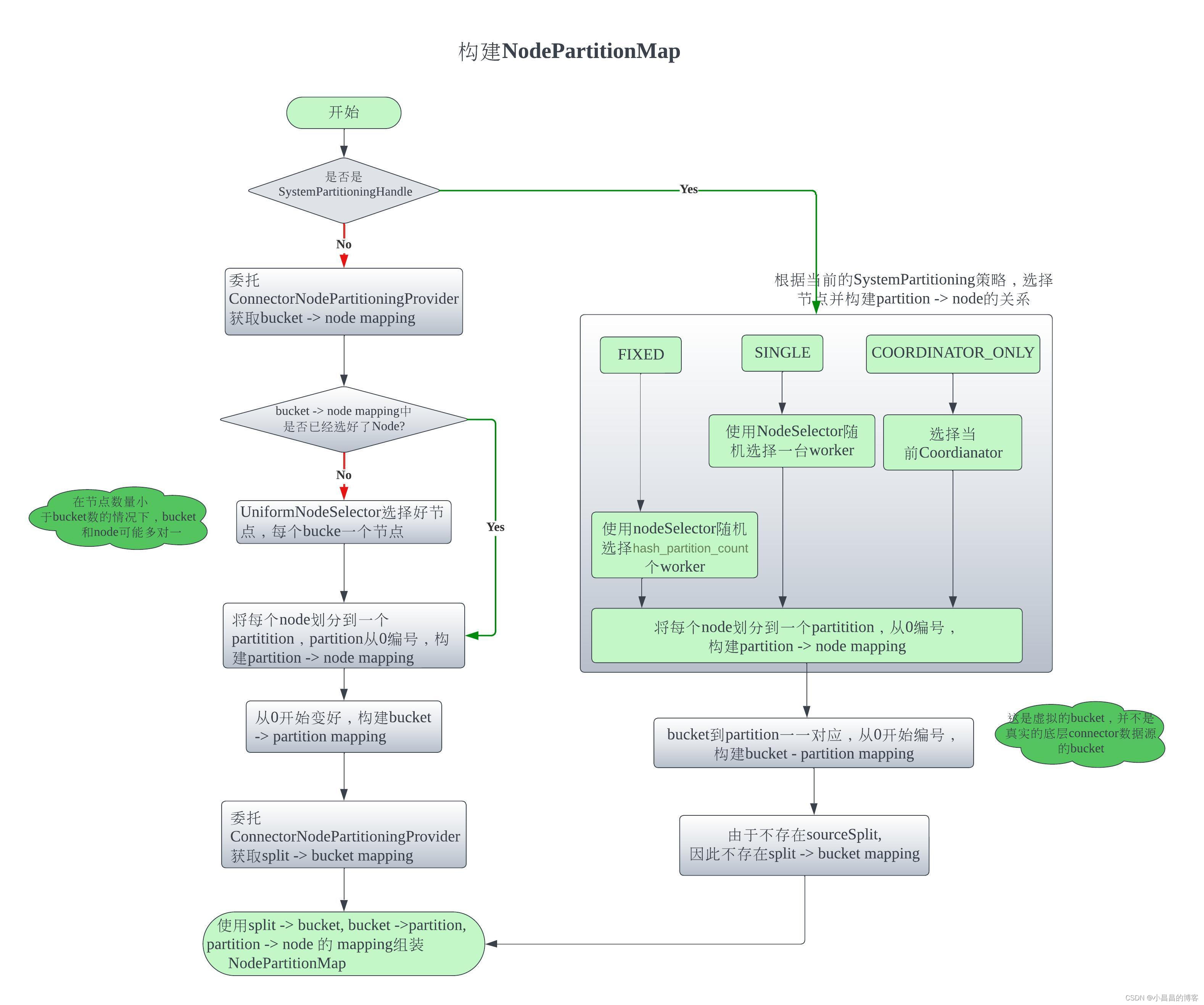
从代码可以看到,NodePartitionManager负责生成对应的BucketNodeMap, 看方法nodePartitioningManager.getBucketNodeMap(),可以看到,它还是委托接口ConnectorNodePartitioningProvider来提供对应的bucket信息,对于Hive, 接口ConnectorNodePartitioningProvider的实现类是HiveNodePartitioningProvider。HiveNodePartitioningProvider提供的bucket的相关信息,构建split -> bucket的映射关系,然后根据当前集群的节点状况,构建split -> bucket的映射关系,最终完成split -> bucket的映射。
我们看接口ConnectorNodePartitioningProvider的代码,能够看到ConnectorNodePartitioningProvider的具体意图:
public interface ConnectorNodePartitioningProvider
{
/**
* 在Connector层面提供bucket到node的映射关系
* @param transactionHandle
* @param session
* @param partitioningHandle
* @return
*/
ConnectorBucketNodeMap getBucketNodeMap(ConnectorTransactionHandle transactionHandle,
ConnectorSession session,
ConnectorPartitioningHandle partitioningHandle);
/**
* 在Connector层面提供split到bucket的映射关系
* @param transactionHandle
* @param session
* @param partitioningHandle
* @return
*/
ToIntFunction<ConnectorSplit> getSplitBucketFunction(ConnectorTransactionHandle transactionHandle,
ConnectorSession session,
ConnectorPartitioningHandle partitioningHandle);
/**
* 提供BucketFunction, 即给定任意一个Page和对应的position,返回这条数据对应的bucket
* @param transactionHandle
* @param session
* @param partitioningHandle
* @param partitionChannelTypes
* @param bucketCount
* @return
*/
BucketFunction getBucketFunction(
ConnectorTransactionHandle transactionHandle,
ConnectorSession session,
ConnectorPartitioningHandle partitioningHandle,
List<Type> partitionChannelTypes,
int bucketCount);
}
- 构建split -> bucket的映射关系
从代码HiveNodePartitioningProvider.getSplitBucketFunction()可以看到,逻辑很简单,就是提取split中的bucket编号即可:@Override public ToIntFunction<ConnectorSplit> getSplitBucketFunction( ConnectorTransactionHandle transactionHandle, ConnectorSession session, ConnectorPartitioningHandle partitioningHandle) { return value -> ((HiveSplit) value).getBucketNumber() // 这个function是用来把ConnectionSplit转成int,转换的function就是提取这个split中的bucketNumber,由此可见,一个split是不可能跨多个split的 .orElseThrow(() -> new IllegalArgumentException("Bucket number not set in split")); } - 构建bucket -> node的映射关系
