一、基本概念
在计算机中,所有的内容都是以二进制数据存储的,而我们在屏幕上看到的字和符号以及看不到的字符都是二进制数据转换后的结果。将字符按照某种规则转成对应的二进制数据,这个过程称为编码;而相对应的,将二进制数据以一定规则解析显示成字符的过程叫做解码。
- 字符
在计算机和电信技术中, 一个字符是一个单位的字形、类字形单位或符号的基本信息。说的简单点字符是各种文字和符号(可见和不可见)的总称。一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号、一个图形符号或者控制符号等。
- 字符集
(所有支持)字符的集合。比如ASCII字符集,UNICODE字符集,GBK字符集,GB18030字符集,BIG5字符集。
- 字符编码
一种映射规则。将字符集中的字符与对应二进制数据的映射关系,可以通过这个规则将字符转为二进制数据在计算机中传输和存储。
- 码位
编号。通常以一种将字符集是一张映射表,而每个字符有着唯一的编号,通过这个编号可以拿到对应的字符,这个编号也叫码位。
- 编码和字符集的关系
大部分的字符集和编码都是一个名称,并且编码规则都是直接映射关系,字符的编号(字节数据)也代表着映射表中的码位。如ASCII,GBK,GB18030等。
比较特殊的是UNICODE字符集,有UTF-8,UTF-16,UTF-32三种编码方式。每种编码的数据需要依据一定的规则才能转换为码位。
二、ASCII字符集&编码
最早的字符集。128个码位(0x00~0x7F),包含了所有西文,数字和字符。
后来因为不够用,将最高位也用上,扩展为EASCII字符集,码位范围变成0x00~0xFF,共256个码位。
三、GBXXXX字符集&编码
1. GB2312
第一个汉字编码国家标准,1980年发布。双字节
兼容ASCII字符集,当字节为0x00-0x7F时,判断为ASCII字符。
码位范围:0xA1A1-0xFEFE。其中汉字码位范围:0xB0A1-0xF7FE。
注意:这里用的‘-’表示,而非‘~’,因为这里的范围实际上是第一个字节(高位)范围:0xB0~0xF7,第二个字节(低位)范围:0xA1~0xFE。(比如第二个字节不可能为FF,第一个字节不可能为A2)。
分区表示方式
GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。这种表示方式也称为区位码。
区号:从0xA1开始表示01区,到0xFE结束,表示95区。
01-09区收录除汉字外的682个字符。
10-15区为空白区,没有使用。
16-55区收录3755个一级汉字,按拼音排序。
56-87区收录3008个二级汉字,按部首/笔画排序。
88-94区为空白区,没有使用。
如“啊”的GB2312编码位0xB0A1,所以区号是16区第一位,也就是0x1001
全角
在GB2312中,采用了双字节对中ASCII可见字符重新实现了一次,所占宽度与中文一样,这被称为全角,如0xA3E8表示全角h 。而同时GB2312依旧兼容原有的ASCII(0x00-0x7F),这些字符被称为半角
为什么从A1开始
因为前面偏移了0x20+0x80.
国际码
也叫交换码。在早期,不同操作系统可能使用不同的编码方式(内码),所以为了便于交换文件,在交换之前会将文件转为交换码,再进行交换。
前面提到了,GB2312对英文字母以双字节重新实现了一份,(所以交换码时并不会冲突),然而对于0-31位的不可见字符没有兼容。所以就可能会发生冲突(比如前面说到的“啊”的区号+位 为0x1001,直接转为国际码,则会被认为是ASCII的0x10 0x01两个字符,而失去本身的含义)。因此将GB2312向后偏移了32位,也就是0x20.
