🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

1.TF-IDF算法介绍
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。简单来说就是:一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。这也就是TF-IDF的含义。

TF(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
公式:
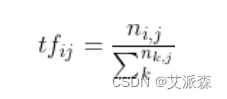
(术语 t 在文档中出现的次数) / (文档中的术语总数)
但是,需要注意, 一些通用的词语对于主题并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF不合适的。权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。IDF就是在完成这样的工作。
IDF(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
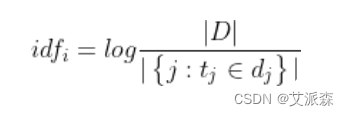
log_e(文档总数/包含术语 t 的文档数)
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|。
IDF用于衡量一个术语的重要性。在计算 TF 时,所有项都被认为同样重要。然而,众所周知,某些术语,如"是","的"和"那个",可能会出现很多次,但并不重要。
TF-IDF(Term Frequency-Inverse Document Frequency)
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语,表达为 :
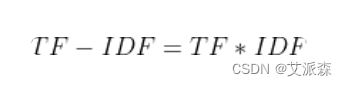
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
2.TF-IDF算法步骤
第一步,计算词频:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

第二步,计算逆文档频率:
这时,需要一个语料库(corpus),用来模拟语言的使用环境,

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF:
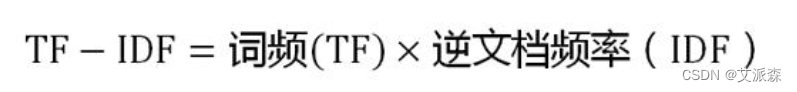
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
3.jieba库实现
jieba库实现TF-IDF算法主要是通过调用extract_tags函数实现。extract_tags函数参数介绍如下:
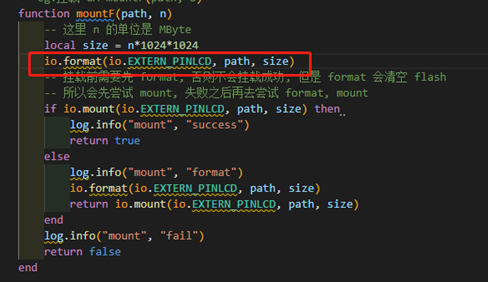
def extract_tags(self, sentence, topK=20, withWeight=False, allowPOS=(), withFlag=False):
"""
Extract keywords from sentence using TF-IDF algorithm.
Parameter:
- topK: return how many top keywords. `None` for all possible words.
- withWeight: if True, return a list of (word, weight);