从下面的代码可以看到,bucket -> node的映射关系就是根据bucket到数量随机选择了对应数量的节点,bucket和node一一对应,就完成了bucket到node对应关系return new FixedBucketNodeMap( // 通过每次随机选择节点,创建构建bucket到node的对应关系 getSplitToBucket(session, partitioningHandle), // 每一个split都对应了一个bucket createArbitraryBucketToNode( new ArrayList<>(nodeScheduler.createNodeSelector(catalogName).allNodes()), connectorBucketNodeMap.getBucketCount()));
当split -> bucket 和 bucket -> node的对应关系对应好了,那么就封装成 FixedBucketNodeMap,从而完成了从split -> node的对应关系。有了这一层对应关系,StageScheduler就知道应该把每一个split调度到哪个node,当然,对应的node会创建好对应的task。这种有splitSource但是不是SOURCE_DISTRIBUTION的Stage,Presto用SourcePartitionedScheduler作为splitSource scheduler, FixedSourcePartitionedScheduler作为StageScheduler,构建好Scheduler, 就可以开始调度。
RemoteSourceNode的exchange类型不是replicate
从上文中的Exchange.Type定义可以看出来,除了replicate,就是repartition和gather, Presto把它们作为同一种case进行处理,因为gather是下游stage只有一个partition的特殊情况下的repartition exchange。
这种情况的前提是需要有splitSource,即这个Stage有直接读表的操作,有TableScanNode操作。
RemoteSourceNode的exchange类型为repartition或者gather, 这意味着当前Stage的RemoteSourceNode所指向的远程的Stage的exchange类型为repartition或者gather, 而不是上面的replicate.
这种情况下,在Presto层面,会生成一个NodePartitionMap信息,这个信息的结构是这样的:
public class NodePartitionMap
{
// 根据partition获取对应的node
private final List<InternalNode> partitionToNode;
// 根据bucket index获取partition
private final int[] bucketToPartition;
// 根据split获取bucket的index
private final ToIntFunction<Split> splitToBucket;
这个类其实维护了split -> bucket -> partition -> node的对应关系。在这里,其实partition与task是一一对应的。维护这样一个关系的意义是:
对于一个Stage调度了一些task出去并且获得了调度结果,我们需要把这些task所属的partition更新到上游的Stage(这个stage所依赖的stage)的所有的task中去,保证上游的Stage的每个task都为上游的每一个partition准备好对应的output buffer,并将生成的需要传输给下游的数据准备好并放置在正确的对应的partition的OutputBuffer中,这样,下游的task通过拉取的方式来获取数据的时候,就可以拉取到正确的属于自己的partition的数据。
那么,NodePartitionMap是怎样构建出来的呢?