然而在偏移了0x20之后变成了0x3021,分别对应了ASCII的“0”和“!”又发生了冲突(导致中文编码被解析异常,一些ASCII编码的英文文档,用GB2312打开后发生乱码)。
所以为了与ASCII兼容,索性将最高位设为1,也就是偏移0x80。而0x80+0x20=0xA0,所以GB2312从0xA1开始编号。
2. GBK
依旧采用2字节,是对GB2312的扩展,不在限制第二字节必须大于127,同时只要第一个字节大于0x80,就认为是GBK的开始。
全部编码分为三大部分:
- 汉字区。包括:
a. GB 2312 汉字区。即 GBK/2: B0A1-F7FE。收录 GB 2312 汉字 6763 个,按原顺序排列。
b. GB 13000.1 扩充汉字区。包括:
(1) GBK/3: 8140-A0FE。收录 GB 13000.1 中的 CJK 汉字 6080 个。
(2) GBK/4: AA40-FEA0。收录 CJK 汉字和增补的汉字 8160 个。CJK 汉字在前,按 UCS 代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列。 - 图形符号区。包括:
a. GB 2312 非汉字符号区。即 GBK/1: A1A1-A9FE。其中除 GB 2312 的符号外,还有 10 个小写罗马数字和 GB 12345 增补的符号。计符号 717 个。
b. GB 13000.1 扩充非汉字区。即 GBK/5: A840-A9A0。BIG-5 非汉字符号、结构符和“○”排列在此区。计符号 166 个。 - 用户自定义区:分为(1)(2)(3)三个小区。
(1) AAA1-AFFE,码位 564 个。
(2) F8A1-FEFE,码位 658 个。
(3) A140-A7A0,码位 672 个。

为什么第二个字节不用0x7F
目前在网上只看到过一种解释是说,0x7F对应了ASCII的Del的字符,所以不用。(正确性待考证)
3. GB18030
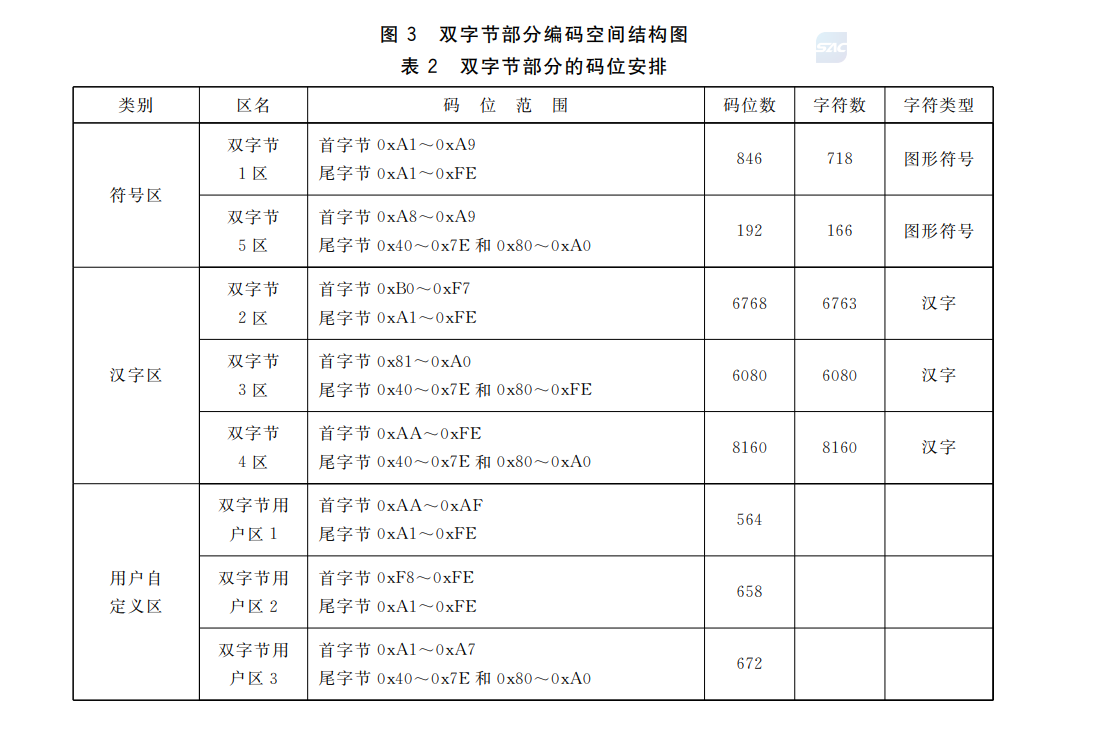
GB18030是对GBK的进一步扩展,采用变长方式,支持1,2,4字节。中文主要集中在2字节。
单字节依旧是与ASCII兼容。
双字节范围:
四字节范围:
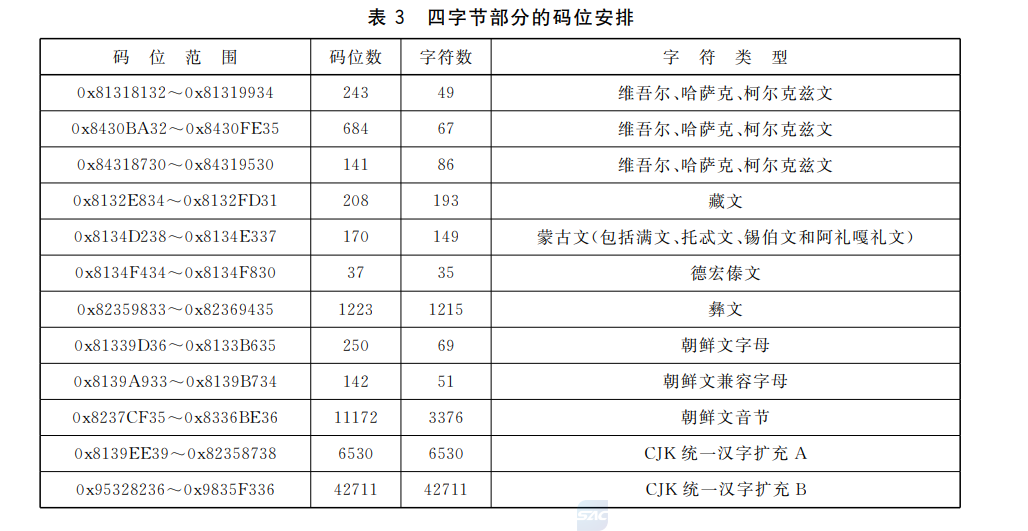
具体参考GB18030
四、Unicode字符集&UTF编码
Unicode作为一个字符集,其实也是一张映射表,其码位范围为:
0000-007F:C0控制符及基本拉丁文 (C0 Control and Basic Latin) 0080-00FF:C1控制符及拉丁文补充-1 (C1 Control and Latin 1 Supplement) 0100-017F:拉丁文扩展-A (Latin Extended-A) 0180-024F:拉丁文扩展-B (Latin Extended-B) 0250-02AF:国际音标扩展 (IPA Extensions) 02B0-02FF:空白修饰字母 (Spacing Modifiers) 0300-036F:结合用读音符号 (Combining Diacritics Marks) 0370-03FF:希腊文及科普特文 (Greek and Coptic) 0400-04FF:西里尔字母 (Cyrillic) 0500-052F:西里尔字母补充 (Cyrillic Supplement) 0530-058F:亚美尼亚语 (Armenian) 0590-05FF:希伯来文 (Hebrew) 0600-06FF:阿拉伯文 (Arabic) 0700-074F:叙利亚文 (Syriac) 0750-077F:阿拉伯文补充 (Arabic Supplement) 0780-07BF:马尔代夫语 (Thaana) 07C0-077F:西非书面语言 (N'Ko) 0800-085F:阿维斯塔语及巴列维语 (Avestan and Pahlavi) 0860-087F:曼达语 (Mandaic) 0880-08AF:撒马利亚语 (Samaritan) 0900-097F:天城文书 (Devanagari) 