文章目录
- ⭐前言
- ⭐requests库
- 💖 pip安装requests
- 💖 requests get
- 💖 requests post
- 结束
⭐前言
大家好,我是yma16,本文分享关于python的requests库用法。
该系列文章:
python爬虫_基本数据类型
python爬虫_函数的使用
⭐requests库
requests可以用来发送http请求。
对比浏览器发送的请求
- requests是在python的运行环境发送请求,不存在限制跨域,无ui界面,优势在于自动化
- 浏览器发送请求被浏览器的安全机制限制,会存在跨域(协议、端口、域名),ui界面,用户体验好
💖 pip安装requests
pip安装
$ pip install requests
requests的api方法
| api | description |
|---|---|
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
requests返回的api方法
| api | description |
|---|---|
| apparent_encoding | 编码方式 |
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| encoding | 解码 r.text 的编码方式 |
| headers | 返回响应头,字典格式 |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 “status_code” 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 “Not Found” 或 “OK” |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| text | 返回响应的内容,unicode 类型数据 |
| url | 返回响应的 URL |
💖 requests get
访问 csdn主页html
目标网站:https://www.csdn.net/
示例:
# 导入 requests
import requests
# 发送请求
response = requests.get('https://www.csdn.net/')
print(response)
print(response.text)
运行结果:
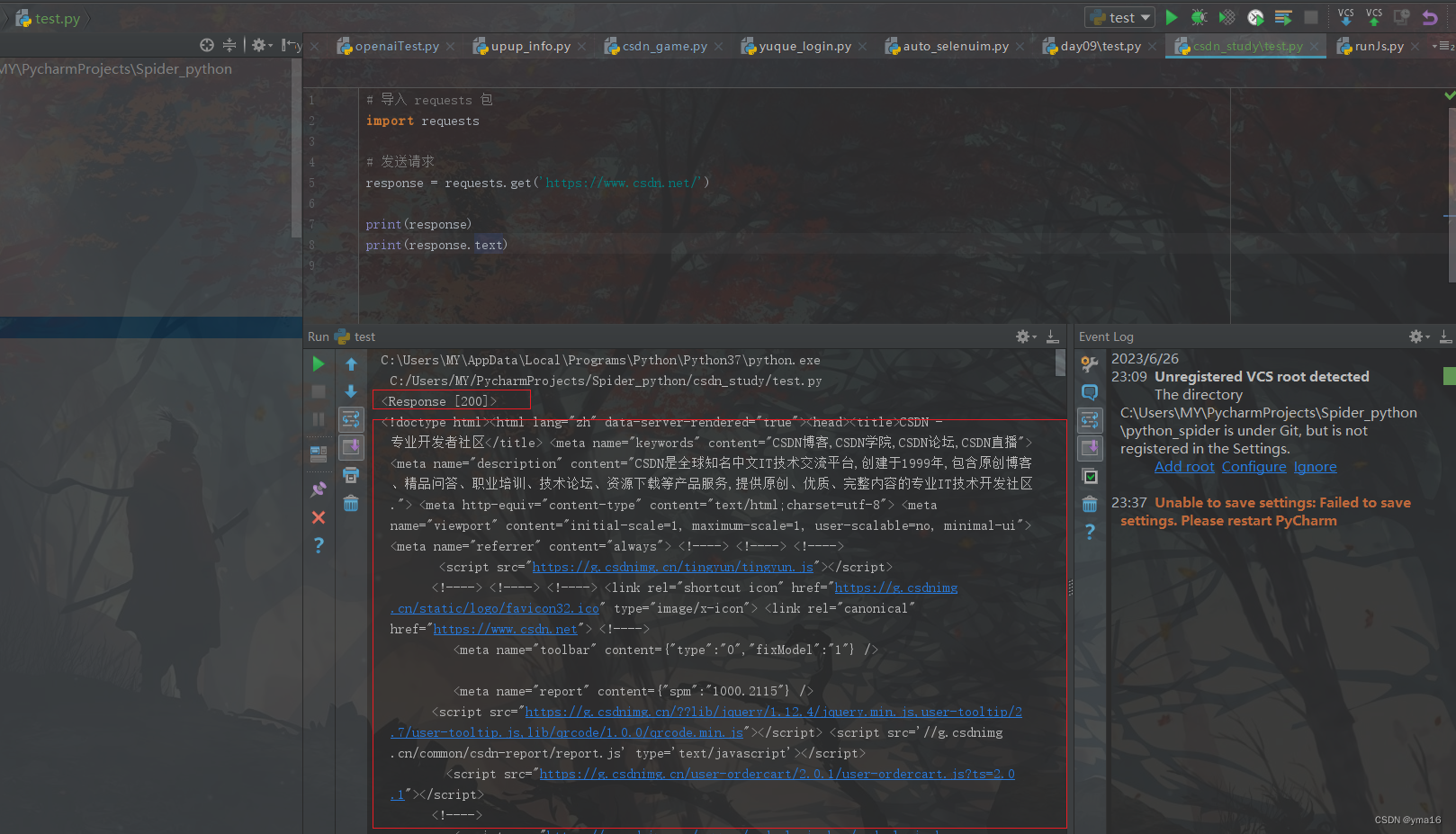
访问 查询CSDN用户
