查询优化
小表驱动大表
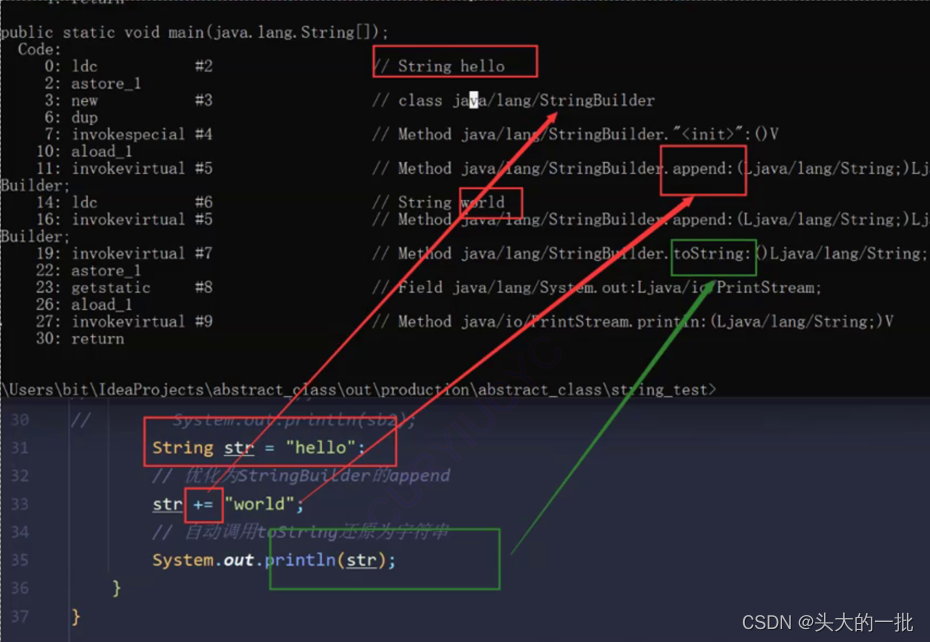
优化原则:对于MySQL数据库而言,永远都是小表驱动大表。
/**
* 举个例子:可以使用嵌套的for循环来理解小表驱动大表。
* 以下两个循环结果都是一样的,但是对于MySQL来说不一样,
* 第一种可以理解为,和MySQL建立5次连接每次查询1000次。
* 第一种可以理解为,和MySQL建立1000次连接每次查询5次。
*/
for(int i = 1; i <= 5; i ++){
for(int j = 1; j <= 1000; j++){
}
}
// ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
for(int i = 1; i <= 1000; i ++){
for(int j = 1; j <= 5; j++){
}
}
in和exists的选择
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e5qJH9Y3-1687864545057)(assets/1687864518618-8.png)]](https://img-blog.csdnimg.cn/27fbd83fe6c94e8e946664f90a308468.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PtHndrhg-1687864545058)(assets/1687864518614-1.png)]](https://img-blog.csdnimg.cn/4f72ff36e7b14493ba71db6b9bb4239f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nRL7nXLe-1687864545059)(assets/1687864518614-2.png)]](https://img-blog.csdnimg.cn/f63adeefd82548c5bc4f1dade6c45273.png)
in写法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-diuqmG1d-1687864545059)(assets/1687864518614-3.png)]](https://img-blog.csdnimg.cn/3a0d8364c58644e4b89bcfb622d7154b.png)
exits写法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lYaEBSbi-1687864545059)(assets/1687864518614-4.png)]](https://img-blog.csdnimg.cn/401d8723c32d478ebb301dd3d8c62821.png)
ORDER BY优化
建表sql
CREATE TABLE `talA`(
`age` INT,
`birth` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO `talA`(`age`) VALUES(22);
INSERT INTO `talA`(`age`) VALUES(23);
INSERT INTO `talA`(`age`) VALUES(24);
/* 创建索引 */
CREATE INDEX idx_A_ageBirth ON `talA`(`age`, `birth`);
案例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vENkiDVY-1687864545059)(assets/1687864518614-5.png)]](https://img-blog.csdnimg.cn/c9be69ef9a724c03ae3e9cf3483f7fb6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m97sBdtW-1687864545059)(assets/1687864518614-6.png)]](https://img-blog.csdnimg.cn/71a379cef2244b43abfc8bda33b01414.png)
要降序查询数据,可以先按照升序排序查询出数据,然后在内存中反过来即可
结论
ORDER BY子句,尽量使用索引排序,避免使用Using filesort排序。MySQL支持两种方式的排序,FileSort和Index,Index的效率高,它指MySQL扫描索引本身完成排序。FileSort方式效率较低。
ORDER BY满足两情况,会使用Index方式排序:
ORDER BY语句使用索引最左前列(即最佳左前缀原则)。- 使用
WHERE子句与ORDER BY子句条件列组合满足索引最左前列。
结论:尽可能在索引列上完成排序操作,遵照索引建的最佳左前缀原则。
如果不在索引列上,File Sort有两种算法:MySQL就要启动双路排序算法和单路排序算法
1、双路排序算法:MySQL4.1之前使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,读取行指针和ORDER BY列,対他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。一句话,从磁盘取排序字段,在**buffer**中进行排序,再从磁盘取其他字段。
取一批数据,要对磁盘进行两次扫描,众所周知,IO是很耗时的,所以在MySQL4.1之后,出现了改进的算法,就是单路排序算法。
2、单路排序算法:从磁盘读取查询需要的所有列,按照ORDER BY列在buffer対它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间,因为它把每一行都保存在内存中了。(少一次IO)
由于单路排序算法是后出的,总体而言效率好过双路排序算法。
但是单路排序算法有问题:如果SortBuffer缓冲区太小,导致从磁盘中读取所有的列不能完全保存在SortBuffer缓冲区中,这时候单路复用算法就会出现问题(一次拿不完数据,需要拿多次,导致了多次IO操作),反而性能不如双路复用算法。
单路复用算法的优化策略:
- 增大
sort_buffer_size参数的值。 - 增大
max_length_for_sort_data参数的值。
提高ORDER BY排序的速度:
-
ORDER BY时使用SELECT *是大忌,查什么字段就写什么字段,这点非常重要。在这里的影响是:- 当查询的字段大小总和小于
max_length_for_sort_data而且排序字段不是TEXT|BLOB类型时,会使用单路排序算法,否则使用多路排序算法。- 两种排序算法的数据都有可能超出
sort_buffer缓冲区的容量,超出之后,会创建tmp临时文件进行合并排序,导致多次IO,但是单路排序算法的风险会更大一些,所以要增大sort_buffer_size参数的设置。 -
尝试提高
sort_buffer_size:不管使用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。 -
尝试提高
max_length_for_sort_data:提高这个参数,会增加用单路排序算法的概率。但是如果设置的太高,数据总容量sort_buffer_size的概率就增大,明显症状是高的磁盘IO活动和低的处理器使用率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NiNFN9jW-1687864545060)(assets/1687864518614-7.png)]](https://img-blog.csdnimg.cn/a884b0a0cb704fe68ca6015eb9514d54.png)
GORUP BY优化
优化思路和ORDER BY基本一致
GROUP BY实质是先排序后进行分组,遵照索引建的最佳左前缀。- 当无法使用索引列时,会使用
Using filesort进行排序,增大max_length_for_sort_data参数的设置和增大sort_buffer_size参数的设置,会提高性能。 WHERE执行顺序高于HAVING,能写在WHERE限定条件里的就不要写在HAVING中了。