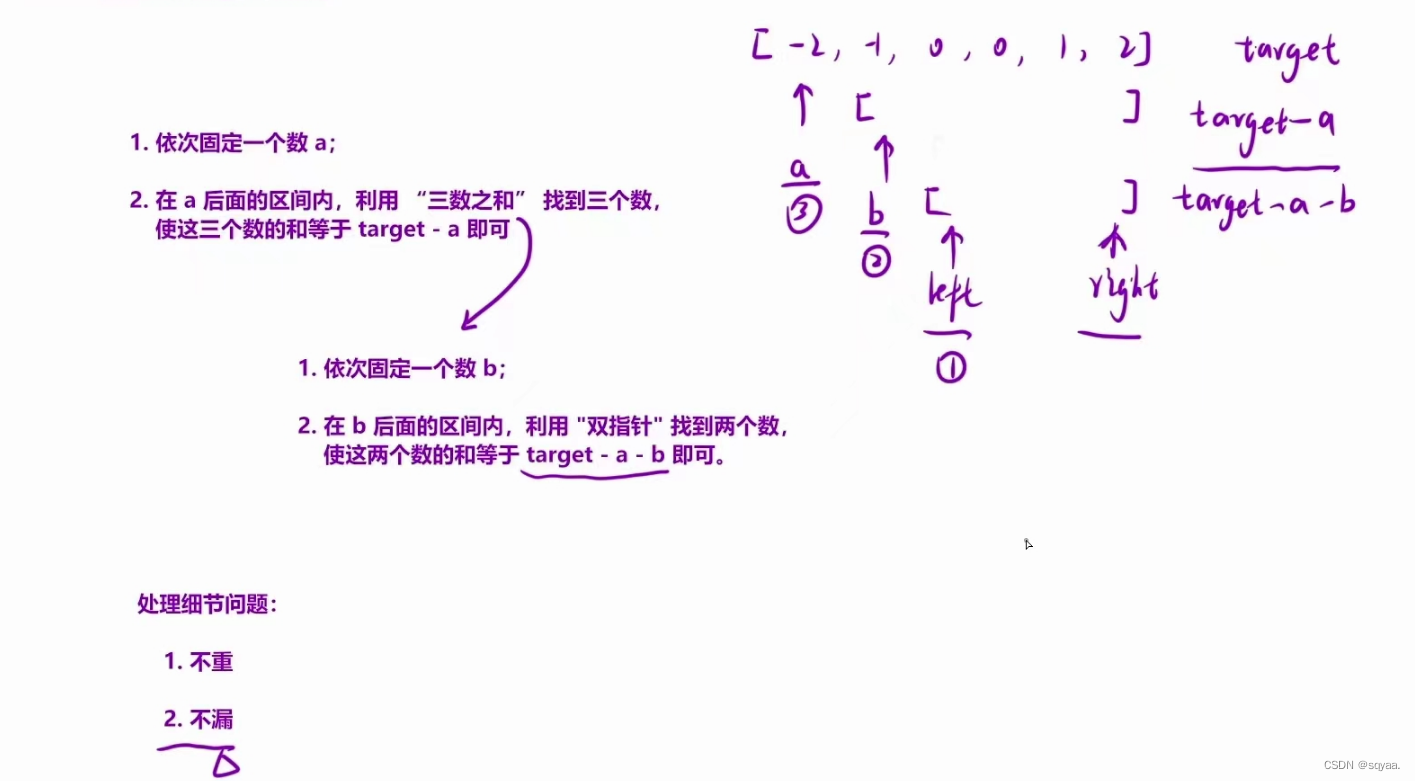
目录
性能调优
插入性能调优
查询性能调优
硬件环境
系统参数
性能调优
插入性能调优
“数据插入”到“数据写入磁盘”的基本流程请参考 存储操作。
如果数据量小于单次插入上限(256 MB),批量插入比单条插入要高效得多。
系统配置中的两个参数对插入性能有影响:
- wal.enable
该参数用于开启或关闭 预写日志(WAL, Write Ahead Log) 功能(默认开启)。开启和关闭预写日志功能时,插入数据的流程分别如下:
- 开启预写日志功能时,预写日志模块先将数据写入磁盘,然后返回插入操作。
- 关闭预写日志功能时,数据插入速度更快。系统直接将数据写入内存中的可写缓冲区,并立即返回插入操作。
但是对于 删除操作 来说,打开预写日志功能时速度更快。为了保证数据的可靠性,我们建议打开预写日志。
- storage.auto_flush_interval
该参数是指后台落盘任务的间隔时间,默认值为 1 秒。根据 Milvus 数据段合并策略,增大该值可减少段合并的次数,减少磁盘 I/O,提高插入操作的吞吐量。

Milvus 无法搜索到在该时间间隔内未落盘的数据。
另外,建立集合时的参数 index_file_size 也对插入性能有影响。该参数的默认值为 1024 MB,最大值为 4096 MB。该参数越大,将文件合并到该值设定的大小所需的次数就越多,影响插入操作的吞吐量。该参数越小,则产生的数据段越多,查询性能可能会变差。
除了软件层面的因素外,网络带宽和存储介质对插入操作性能也有影响。
查询性能调优
影响查询性能的因素包括硬件环境、系统参数、索引、查询规模等。
硬件环境
- 使用 CPU 计算时,查询性能取决于 CPU 的主频、核心数和支持的指令集。
Milvus 在支持 AVX 指令集的 CPU 上的查询性能较好。
索引建立完成后(不包括 FLAT),索引文件需要额外占用磁盘空间,查询只需加载索引文件。
通过调用 get_collection_stats 接口,可准确获知查询一个集合所需的数据总量。
在 GPU 版本中,当目标向量数量大于等于该参数设定的值,将会启用 GPU 查询。该参数的默认值为 1000。

GPU 查询的性能取决于 CPU 将数据加载进显存的速度以及 GPU 的计算能力。在目标向量数量较少时,无法充分发挥出 GPU 并行计算的优势。只有当目标向量数量达到某个阈值后,GPU 的查询性能才会优于 CPU。在实际使用中,可根据实验对比得出该参数的理想值。
指定用于查询的 GPU 设备。对于数据插入和查询并发的场景,使用 GPU 建索引可避免后台建索引任务和查询任务争抢 CPU 资源。
指定用于建索引的 GPU 设备。对于查询目标向量数量较大的场景,使用多 GPU 可显著提高查询效率。
- 使用 GPU 计算时,查询性能取决于 GPU 的并行计算能力以及传输带宽。
-
系统参数
系统参数配置请参考 Milvus 服务端配置。
- cache.cache_size
-
该参数是指用于驻留查询数据的缓存空间大小,默认值为 4 GB。如果该缓存空间不足以容纳所需的数据,查询时会从磁盘临时加载数据,严重影响查询性能。因此,cache_size 应当大于查询所需的数据量。
- 浮点型原始向量的数据量可根据“向量总条数 × 维度 × 4”来估算。
- 二进制型原始向量的数据量可根据“向量总条数 × 维度 ÷ 8”来估算。
- IVF_FLAT 索引的数据量和其原始向量总数据量基本相等。
- IVF_SQ8 / IVF_SQ8H 索引的数据量相当于其原始向量总数据量的 25% ~ 30%。
- IVF_PQ 索引的数据量根据其参数变化,一般低于其原始向量总数据量的 10%。
- HNSW/RNSG/ANNOY 索引的数据量都大于其原始向量总数据量。
- gpu.gpu_search_threshold
- gpu.search_resources
- gpu.build_index_resources