1. 数据并行(Data Parallel)
1.1常规数据并行
有一张显卡(例如rank 0显卡)专门用于存储模型参数、梯度信息和更新模型参数。将训练数据分成多份(份数等于显卡数量),每张卡上的模型参数相同,进行前向和反向传播后,每张卡上都计算得到对应部分数据的梯度,然后对多张卡上的梯度进行reduce操作,将平均后的梯度结果存放在专门的显卡上,然后在专门的显卡上利用优化器进行参数更新。最后将更新后的参数再broadcast到所有显卡上,重复上述过程
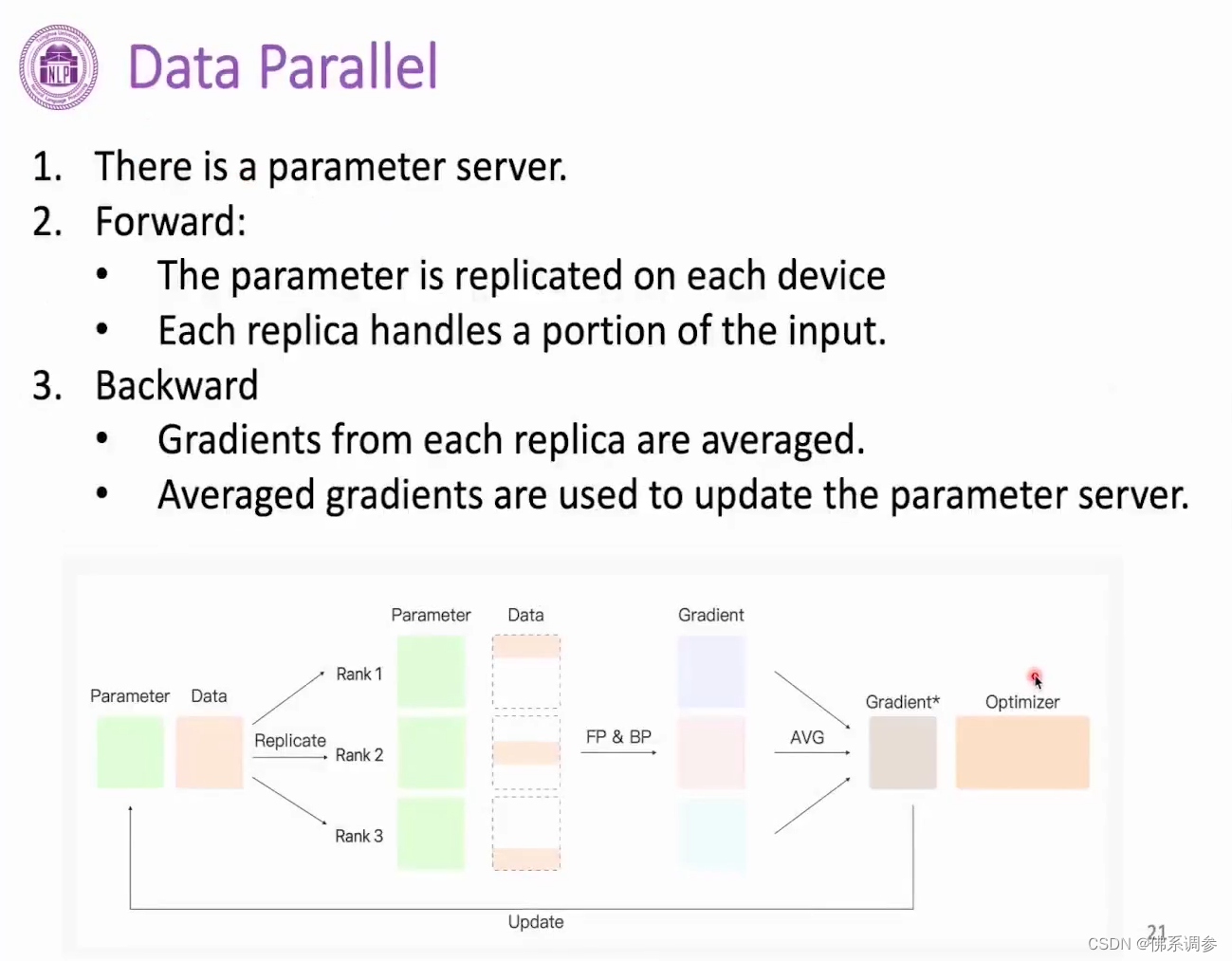
1.2 distributed data parallel(分布式数据并行)
区别:不需要专门的参数服务器
初始时每张显卡上都有相同的模型参数,同样将训练数据均分成多份,每张卡上利用单独一小份的数据进行前向和反向得到梯度,然后将多张卡上的梯度参数all reduce到所有的显卡上,这样每张显卡上的梯度信息也是完全一致的,同时优化器的历史信息数据也是完全一致的,这样便可以在每一张显卡上单独进行参数更新,并且能够保证每张卡上更新后的模型参数也是完全一致的。
总结:每张卡上单独进行参数更新

1.3 数据并行带来的显存优化效果
transformer中,显卡上存储的模型中间结果(即是每一层的输入,也可以理解成上一层的输出)的维度是[batch, Len, Dim], 多卡数据并行后,每张显卡上存储的模型中间结果的维度变成[batch/卡数, Len, Dim]