0980-09FF:孟加拉语 (Bengali) 0A00-0A7F:锡克教文 (Gurmukhi) 0A80-0AFF:古吉拉特文 (Gujarati) 0B00-0B7F:奥里亚文 (Oriya) 0B80-0BFF:泰米尔文 (Tamil) 0C00-0C7F:泰卢固文 (Telugu) 0C80-0CFF:卡纳达文 (Kannada) 0D00-0D7F:德拉维族语 (Malayalam) 0D80-0DFF:僧伽罗语 (Sinhala) 0E00-0E7F:泰文 (Thai) 0E80-0EFF:老挝文 (Lao) 0F00-0FFF:藏文 (Tibetan) 1000-109F:缅甸语 (Myanmar) 10A0-10FF:格鲁吉亚语 (Georgian) 1100-11FF:朝鲜文 (Hangul Jamo) 1200-137F:埃塞俄比亚语 (Ethiopic) 1380-139F:埃塞俄比亚语补充 (Ethiopic Supplement) 13A0-13FF:切罗基语 (Cherokee) 1400-167F:统一加拿大土著语音节 (Unified Canadian Aboriginal Syllabics) 1680-169F:欧甘字母 (Ogham) 16A0-16FF:如尼文 (Runic) 1700-171F:塔加拉语 (Tagalog) 1720-173F:哈努诺语(Hanunóo) 1740-175F:部希德文字符(Buhid) 1760-177F:塔格巴努亚文字符(Tagbanwa) 1780-17FF:高棉语 (Khmer) 1800-18AF:蒙古文 (Mongolian) 18B0-18FF:沙姆(Cham) 1900-194F:林布(Limbu) 1950-197F:德宏泰语 (Tai Le) 1980-19DF:新傣仂语 (New Tai Lue) 19E0-19FF:高棉语记号 (Kmer Symbols) 1A00-1A1F:布吉文(Buginese) 1A20-1A5F:巴达克(Batak) 1A80-1AEF:兰纳(Lanna) 1B00-1B7F:巴厘语 (Balinese) 1B80-1BB0:巽他语 (Sundanese) 1BC0-1BFF:杨松录苗文(Pahawh Hmong) 1C00-1C4F:雷布查语(Lepcha) 1C50-1C7F:桑塔利文 (Ol Chiki) 1C80-1CDF:曼尼普尔语 (Meithei/Manipuri) 1D00-1D7F:语音学扩展 (Phonetic Extensions) 1D80-1DBF:语音学扩展补充 (Phonetic ExtensionsSupplement) 1DC0-1DFF:结合用读音符号补充 (Combining DiacriticsMarks Supplement) 1E00-1EFF:拉丁文扩充附加 (Latin Extended Additional) 1F00-1FFF:希腊语扩充 (Greek Extended) 2000-206F:常用标点 (General Punctuation) 2070-209F:上标及下标 (Superscripts and Subscripts) 20A0-20CF:货币符号 (Currency Symbols) 20D0-20FF:组合用记号 (Combining Diacritics Marksfor Symbols) 2100-214F:字母式符号 (Letterlike Symbols) 2150-218F:数字形式 (Number Form) 2190-21FF:箭头 (Arrows) 2200-22FF:数学运算符 (Mathematical Operator) 2300-23FF:杂项工业符号 (Miscellaneous Technical) 2400-243F:控制图片 (Control Pictures) 2440-245F:光学识别符 (Optical Character Recognition) 2460-24FF:封闭式字母数字 (Enclosed Alphanumerics) 2500-257F:制表符 (Box Drawing) 2580-259F:方块元素 (Block