if False, return a list of words.
- allowPOS: the allowed POS list eg. ['ns', 'n', 'vn', 'v','nr'].
if the POS of w is not in this list,it will be filtered.
- withFlag: only work with allowPOS is not empty.
if True, return a list of pair(word, weight) like posseg.cut
if False, return a list of words
"""-sentence:要提取关键词的语句,必传参数
-topK:输入权重最高的K个词,默认输出前20个词
-withWeight:如果为True,则输出列表(词,权重)的形式;False则直接返回词语列表。默认为False
-allowPOS:允许出现的词性列表,比如['ns', 'n', 'vn', 'v','nr'] ,如果词语不在词性列表中将会被过滤掉。默认不过滤任何词性
-withFlag:没啥用,不用管,直接默认即可。
示例:
在提取关键词之前可以加上自定义词典和停用词库,这里我用一条评论文本进行示范,注意使用jieba中的extract_tags函数不需要进行分词,直接传入原始文本即可。
import jieba.analyse
import jieba
jieba.load_userdict('自定义词典.txt') # 应用自定义词典
jieba.analyse.set_stop_words('停用词库.txt') # 去除自定义停用词
text = '大唐不夜城,不夜城趣味性很高,里面地方特色东西好吃,也有星巴克麦当劳等等选择,有不少场表演,外景夜景一定要薅一个,其它地方很难有这般景象了。娱乐体验了不倒翁,还有十二时辰里面表演更加精彩、内景拍照不错,簋唐楼可以尝试一下沉浸剧本杀……'
# 注意:使用TF-IDF不需要进行分词,直接将原始文本传入使用
jieba.analyse.extract_tags(text,topK=20) # 默认输出前20个关键词,数值可自行修改
# 如果想获取关键词的权重可以加上
jieba.analyse.extract_tags(text,topK=20,withWeight=True) 
# 只筛选出n名词的单词
jieba.analyse.extract_tags(text,topK=20,allowPOS=['n'])
可以发现,它只将n名词的词语打印了出来。
关于其他词性的代码,具体可以参考下面表格:
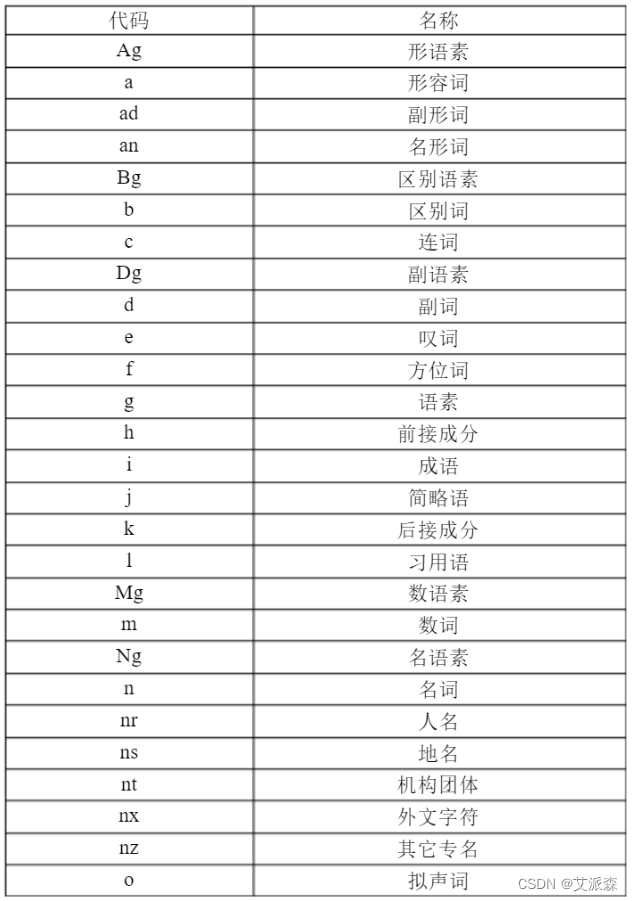
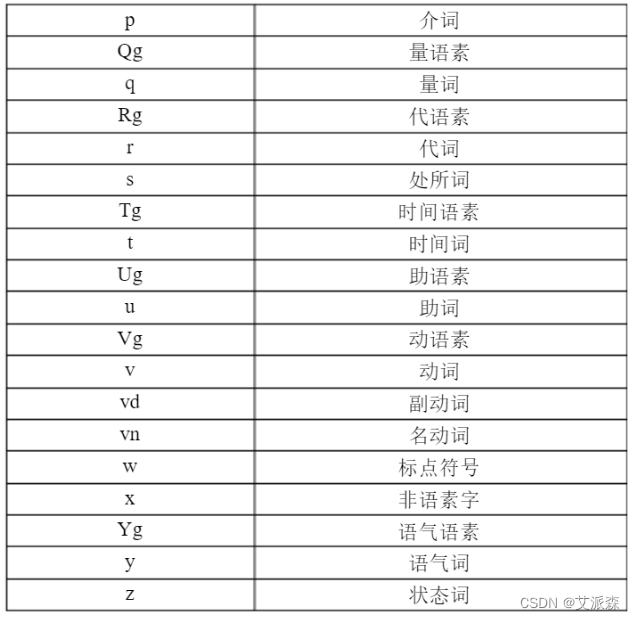
案例实战
任务:使用TF-IDF提取红楼梦小说中的关键词及其权重
首先读取红楼梦小说
with open('HLM.txt')as f:
content = f.read()
content
接着使用re正则去除标点符号等异常字符,只保留中文
import re
new_text = "".join(re.findall('[\u4e00-\u9fa5]+', content, re.S))
new_text
最后使用jieba中的extract_tags函数实现TF-IDF提取关键词
import jieba.analyse
jieba.load_userdict('自定义词典.txt') # 应用自定义词典
jieba.analyse.set_stop_words('停用词库.txt') # 去除自定义停用词
jieba.analyse.extract_tags(new_text,withWeight=True)