跟上一节讲到的BucketNodeMap的映射关系构建一样,这个NodePartitionMap的构建也是NodePartitioningManager来进行的,并且内部也是通过hive的ConnectorNodePartitioningProvider实现类HiveNodePartitioningProvider来提供bucket到信息,进而完成split -> bucket -> partition -> node的对应关系的构建的。
整个步骤如下图所示:

public NodePartitionMap getNodePartitioningMap(Session session, PartitioningHandle partitioningHandle)
{
// 这个PartitionHandle的connectorHandle为SystemPartitioningHandle, 说明是非源头fragment, 依赖SystemPartitioningHandle,
if (partitioningHandle.getConnectorHandle() instanceof SystemPartitioningHandle) {
return ((SystemPartitioningHandle) partitioningHandle.getConnectorHandle()).getNodePartitionMap(session, nodeScheduler);
}
// 对于源头PartitionHandle,应该是有对应的catalog信息的
CatalogName catalogName = partitioningHandle.getConnectorId()
.orElseThrow(() -> new IllegalArgumentException("No connector ID for partitioning handle: " + partitioningHandle));
ConnectorNodePartitioningProvider partitioningProvider = partitioningProviders.get(catalogName);
ConnectorBucketNodeMap connectorBucketNodeMap = getConnectorBucketNodeMap(session, partitioningHandle);
List<InternalNode> bucketToNode;
// 已经有了bucket到node的对应关系
if (connectorBucketNodeMap.hasFixedMapping()) {
bucketToNode = getFixedMapping(connectorBucketNodeMap);
}
else {
// 还没有bucket到node的对应关系,创建随机对应关系
bucketToNode = createArbitraryBucketToNode(
nodeScheduler.createNodeSelector(Optional.of(catalogName)).allNodes(),
connectorBucketNodeMap.getBucketCount());
}
int[] bucketToPartition = new int[connectorBucketNodeMap.getBucketCount()];
BiMap<InternalNode, Integer> nodeToPartition = HashBiMap.create();
int nextPartitionId = 0;
for (int bucket = 0; bucket < bucketToNode.size(); bucket++) {
// 不同的bucket可能属于同一个node,而node是跟partition一一对应的
// 比如,Presto cluster 有 5个节点,那么会有5个partition,但是hive table有256个bucket, 或者有2个bucket
InternalNode node = bucketToNode.get(bucket);
Integer partitionId = nodeToPartition.get(node);
// 还没有任何的partition分配到这个node, 那么为这个node分配partition
if (partitionId == null) {
partitionId = nextPartitionId++;
nodeToPartition.put(node, partitionId);
}
// 这个bucket属于了这个分区
bucketToPartition[bucket] = partitionId;
}
List<InternalNode> partitionToNode = IntStream.range(0, nodeToPartition.size())
.mapToObj(partitionId -> nodeToPartition.inverse().get(partitionId))
.collect(toImmutableList());