Element) 25A0-25FF:几何图形 (Geometric Shapes) 2600-26FF:杂项符号 (Miscellaneous Symbols) 2700-27BF:印刷符号 (Dingbats) 27C0-27EF:杂项数学符号-A (MiscellaneousMathematical Symbols-A) 27F0-27FF:追加箭头-A (Supplemental Arrows-A) 2800-28FF:盲文点字模型 (Braille Patterns) 2900-297F:追加箭头-B (Supplemental Arrows-B) 2980-29FF:杂项数学符号-B (MiscellaneousMathematical Symbols-B) 2A00-2AFF:追加数学运算符 (Supplemental MathematicalOperator) 2B00-2BFF:杂项符号和箭头 (Miscellaneous Symbols andArrows) 2C00-2C5F:格拉哥里字母 (Glagolitic) 2C60-2C7F:拉丁文扩展-C (Latin Extended-C) 2C80-2CFF:古埃及语 (Coptic) 2D00-2D2F:格鲁吉亚语补充 (Georgian Supplement) 2D30-2D7F:提非纳文 (Tifinagh) 2D80-2DDF:埃塞俄比亚语扩展 (Ethiopic Extended) 2E00-2E7F:追加标点 (Supplemental Punctuation) 2E80-2EFF:CJK 部首补充 (CJK Radicals Supplement) 2F00-2FDF:康熙字典部首 (Kangxi Radicals) 2FF0-2FFF:表意文字描述符 (Ideographic DescriptionCharacters) 3000-303F:CJK 符号和标点 (CJKSymbols and Punctuation) 3040-309F:日文平假名 (Hiragana) 30A0-30FF:日文片假名 (Katakana) 3100-312F:注音字母 (Bopomofo) 3130-318F:朝鲜文兼容字母 (Hangul Compatibility Jamo) 3190-319F:象形字注释标志 (Kanbun) 31A0-31BF:注音字母扩展 (Bopomofo Extended) 31C0-31EF:CJK 笔画 (CJK Strokes) 31F0-31FF:日文片假名语音扩展 (Katakana PhoneticExtensions) 3200-32FF:封闭式 CJK 文字和月份 (Enclosed CJK Letters andMonths) 3300-33FF:CJK 兼容 (CJK Compatibility) 3400-4DBF:CJK 统一表意符号扩展 A (CJK Unified Ideographs Extension A) 4DC0-4DFF:易经六十四卦符号 (Yijing Hexagrams Symbols) 4E00-9FBF:CJK 统一表意符号,中文字符 (CJK Unified Ideographs) A000-A48F:彝文音节 (Yi Syllables) A490-A4CF:彝文字根 (Yi Radicals) A500-A61F:瓦伊语(Vai) A660-A6FF:统一加拿大土著语音节补充 (Unified CanadianAboriginal Syllabics Supplement) A700-A71F:声调修饰字母 (Modifier Tone Letters) A720-A7FF:拉丁文扩展-D (Latin Extended-D) A800-A82F:锡尔赫特文 (Syloti Nagri) A840-A87F:八思巴字 (Phags-pa) A880-A8DF:索拉什特拉(Saurashtra) A900-A97F:爪哇语 (Javanese) A980-A9DF:查克玛语(Chakma) AA00-AA3F:Varang Kshiti AA40-AA6F:Sorang Sompeng AA80-AADF:尼瓦尔语 (Newari) AB00-AB5F:越南傣语 (Vietnam Thai) AB80-ABA0:克耶字母 (Kayah Li) AC00-D7AF:朝鲜文音节 (Hangul Syllables) D800-DBFF:高半区UTF-16(High-half zone of UTF-16) DC00-DFFF:低半区UTF-16(Low-half zone of UTF-16) E000-F8FF:自行使用区域 (Private Use Zone) F900-FAFF:CJK 兼容象形文字 (CJK Compatibility Ideographs) FB00-FB4F:字母表达形式 (Alphabetic Presentation Form) FB50-FDFF:阿拉伯表达形式A (Arabic PresentationForm-A) FE00-FE0F:变量选择符 (Variation Selector) FE10-FE1F:竖排形式 (Vertical Forms) FE20-FE2F:组合用半符号(Combining Half Marks) FE30-FE4F:CJK 兼容形式 (CJKCompatibility Forms) FE50-FE6F:小型变体形式 (Small Form Variants) FE70-FEFF:阿拉伯表达形式B (Arabic PresentationForm-B) FF00-FFEF:半型及全型形式 (Halfwidth and FullwidthForm) FFF0-FFFF:特殊 (Specials) 10300..1032F;Old Italic 10330..1034F; Gothic 10400..1044F; Deseret 1D000..1D0FF; Byzantine Musical Symbols 1D100..1D1FF; Musical Symbols 1D400..1D7FF; Mathematical Alphanumeric Symbols 20000..2A6D6; CJK Unified Ideographs Extension B 2F800..2FA1F; CJK Compatibility Ideographs Supplement E0000..E007F; Tags F0000..FFFFD;Private Use 100000..10FFFD; Private Use
其中中文字符范围:
Unicode CJK 的范围分布在多个区段中,带有 CJK 的区块名中都拥有汉字。但最常用的范围是 U+4E00~U+9FA5,即名为:CJK Unified Ideographs 的区块,但 U+9FA6~U+9FFF 之间的字符还属于空码,暂时还未定义,但不能保证以后不会被定义。
注1:中文范围 4E00-9FBF:CJK 统一表意符号 (CJK Unified Ideographs)
注2:正则表达式[\u4e00-\u9fa5] 可匹配中文字符,但这种方式并不能根据平台所提供的字符集范围不同而改变。
注3:Unicode 中 U+4E00~U+9FFF 的码表:http://www.unicode.org/charts/PDF/U4E00.pdf
注4:Unicode 码查到所有的字符:http://www.unicode.org/cgi-bin/GetUnihanData.pl
需要注意的是,Unicode不同于前面所说的字符集,他的码位只代表着映射表的索引,而并非存储在计算机里的数据.想要得到对应的数据还需要根据编码规则解析得到,Unicode的编码有UTF-8,UTF-16,UTF-32三种
1. UTF-8
一种变长字符编码,所占内存空间1~4字节。
编码规则:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的, 所以 UTF-8 能兼容 ASCII 编码,这也是互联网普遍采用 UTF-8 的原因之一
- 对于 n 字节的符号( n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码
| Unicode码位范围 | utf-8编码二进制 | 内存空间 |