接口:https://so.csdn.net/api/v1/relevant-search
参数
- query {string} 用户名称,如 yma16
- platform {string} 平台,如 PC
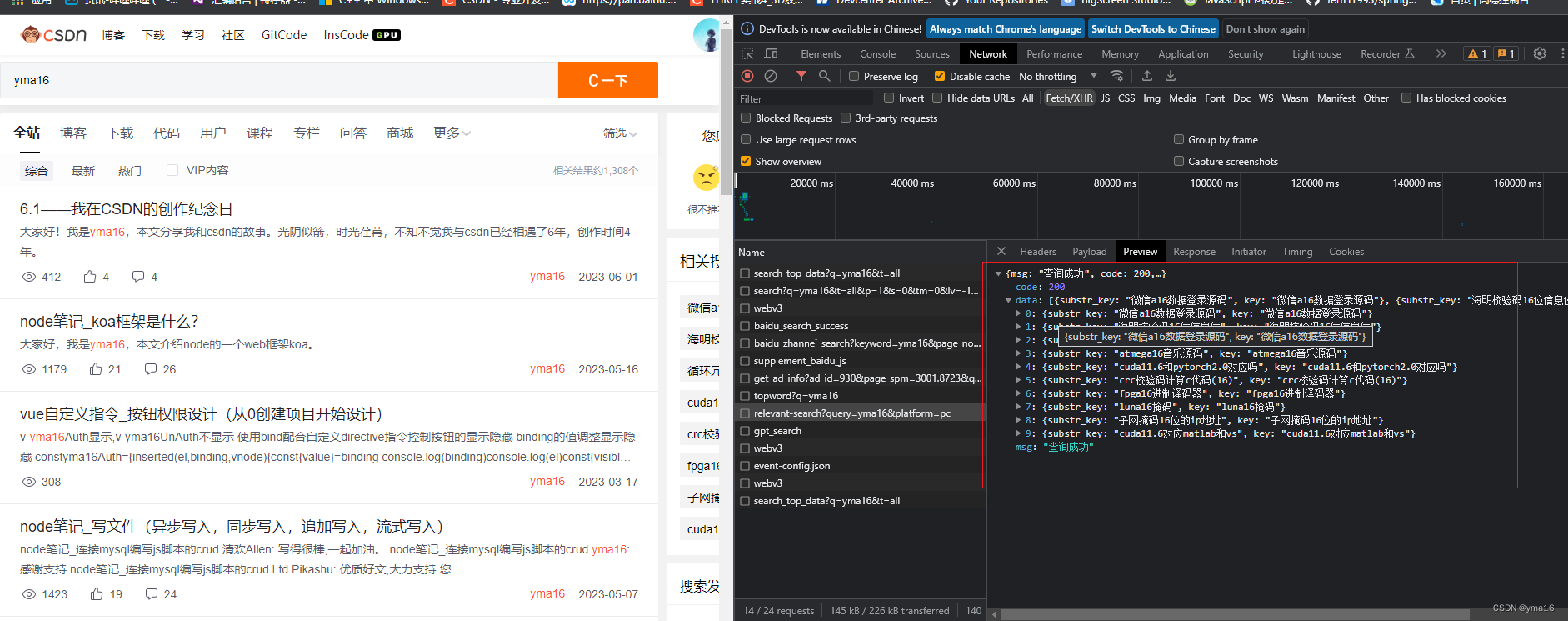
模拟请求查询 名为 yma16的csdn用户
# 导入 requests
import requests
url='https://so.csdn.net/api/v1/relevant-search'
params = {'query':'yma16','platform':'pc'}
# 设置请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
response = requests.get(url=url,params=params,headers=headers)
print(response)
print(response.json())
运行结果:
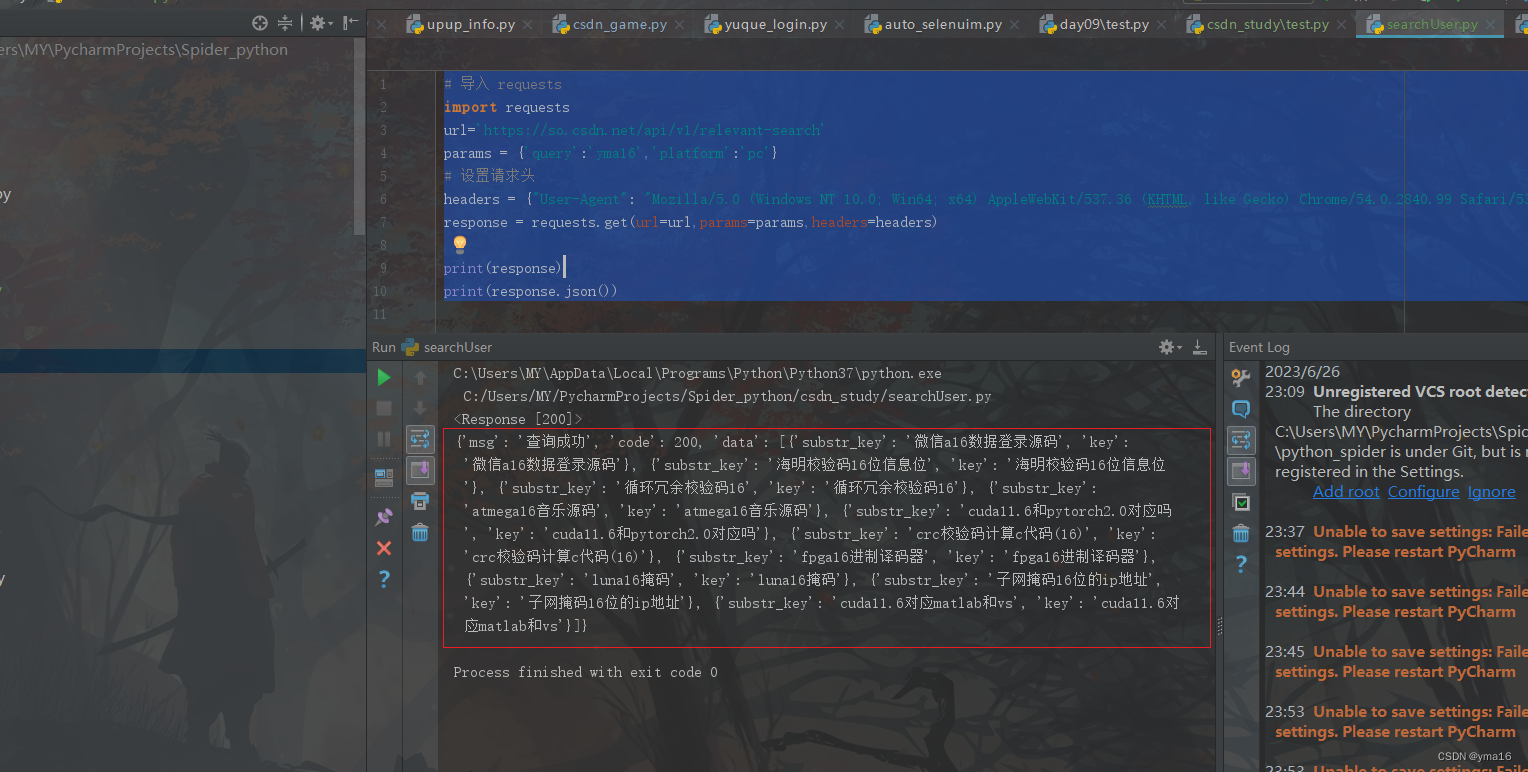
与浏览器中csdn查询一致
💖 requests post
post点赞csdn博客
接口:https://blog.csdn.net//phoenix/web/v1/article/like
