索引失效情况及避免方式
建表+数据sql
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
insert into staffs(NAME,age,pos,add_time) values('z3',22,'manager',NOW());
insert into staffs(NAME,age,pos,add_time) values('July',23,'dev',NOW());
insert into staffs(NAME,age,pos,add_time) values('2000',23,'dev',NOW());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YCctVEVL-1687839189065)(assets/1687839053755-58.png)]](https://img-blog.csdnimg.cn/470a8e70d6e645cd85f3d6b6de5a4a5b.png)
创建复合索引
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(name,age,pos);
索引失效相关法则
- 全值匹配我最爱。
- 最佳左前缀法则。
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
- 索引中范围条件右边的字段会全部失效。
- 尽量使用覆盖索引(只访问索引的查询,索引列和查询列一致),减少
SELECT *。 - MySQL在使用
!=或者<>的时候无法使用索引会导致全表扫描。 is null、is not null也无法使用索引。like以通配符开头%abc索引失效会变成全表扫描(使用覆盖索引就不会全表扫描了)。- 字符串不加单引号索引失效。
- 少用
or,用它来连接时会索引失效。
全值匹配我最爱
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos ='dev';
最佳左前缀法则
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25;
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos ='dev';
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND pos ='dev';
EXPLAIN SELECT * FROM staffs WHERE age = 25 AND pos ='dev';
EXPLAIN SELECT * FROM staffs WHERE pos ='dev';
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SuIpAGwY-1687839189066)(assets/1687839053755-59.png)]](https://img-blog.csdnimg.cn/86c1f6d051a34d0ba1a7963c8cabf113.png)
没有带头大哥,全表扫描
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EHr4fSKh-1687839189067)(assets/1687839053755-60.png)]](https://img-blog.csdnimg.cn/937e852f5e4d4e52b0b156fb6978d703.png)
中间兄弟断了,只能用到部分索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l3l0hAVF-1687839189067)(assets/1687839053755-61.png)]](https://img-blog.csdnimg.cn/7b980db892b84b16af15b09e80691f42.png)
最佳左前缀法则:如果索引是多字段的复合索引,要遵守最佳左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的字段。
口诀:带头大哥不能死,中间兄弟不能断,后面可以没有。(可以参考列车,车头不能没有,中间车厢不能没有,后面车厢没有也可以开)
索引列上不能做任何操作(如计算、函数、类型转换)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VpNISCj3-1687839189067)(assets/1687839053755-62.png)]](https://img-blog.csdnimg.cn/c06e6cbedae949d6aee844011856cfcf.png)
口诀:索引列上不计算。
索引中范围条件右边的字段会全部失效
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nv9HMBJW-1687839189067)(assets/1687839053755-63.png)]](https://img-blog.csdnimg.cn/de6bafc33b07453082dd9ef3b59bec67.png)
当然,还是用到了age列的索引的,看key_len是78就知道了,不用到的话,key_len是74
由此可知,查询范围的字段使用到了索引,但是范围之后的索引字段会失效。
口诀:范围之后全失效。
尽量用覆盖索引,减少select*使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KVWtvaea-1687839189068)(assets/1687839053755-64.png)]](https://img-blog.csdnimg.cn/59d4df8b73c64abf946375f14fd9c623.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TJ2km6FP-1687839189068)(assets/1687839053755-65.png)]](https://img-blog.csdnimg.cn/739683cf16f64cd6b754909e068e8045.png)
口诀:查询一定不用\*。
MySQL在使用!=或者<>的时候无法使用索引会导致全表扫描
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yoWALgU4-1687839189068)(assets/1687839053755-66.png)]](https://img-blog.csdnimg.cn/5e4b2214cdf4492482939d56092e874e.png)
虽然索引会失效,但是业务需要的话,没办法还是要写的