| 0x00-0x7F | 0xxxxxxx | 一字节 |
| 0x80-0x07FF | 110xxxxx 10xxxxxx | 两字节 |
| 0x0800-0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx | 三字节 |
| 0x010000-0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 四字节 |
举个例子:
“啊”的unicode码位是0x554A,也就对应着三字节内存空间。而0x554A的二进制表示是0101010101001010
将其填充到1110xxxx 10xxxxxx 10xxxxxx 中得到11100101 10010101 10001010用十六进制表示则是0xE5 95 8A。这就是“啊”以UTF-8编码存储在内存中的值。
如何判断是GBK还是UTF-8编码
2. UTF-16
UTF-16 也是一种变长字符编码, 这种编码方式比较特殊, 它将字符编码成 2 字节 或者 4 字节
具体的编码规则如下:
- 对于 Unicode 码小于 0x10000 的字符, 使用 2 个字节存储,并且是直接存储 Unicode 码,不用进行编码转换
- 对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4 个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为 110111, 前后部分各剩余 10 位二进制表示符号的 Unicode 码 减去 0x10000 的结果
- 大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码
3.UTF-32
始终占4字节,直接存储Unicode码,不需要编码转换,虽然浪费了空间,但提高了效率。
五、ANSI
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,且编码方式根据依据操作系统。 即如果使用中文操作系统,则按GBK(或者GB18030)编码解码。而如果使用的是日文操作系统则按JIS编码解码。
这意味着如果将中文操作系统中以ANSI格式保存的文件发送给一个日文操作系统的计算机,打开后大概率会乱码。
六、BOM
1. 字节序
对于中文字符“中”的Unicode码0x4E2D,在内存中可能会有两种存储方式:
4E在高地址,2D在低地址。(小端:高位字节在高地址,低位字节在低地址)
2D在高地址,4E在低地址。(大端:低位字节在高地址,高位字节在低地址)
这就意味着在数据流上存在4E 2D和2D 4E两种形式来表示“中”这个Unicode下的字符。
2. BOM
为了处理字节序的问题,引入了BOM的概念。
BOM 是 byte-order mark 的缩写,是 "字节序标记" 的意思, 它常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32 编码的标记
在 Unicode 编码中有一个叫做 "零宽度非换行空格" 的字符 ( ZERO WIDTH NO-BREAK SPACE ), 用字符 FEFF 来表示
对于 UTF-16 ,如果接收到以 FEFF 开头的字节流, 就表明是大端字节序,如果接收到 FFFE, 就表明字节流 是小端字节序
对于UTF-32,如果接收到00 00 FE FF 开头的字节流就表示是大端字节序,如果接收到FF FE 00 00开头的字节流就表示是小端字节序。
UTF-8 没有字节序问题,上述字符只是用来标识它是 UTF-8 文件,而不是用来说明字节顺序的。"零宽度非换行空格" 字符 的 UTF-8 编码是 EF BB BF, 所以如果接收到以 EF BB BF 开头的字节流,就知道这是UTF-8 文件 。
| 编码 | 开头 | 字节序 |
| UTF-8 | EF BB BF | 无 |
| UTF-16 | FE FF | 大端 |
| FF FE | 小端 | |
| UTF-32 | 00 00 FE FF | 大端 |
| FF FE 00 00 | 小端 |