参数
- userId 用户id
- articleId 文章id
示例给yma16的博客点赞
注意:需要配置请求头cookie,这里我把cookie放在txt然后读入
# 导入 requests
import requests
# 读取cookie
def readTxtFile():
path='./'
with open(path+'cookie.txt', 'r', encoding='utf-8') as file:
lines = file.read().splitlines() # 读取第一行
return str(lines[0])
# 点赞
def like_articleId(userId,articleId):#传递文章id
requestUrl='https://blog.csdn.net//phoenix/web/v1/article/like'
refererUrl="https://blog.csdn.net/{userId}/article/details/{articleId}"
refererUrl.format(userId=userId,articleId=articleId)
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"cookie": readTxtFile(),
"origin": "https://blog.csdn.net",
"referer": refererUrl
}
data={
'articleId':articleId
}
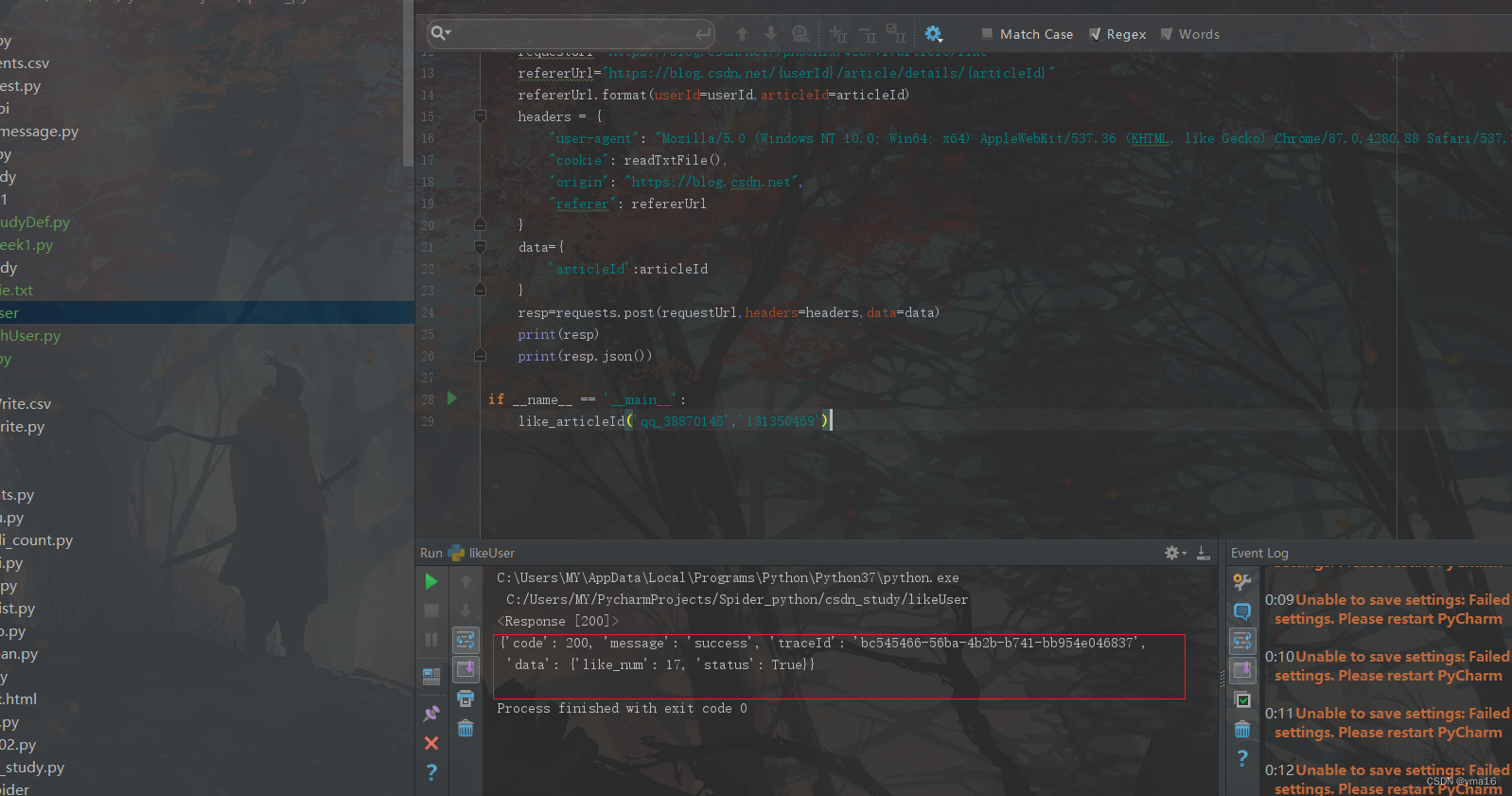
resp=requests.post(requestUrl,headers=headers,data=data)
print(resp)
print(resp.json())
if __name__ == '__main__':
like_articleId('qq_38870145','131350469')
运行结果:
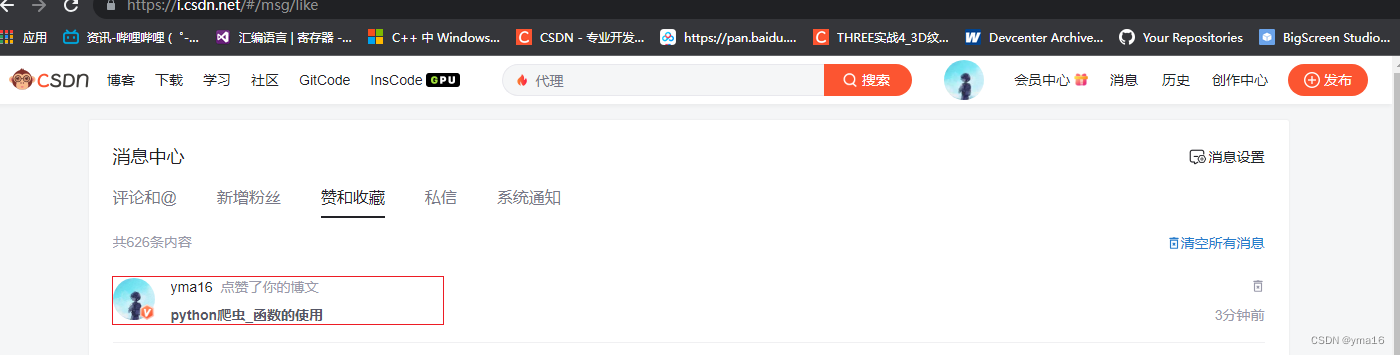
点赞成功:
结束
本文分享python的requests使用到这结束!

👍 点赞,是我创作的动力!
⭐️ 收藏,是我努力的方向!
✏️ 评论,是我进步的财富!
💖 感谢你的阅读!
![shell [[]] 语法错误解决方式](https://img-blog.csdnimg.cn/25c9cda398b54617b80a9e9bfc5c82b8.png)