is null、is not null也无法使用索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SwBKqbmb-1687839189068)(assets/1687839053755-67.png)]](https://img-blog.csdnimg.cn/b5a4f039273c414eb7fbf8c0b7d94239.png)
like百分加右边
建表sql
CREATE TABLE tbl_user(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`age`INT(11) DEFAULT NULL,
`email` VARCHAR(20) DEFAULT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
insert into tbl_user(NAME,age,email) values('1aa1',21,'b@163.com');
insert into tbl_user(NAME,age,email) values('2aa2',222,'a@163.com');
insert into tbl_user(NAME,age,email) values('3aa3',265,'c@163.com');
insert into tbl_user(NAME,age,email) values('4aa4',21,'d@163.com');
案例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2EriXhgA-1687839189068)(assets/1687839053755-68.png)]](https://img-blog.csdnimg.cn/48a9aa61420841e1bba072196d21597b.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bxeJxu6a-1687839189069)(assets/1687839053755-69.png)]](https://img-blog.csdnimg.cn/987ae2a07ce8463a84bd29249ed5ee4a.png)
生产环境中就要使用两边%,怎么优化,希望索引不失效,使用覆盖索引来解决
创建索引sql
CREATE INDEX idx_user_nameAger ON tbl_user(NAME,age);
查询sql
EXPLAIN SELECT NAME,age FROM tbl_user WHERE NAME LIKE '%aa%';
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wS2tIdHo-1687839189069)(assets/1687839053755-70.png)]](https://img-blog.csdnimg.cn/74b93d9f4ea94bedac4cfddc9716d31d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sc2YGPJZ-1687839189069)(assets/1687839053755-71.png)]](https://img-blog.csdnimg.cn/46a154e907944ea6b8fd96bc11c7e124.png)
id是主键索引,虽然不在复合索引内部,但是查询的时候也可以被使用上
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vsWh4lQy-1687839189069)(assets/1687839053755-72.png)]](https://img-blog.csdnimg.cn/57e741d2e87246abaed057105cad233e.png)
上面的索引都没有失效
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lISzd5kO-1687839189069)(assets/1687839053755-73.png)]](https://img-blog.csdnimg.cn/5f18777d2d414d0090cd7e8a9dbafd2d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ym62YQrf-1687839189069)(assets/1687839053755-74.png)]](https://img-blog.csdnimg.cn/bd8f1896ca294513a7aabfef78e83ab3.png)
口诀:覆盖索引保两边。
字符要加单引号
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RZX7sqo0-1687839189069)(assets/1687839053755-75.png)]](https://img-blog.csdnimg.cn/8cc460b4fbcc4e78a6762aed0043cd85.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r5Y1mpFC-1687839189070)(assets/1687839053755-76.png)]](https://img-blog.csdnimg.cn/480db9fe71f54c19857bed06c8c03292.png)
因为,mysql底层会自动做类型转换,将数据转化为了字符串,其实就是对索引列做了操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zW5OTcm4-1687839189070)(assets/1687839053756-77.png)]](https://img-blog.csdnimg.cn/ce080d510d784eeeba40dedd323e54d6.png)
口诀:字符要加单引号。
除此之外,要避免其他隐式转换
少用or,用它来连接时会索引失效
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bgONPy9T-1687839189070)(assets/1687839053756-78.png)]](https://img-blog.csdnimg.cn/bf7ef66137f84438b774d91473f1eedb.png)
索引相关题目
假设index(a,b,c)
| Where语句 | 索引是否被使用 |
|---|---|
| where a = 3 | Y,使用到a |
| where a = 3 and b = 5 | Y,使用到a,b |
| where a = 3 and b = 5 | Y,使用到a,b,c |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | N,没有用到a字段 |
| where a = 3 and c = 5 | 使用到a,但是没有用到c,因为b断了 |