return new NodePartitionMap(partitionToNode, bucketToPartition, getSplitToBucket(session, partitioningHandle));
}
当有了NodePartitionMap以后,就可以构建对应的Scheduler, 这里,Presto用SourcePartitionedScheduler作为source scheduler, 用FixedSourcePartitionedScheduler,用FixedSourcePartitionedScheduler作为StageScheduler,构建好Scheduler, 开始调度。
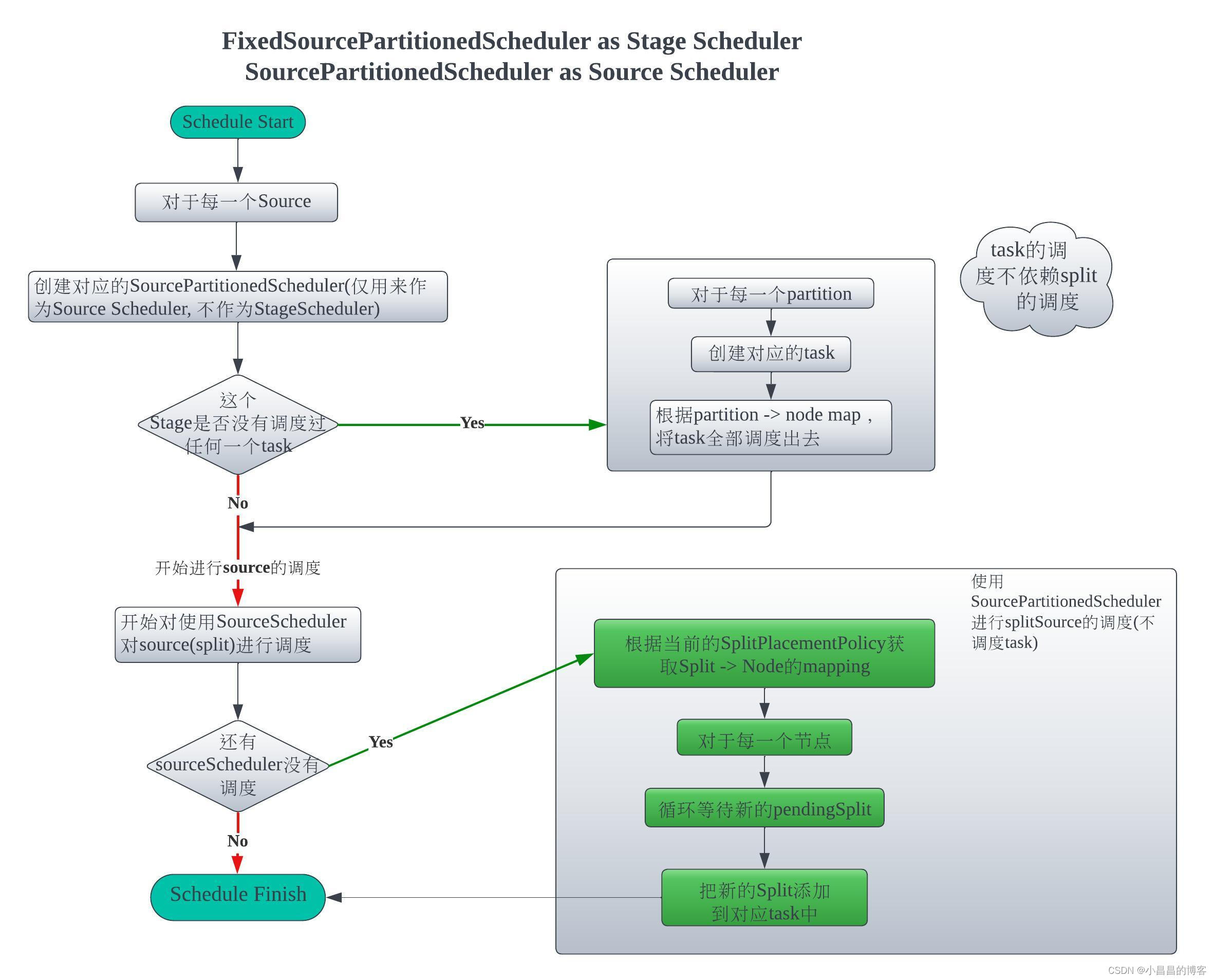
2.2.3 其它没有splitSource的Stage
这种stage没有splitsSource,说明这种Stage不包含TableScanNode, 在Presto中,这种Stage的split叫做RemoteSplit。 我的理解,叫做RemoteSplit的原因是,这种Stage的split都是上游Stage生成的,因此,这种Stage不用调度Split, 只需要调度好Task, 所有的split都需要task从上游Stage去拉取。比如,本文中的Stage 0.
这种Stage的调度使用的Scheduler是FixedCountScheduler,因为task的数量是明确的,它跟上一节** RemoteSourceNode的exchange类型不是replicate** 一样,也是通过NodePartitioningManager.getNodePartitioningMap()构建NodePartitionMap, 只不过这个Stage的ConnectorPartitioningHandle实现不再是HivePartitioningHandle, 而是 SystemPartitioningHandle(因为这个Stage没有TableScanNode, 不跟具体的split source打交道),因此是SystemPartitioningHandle提供对应的NodePartitionMap, 代码如下所示:
public NodePartitionMap getNodePartitionMap(Session session, NodeScheduler nodeScheduler)
{
// UniformNodeSelector
NodeSelector nodeSelector = nodeScheduler.createNodeSelector(Optional.empty());
List<InternalNode> nodes;
// 只支持COORDINATOR_ONLY, SINGLE, FIXED三种
if (partitioning == SystemPartitioning.COORDINATOR_ONLY) {
nodes = ImmutableList.of(nodeSelector.selectCurrentNode()); // 当前节点即coordinator节点
}
else if (partitioning == SystemPartitioning.SINGLE) {
nodes = nodeSelector.selectRandomNodes(1); // 比如select count(*), 这时候就任意选择一个节点就行
}
else if (partitioning == SystemPartitioning.FIXED) {
nodes = nodeSelector.selectRandomNodes(getHashPartitionCount(session));
}
// 对于system_partitioning, 是不需要split to bucket mapping的
return new NodePartitionMap(nodes, split -> {
throw new UnsupportedOperationException("System distribution does not support source splits");
});
}
当构建完了NodePartitionMap, 即确定了task的调度位置,那么就可以构建对应的StageScheduler了,这里的实现是FixedCountScheduler
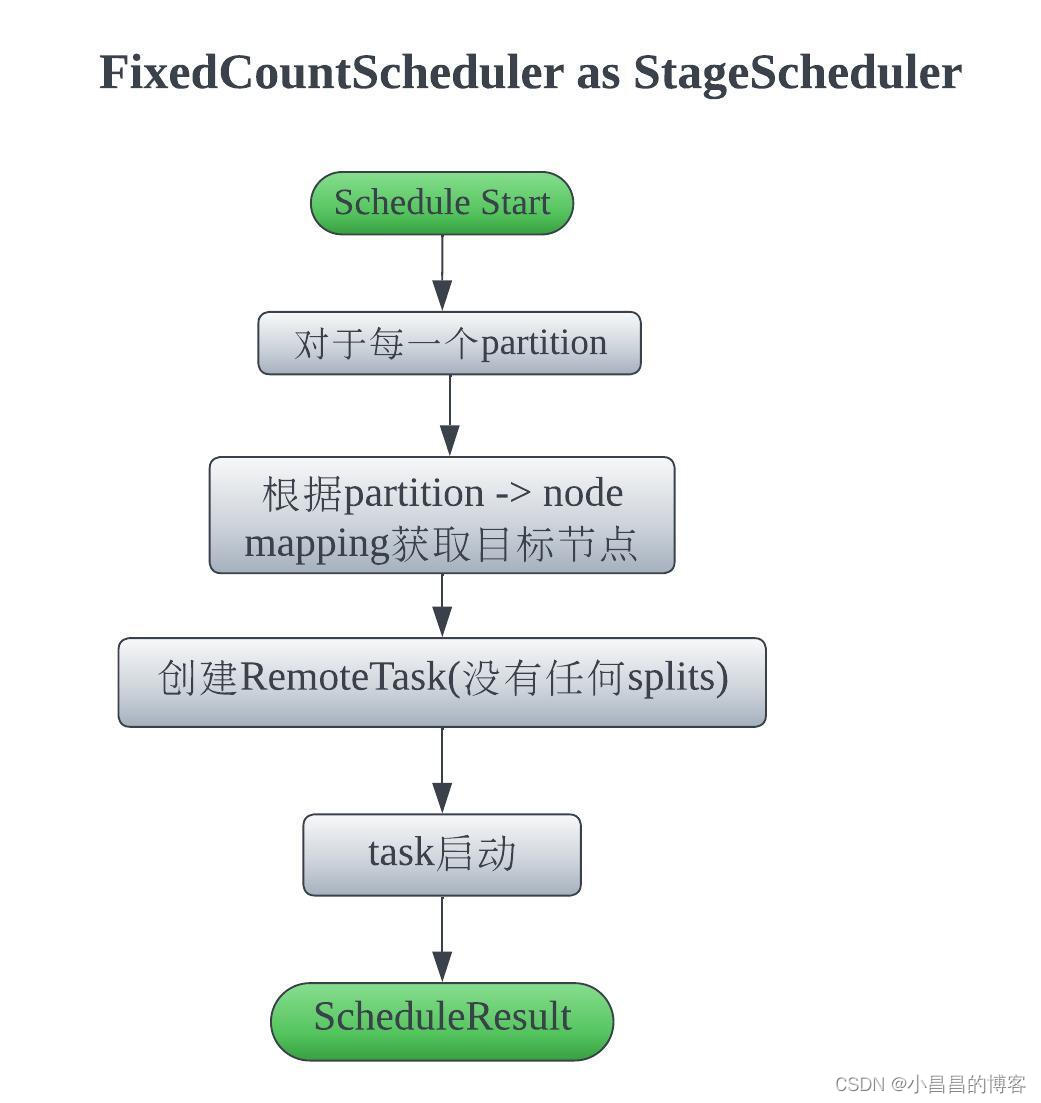 ### 2.2.4 为每一个Stage构建好StageScheduler,准备开始调度 到目前为止,无论是对于SourceSplit, 还是没有SourceSplit而全部都是远程Split的Stage,我们都构建完成了NodePartitionMap, 即我们知道了当前系统的分区信息(如果有分区),我们知道了具体的调度位置了,因此可以构建具体的调度器`SqlStageScheduler`了。 在构建完成了整个分配策略以后,就使用`FixedSourcePartitionedScheduler`作为对应的`StageScheduler`,而委托`SourcePartitionedScheduler`作为`SourceScheduler`,准备开始调度了。 # 3. 物理执行计划的调度 物理执行计划生成以后,调度是发生在SqlQueryScheduler.schedule()中的。在这个方法运行前,每一个stage都生成了对应的StageScheduler实现,所有的调度信息已经准备好了。 在SqlQueryScheduler.schedule()中,它会进行多轮的调度,每一轮调度,它都会委托具体的ExecutionPolicy接口的实现,来提供需要调度的Stage以及调度顺序,然后就按照返回的`List`的顺序依次调度。