| where a = 3 and b > 4 and c = 5 | 使用到a,b,但是没有用到c,因为c在范围之后 |
| where a = 3 and b like ‘kk%’ and c = 4 | Y,a,b,c都用到 |
| where a = 3 and b like ‘%kk’ and c = 4 | 只用到a |
| where a = 3 and b like ‘%kk%’ and c = 4 | 只用到a |
| where a = 3 and b like ‘k%kk%’ and c = 4 | Y,a,b,c都用到 |
面试题分析
建表sql
CREATE TABLE test03(
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
c1 CHAR(10),
c2 CHAR(10),
c3 CHAR(10),
c4 CHAR(10),
c5 CHAR(10)
);
INSERT INTO test03(c1,c2,c3,c4,c5) VALUES('a1','a2','a3','a4','a5');
INSERT INTO test03(c1,c2,c3,c4,c5) VALUES('b1','b2','b3','b4','b5');
INSERT INTO test03(c1,c2,c3,c4,c5) VALUES('c1','c2','c3','c4','c5');
INSERT INTO test03(c1,c2,c3,c4,c5) VALUES('d1','d2','d3','d4','d5');
INSERT INTO test03(c1,c2,c3,c4,c5) VALUES('e1','e2','e3','e4','e5');
CREATE INDEX idx_test03_c1234 ON test03(c1,c2,c3,c4);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YZe9zXpV-1687839189070)(assets/1687839053756-79.png)]](https://img-blog.csdnimg.cn/d53b2baf811746608748b5dda0bb18ab.png)
案例
-- 1.全值匹配 用到索引c1 c2 c3 c4全字段
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c3 = 'a3' AND c4 = 'a4';
-- 2.用到索引c1 c2 c3 c4全字段 MySQL的查询优化器会优化SQL语句的顺序
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c4 = 'a4' AND c3 = 'a3';
-- 3.用到索引c1 c2 c3 c4全字段 MySQL的查询优化器会优化SQL语句的顺序
EXPLAIN SELECT * FROM test03 WHERE c4 = 'a4' AND c3 = 'a3' AND c2 = 'a2' AND c1 = 'a1';
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JPHQyP7M-1687839189070)(assets/1687839053756-80.png)]](https://img-blog.csdnimg.cn/c5d5f44c84ab4fc39e4dd3aea21be787.png)
虽然sql中字段的顺序和创建索引时的字段顺序的不同,但是sql优化器可以解析成相同顺序的。但是最好索引怎么创建的,就怎么用,避免sql再去翻译一次
-- 4.用到索引c1 c2 c3字段,c4字段失效,范围之后全失效
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c3 > 'a3' AND c4 = 'a4';
-- 5.用到索引c1 c2 c3 c4全字段 MySQL的查询优化器会优化SQL语句的顺序
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c4 > 'a4' AND c3 = 'a3';
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-keK8weOM-1687839189070)(assets/1687839053756-81.png)]](https://img-blog.csdnimg.cn/044c3935b0ab458eb36b2ad4a1d01b33.png)
-- 6.用到了索引c1 c2 c3三个字段, c1和c2两个字段用于查找, c3字段用于排序了但是没有统计到key_len中,c4字段失效
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c4 = 'a4' ORDER BY c3;
-- 7.用到了索引c1 c2 c3三个字段,c1和c2两个字段用于查找, c3字段用于排序了但是没有统计到key_len中
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' ORDER BY c3;
-- 8.用到了索引c1 c2两个字段,c4失效,c1和c2两个字段用于查找,c4字段排序产生了Using filesort说明排序没有用到c4字段
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' ORDER BY c4;
-- 9.用到了索引c1 c2 c3三个字段,c1用于查找,c2和c3用于排序
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c5 = 'a5' ORDER BY c2, c3;
-- 10.用到了c1一个字段,c1用于查找,c3和c2两个字段索引失效(没有按照顺序),产生了Using filesort
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c5 = 'a5' ORDER BY c3, c2;
-- 11.用到了c1 c2 c3三个字段,c1 c2用于查找,c2 c3用于排序
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' ORDER BY c2, c3;
-- 12.用到了c1 c2 c3三个字段,c1 c2用于查找,c2 c3用于排序
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c5 = 'a5' ORDER BY c2, c3;
-- 13.用到了c1 c2 c3三个字段,c1 c2用于查找,c2 c3用于排序 没有产生Using filesort
-- 因为之前c2这个字段已经确定了是'a2'了,这是一个常量,再去ORDER BY c3,c2 这时候c2已经不用排序了!
-- 所以没有产生Using filesort 和(10)进行对比学习!
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c2 = 'a2' AND c5 = 'a5' ORDER BY c3, c2;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pOGntbWa-1687839189070)(assets/1687839053756-82.png)]](https://img-blog.csdnimg.cn/9af86ddb61fe4cabb6add345359a1037.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MxHCxCtU-1687839189071)(assets/1687839053756-83.png)]](https://img-blog.csdnimg.cn/9f636568cdc645a3b35fb52f59173262.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pluao0Cc-1687839189071)(assets/1687839053756-84.png)]](https://img-blog.csdnimg.cn/61d4189cee0447b6a124f0e577b4ac39.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b7EZL6H6-1687839189071)(assets/1687839053756-85.png)]](https://img-blog.csdnimg.cn/1c7152885ab1492bb948f4d6a5b15d37.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NsvtaOUR-1687839189071)(assets/1687839053756-86.png)]](https://img-blog.csdnimg.cn/1db37481c76d4b93ba88006443f247a2.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jasFac5J-1687839189071)(assets/1687839053756-87.png)]](https://img-blog.csdnimg.cn/7b89133bab654a038805359c8df3ac3e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ETYErY2i-1687839189071)(assets/1687839053756-88.png)]](https://img-blog.csdnimg.cn/0ab356b4b60e4dc1bf52660872ea9249.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2aNFfVyd-1687839189071)(assets/1687839053756-89.png)]](https://img-blog.csdnimg.cn/faf22d8396f64d5ebbc20f4c31e2b1d4.png)
-- 14.用到c1 c2 c3三个字段,c1用于查找,c2 c3用于排序,c4失效
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c4 = 'a4' GROUP BY c2,c3;
-- 15.用到c1这一个字段,c4失效,c2和c3排序失效产生了Using filesort
EXPLAIN SELECT * FROM test03 WHERE c1 = 'a1' AND c4 = 'a4' GROUP BY c3,c2;
GROUP BY基本上都需要进行排序,索引优化几乎和ORDER BY一致,但是GROUP BY会有临时表的产生。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-79QCKjsS-1687839189071)(assets/1687839053756-90.png)]](https://img-blog.csdnimg.cn/6f6723b08bd04af8a7b31361cd07d6bd.png)
group by表面上是叫做分组,但是分组之前必定排序,会有临时表产生。 group by的排序法则、索引原则与order by几乎是一致的,有一个不一致的地方,group by有having
总结
索引优化的一般性建议:
- 对于单值索引,尽量选择针对当前
query过滤性更好的索引。 - 在选择复合索引的时候,当前
query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。 - 在选择复合索引的时候,尽量选择可以能够包含当前
query中的where子句中更多字段的索引。 - 尽可能通过分析统计信息和调整
query的写法来达到选择合适索引的目的。
口诀:
- 带头大哥不能死
- 中间兄弟不能断
- 索引列上不计算
- 范围之后全失效
- 覆盖索引尽量用
- 不等有时会失效
- like百分加右边
- 字符要加单引号
- 一般SQL少用or
索引建立与优化[案例分析]
单表案例
建表sql
CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT (10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL ,
`views` INT(10) UNSIGNED NOT NULL ,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
insert into `article`(author_id,category_id,views,comments,title,content) values
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');
查询category_id为1且comments大于1的情况下,views最多的article_id
查询数据
SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NDa6iijv-1687848419304)(assets/1687838420135-19.png)]](https://img-blog.csdnimg.cn/ce33cf538e3d400aa0b73f46ad2dbd7d.png)
查看sql的分析报告
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VRHr0TCi-1687848419304)(assets/1687838420110-1.png)]](https://img-blog.csdnimg.cn/3ea263c8ef8b454db26fd0668cdfa097.png)
查看索引
show index from article
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5cWJ3fbs-1687848419305)(assets/1687838420110-2.png)]](https://img-blog.csdnimg.cn/2686dc0f0eaa4f369a13157933306960.png)
【优化1:创建索引】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Eatwek3C-1687848419305)(assets/1687838420110-3.png)]](https://img-blog.csdnimg.cn/8665362d18274b1ab75e2272961fb882.png)
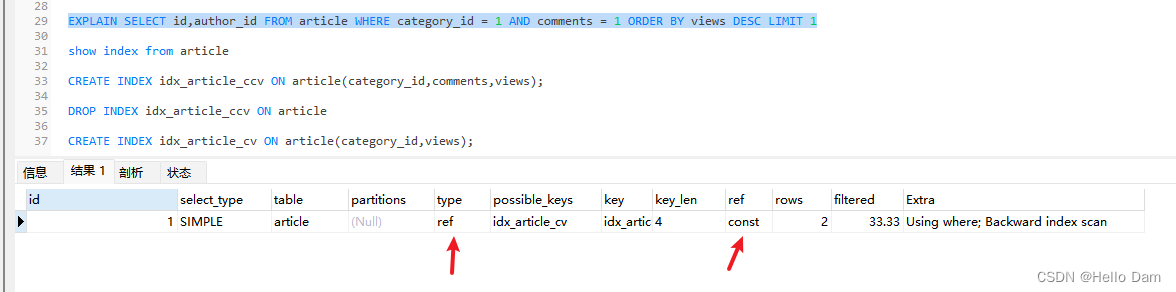