### 2.2.4 为每一个Stage构建好StageScheduler,准备开始调度 到目前为止,无论是对于SourceSplit, 还是没有SourceSplit而全部都是远程Split的Stage,我们都构建完成了NodePartitionMap, 即我们知道了当前系统的分区信息(如果有分区),我们知道了具体的调度位置了,因此可以构建具体的调度器`SqlStageScheduler`了。 在构建完成了整个分配策略以后,就使用`FixedSourcePartitionedScheduler`作为对应的`StageScheduler`,而委托`SourcePartitionedScheduler`作为`SourceScheduler`,准备开始调度了。 # 3. 物理执行计划的调度 物理执行计划生成以后,调度是发生在SqlQueryScheduler.schedule()中的。在这个方法运行前,每一个stage都生成了对应的StageScheduler实现,所有的调度信息已经准备好了。 在SqlQueryScheduler.schedule()中,它会进行多轮的调度,每一轮调度,它都会委托具体的ExecutionPolicy接口的实现,来提供需要调度的Stage以及调度顺序,然后就按照返回的`List`的顺序依次调度。
必须清楚,某个Stage的调度并不是一次性就可以完成的(比如,我们底层的读表操作,这些Split的读取是下层connector通过异步方式提供给上层scheduler的,并不是一次性全部提供的),ExecutionPolicy会维护对应的Stage的调度状态,在每一轮调度开始的时候,只提供还没有完成调度的Stage。
对于ExecutionPolicy, Presto默认使用AllAtOnceExecutionPolicy, 它会把所有的Stage一次性调度出去。另外一种ExecutionPolicy的实现是PhasedExecutionPolicy, 本文不具体讨论。从代码可以看到,AllAtOnceExecutionPolicy会按照从底向上的顺序返回Stage,因此,SqlQueryScheduler.schedule()是按照从地向上的顺序开始调度的,即,往往含有TableScanNode的Stage会先调度出去,顶层返回结果给用户的OutputNode最后调度。但是必须清楚,这里的顺序仅仅是调度的顺序,一个后调度的Stage只是后调度,并不一定后执行,也并不需要等到前面先调度的Stage执行完才能开始执行或者被调度。
每一个 Stage调度完成以后,有可能产生了新调度出去的task,这时候,Presto都需要通过StageLinkage信息来维护和更新上游(children)和下游(parent)的相关信息,这是在StageLinkage.processScheduleResults()中做的,即,StageLinkage的作用非常一目了然,就是根据当前Stage不断更新的调度结果,维护上下游Stage之间的依赖关系, 包括:
- 告知下游(parent)的Stage的所有task,我这里有新的task了,从我这里pull数据吧。
这是通过调用下游(parent)的Stage的SqlStageExecution.addExchangeLocations()方法来实现的。查看代码可以看到,它会遍历下游(Parent) Stage的每一个task,把当前Stage的新的Task的信息封装成RemoteSplit,通知给Parent Stage的每一个Task:/** * * @param fragmentId 当前stage的fragment id * @param sourceTasks 为这个stage生成的新的task * @param noMoreExchangeLocations */ public synchronized void addExchangeLocations(PlanFragmentId fragmentId, Set<RemoteTask> sourceTasks, boolean noMoreExchangeLocations) { requireNonNull(fragmentId, "fragmentId is null"); requireNonNull(sourceTasks, "sourceTasks is null"); // 获取RemoteSourceNode,这个RemoteSourceNode对应的fragment是当前的SqlStageExecution的子节点, sourceTasks是这个fragmentId对应的分布式执行计划的source task RemoteSourceNode remoteSource = exchangeSources.get(fragmentId); // 这个fragment只是这个parent的众多remote source中的一个 // sourceTasks 是一个MultiMap, 对于一个key为remoteSourceId, value为这个id对应的搜有的sourceTasks this.sourceTasks.putAll(remoteSource.getId(), sourceTasks); // 对于 parent的每一个task,构建parent的task和source task之间的依赖关系 for (RemoteTask task : getAllTasks()) { // 由于SqlStageExection指代当前的parent,因此getAllTasks()代表当前的parent的所有的task ImmutableMultimap.Builder<PlanNodeId, Split> newSplits = ImmutableMultimap.builder(); for (RemoteTask sourceTask : sourceTasks) { URI exchangeLocation = sourceTask.getTaskStatus().getSelf(); newSplits.put(remoteSource.getId(), createRemoteSplitFor(task.getTaskId(), exchangeLocation)); } task.addSplits(newSplits.build()); // 为这个parent fragment的task设置remote split信息 } - 告知上游(children)的一个或者多个Stage的所有task,我有新的task需要从你那儿pull数据,因此你要准备好对应的OutputBuffer,存放好对应的数据,我会过来取。这是通过调用子Stage的对应的
OutputBufferManager.addOutputBuffers()来实现的。
private static class StageLinkage
{
private final PlanFragmentId currentStageFragmentId;
private final ExchangeLocationsConsumer parent;
private final Set<OutputBufferManager> childOutputBufferManagers; // 所有的childStage的output buffer
private final Set<StageId> childStageIds;
public StageLinkage(PlanFragmentId fragmentId, ExchangeLocationsConsumer parent, Set<SqlStageExecution> children)
{
this.currentStageFragmentId = fragmentId;
this.parent = parent;
this.childOutputBufferManagers = children.stream() // child stage的outputBufferManager创建好,这样,当前stage有了新的task,需要更新child stage的outputbuffer
.map(childStage -> {
PartitioningHandle partitioningHandle = childStage.getFragment().getPartitioningScheme().getPartitioning().getHandle();
if (partitioningHandle.equals(FIXED_BROADCAST_DISTRIBUTION)) {
return new BroadcastOutputBufferManager(childStage::setOutputBuffers);
}
else if (partitioningHandle.equals(SCALED_WRITER_DISTRIBUTION)) {
return new ScaledOutputBufferManager(childStage::setOutputBuffers);
}
else {
// index + 1
int partitionCount = Ints.max(childStage.getFragment().getPartitioningScheme().getBucketToPartition().get()) + 1;
return new PartitionedOutputBufferManager(partitioningHandle, partitionCount, childStage::setOutputBuffers);
}
})
从上面StageLinkage的成员变量中可以看到,每一个Stage的StageLinkage, 都维护了下游(Parent)的信息,和上游(Children)的信息,这样,通过StageLinkage, 我们就可以把一个Stage的信息变更告知给它的下游(Parent)和上游(Children).