CREATE INDEX idx_article_ccv ON article(category_id,comments,views);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e6E4tizX-1687848419305)(assets/1687838420110-4.png)]](https://img-blog.csdnimg.cn/79215924ae0d4155b321a70f7c6ff62f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tptkic4K-1687848419306)(assets/1687838420110-5.png)]](https://img-blog.csdnimg.cn/2ab8e4cd7ea94decb831159055704fb4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fPB92qaO-1687848419306)(assets/1687838420110-6.png)]](https://img-blog.csdnimg.cn/8d8aec23477d45adb4d3b30f8b2a8a72.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UhNSOyyf-1687848419306)(assets/1687838420110-7.png)]](https://img-blog.csdnimg.cn/029fd069647042a5abc8f3fe35b3b753.png)
**所以,范围之后的索引会失效。**说明这个索引建得不好,先删除
DROP INDEX idx_article_ccv ON article
【优化2:绕过comments直接给category_id,views创建索引】
CREATE INDEX idx_article_cv ON article(category_id,views);
两表案例
建表sql
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
);
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
);
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QIdntA7u-1687848419307)(assets/1687838420110-9.png)]](https://img-blog.csdnimg.cn/39371d317346465fb97f2974379c079f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-10M4PNv4-1687848419307)(assets/1687838420110-10.png)]](https://img-blog.csdnimg.cn/92051a54461a4aff8b6321c35cc75c09.png)
class表 左连接 book表
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card=book.card;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BXwJovPN-1687848419307)(assets/1687838420110-11.png)]](https://img-blog.csdnimg.cn/ed494096671143faae017867b7b75670.png)
有ALL,需要优化
【优化1:给右表book.card创建索引】
CREATE INDEX idx_book_card ON book(card);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oGBR4uqc-1687848419307)(assets/1687838420110-12.png)]](https://img-blog.csdnimg.cn/75ea1f14bea94fe382ff94d6969ca2d8.png)
【优化2:给左表class.card创建索引】
CREATE INDEX idx_class_card ON class(card);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qqxl3SsE-1687848419307)(assets/1687838420110-13.png)]](https://img-blog.csdnimg.cn/5dcd6bf3fda44d7f85622dba68f11fc1.png)
结论:左连接,索引加右表;右连接,索引加左表。因为左表的数据本身就全都要有。但是DBA建立索引要考虑的是全局sql,不能因为一个sql不好就换索引,我们要让sql来适应索引,比如两个表的位置交换、左连接换成右连接
三表案例
建表
在前面表的基础上加上这个
CREATE TABLE IF NOT EXISTS `phone`(
`phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
)ENGINE = INNODB;
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xqmwRSXz-1687848419308)(assets/1687838420110-14.png)]](https://img-blog.csdnimg.cn/5b9446b48af54abebff36533639fe0ad.png)
三表连接查询
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book.card=phone.card;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eyQlazNB-1687848419308)(assets/1687838420110-15.png)]](https://img-blog.csdnimg.cn/3a992f21e6204914b1a9253f037566ec.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SExQwJcg-1687848419308)(assets/1687838420110-16.png)]](https://img-blog.csdnimg.cn/d5347c14258c47ab91c33b46a45af68e.png)
【优化:添加索引】
CREATE INDEX idx_book_card ON book(card);
CREATE INDEX idx_phone_card ON phone(card);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RcP0In2c-1687848419308)(assets/1687838420110-17.png)]](https://img-blog.csdnimg.cn/7c93566ae183419b95d4898864ce8da6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N9ReWiGv-1687848419309)(assets/1687838420111-18.png)]](https://img-blog.csdnimg.cn/853e84a6d1b94339bbd5d3fa5c3172f8.png)
Join语句优化:
- 尽可能减少Join语句中的循环嵌套次数
- 用小数据的表来驱动大数据的表,如用
数据类别表来驱动书籍表- 优先优化NestedLoop(嵌套循环)的内存循环
- 保证Join的驱动表的Join条件字段已经被索引,对于
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card=book.card;,要保证book.card被索引- 当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置