在上面的StageLinkage的构造方法中,最重要的childOutputBufferManagers是给当前 Stage的每一个子Stage维护一个OutputBufferManager, 如果当前Stage调度出了新的Task,就会遍历childOutputBufferManagers,调用OutputBufferManager.addOutputBuffers()方法,将新的task的信息告诉子Stage,这样,子Stage 的所有在运行的task就会为这些新的task构建好OutputBuffer, 并将输出的数据放到对应的OutputBuffer中,等待当前Stage的task来取。
下面是OutputBufferManager接口的代码,调度过程中就是通过调用addOutputBuffers()方法,来更新对应的Task的outputBuffer信息的。
interface OutputBufferManager
{
void addOutputBuffers(List<OutputBufferId> newBuffers, boolean noMoreBuffers);
}
从StageLinkage的构造方法可以看到,StageLinkage会根据子Stage的PartitioningHandle, 绑定对应的OutputBufferManager接口实现,主要有这两种实现::
BroadcastOutputBufferManager,用在FIXED_BROADCAST_DISTRIBUTION的PartitioningHandle情况下,比如,broadcast join。BroadcastOutputBufferManger所管理的outputBuffer没有partition的概念,或者,我们可以认为只有一个id=0的partitionPartitionedOutputBufferManager,用来需要进行partition的PartitioningHandle的Stage,比如,partitioned join。 跟BroadcastOutputBufferManager相比,我们可以看到BroadcastOutputBufferManager.addOutputBuffers()的实现,PartitionedOutputBufferManager的outputBuffer是在PartitionedOutputBufferManager构造的时候就确定的,后续调用addOutputBuffers的时候如果发现这个bufferId已经存在并且不一样,就会抛出异常,因为基于partition策略构建的stage,这个OutputBuffer应该在构造的时候就是明确的。因此我们可以看到,构造PartitionedOutputBufferManager的时候调用withNoMoreBufferIds,即不会有更多的bufferId过来了。
3.1 FixedCountScheduler
从上文的讲解可以看到,FixedCountScheduler用来给不存在读表TableScanNode的Stage的调度使用的,因此不存在splitSource,所以,所有的split都是RemoteSplit,把task调度出去就行,不需要调度split。
FixedCountScheduler的调度不依赖split的调度,因此,它的实现是所有StageScheduler中最简单的,就是把每个partition上对应的task调度出去就完成了(注意,调度完成不代表运行完成)。具体的task的调度是taskScheduler.scheduleTask(),从代码可以看到,这里taskScheduler.scheduleTask()是一个lambda, 即调用SqlStageExecution.scheduleTask()来进行调度。
@Override
public ScheduleResult schedule()
{
OptionalInt totalPartitions = OptionalInt.of(partitionToNode.size());
List<RemoteTask> newTasks = IntStream.range(0, partitionToNode.size()) // 往每一个partitionToNode上调度task。
.mapToObj(partition -> taskScheduler.scheduleTask(partitionToNode.get(partition), partition, totalPartitions)) // taskScheduler是一个lambda, 具体的taskScheduler是对应的Stage的Scheduler
.filter(Optional::isPresent)
.map(Optional::get)
.collect(toImmutableList());
// 可以看到,finished=true, 表示这个FixedCountScheduler的调度已经结束
return new ScheduleResult(true, newTasks, 0);
}
3.2 SourcePartitionedScheduler
从上文的讲解可以看到,SourcePartitionedScheduler是用来给读非bucket表的Stage进行调度的StageScheduler实现。
这个Scheduler会不断的从后端的Connector取出splits,然后通过DynamicSplitPlacementPolicy来确定调度的目标节点,即准备好assignment信息,assignment表达的是节点和准备调度到该节点的所有splits。
然后开始委托SqlStageScheduler.scheduleSplit()进行调度。虽然名字叫scheduleSplit, 但是处理逻辑是,如果目标节点上还没有创建好task,那么必须先创建好task,因为,任何时候,不存在单独的split调度,我们说split调度,其实指的是,把split调度到对应节点上运行的task上去,即,Coordinator将split给attach到对应的task对象(这里是HttpRemoteTask),task会通过http到方式将split信息发送给worker端的task, 完成split的调度。
3.3 FixedSourcePartitionedScheduler
和SourcePartitionedScheduler一样,FixedSourcePartitionedScheduler也是用来进行含有splitSource的stage的调度的。
但是,FixedSourcePartitionedScheduler是委托SourcePartitionedScheduler来进行splitSource的调度,而自己来负责Task的调度。上面说过,不存在单独的split的调度,我们讲split的调度,其实指的是把split给attach到已经调度好的task上去。因此,FixedSourcePartitionedScheduler其实会先把task调度出去,然后再开始委托SourcePartitionedScheduler来进行splitSource的调度。由于SourcePartitionedScheduler在调度split的时候会检查对应的task是否创建好,如果创建好了就不会再创建task,因此,通过这种方式,来让SourcePartitionedScheduler仅仅调度split,而不再创建task。
那么,既然SourcePartitionedScheduler也能调度task, 为什么我们还需要FixedSourcePartitionedScheduler呢?因为FixedSourcePartitionedScheduler在构建的时候就已经知道调度的目标节点(存放在NodePartitionMap或者BucketNodeMap中),比如在读取bucket表的时候,已经根据bucket的数量确定了分区数量并且为每个分区选择了节点,所以直接把task一次性调度出去,并且由于是bucket表,因此进行split的调度的时候也不是使用DynamicSplitPlacementPolicy而是使用BucketedSplitPlacementPolicy(当然,split必须调度到task所在的节点中)。而SourcePartitionedScheduler读取的表为非bucket表,Connector这一层返回的split会被均匀调度到几乎所有的worker node(使用的是DynamicSplitPlacementPolicy),即SourcePartitionedScheduler在分配task到时候是将task调度到有split的节点上,并且对此并不预先知道,而是在有了split的assignment以后,按照这个split的assignment去调度task。
总结
从本文的整个分析来看,作为一个计算引擎,Presto在调度层的实现是非常复杂的,这是因为Presto作为计算引擎所需要处理的情况很复杂。
本文涉及到的处理逻辑、代码量非常大, 因此难免会有一些理解错误。如果有兴趣,可以一起交流。
WeChat: Vico_Wu
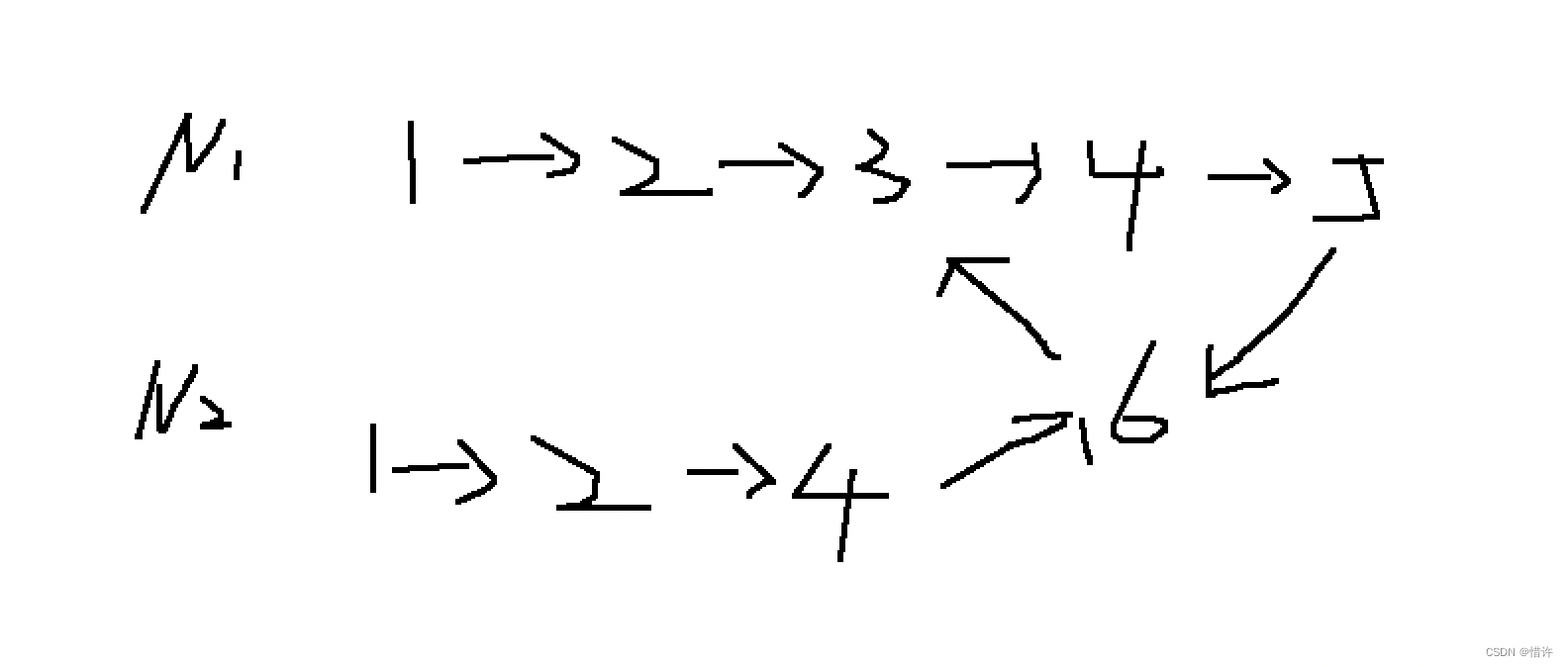




![[计算机入门]了解键盘](https://img-blog.csdnimg.cn/e5decd004efc46b498f0bc4d9fbae40c.png)